排序
目录
排序¶
注意
这是一个进阶主题,大多数用户无需担心。
当 Dask 接收到一个需要计算的任务图时,它需要选择一个任务执行顺序。我们有一些约束:依赖项必须在其依赖者之前执行。但除此之外,还有很多选项。我们希望 Dask 选择一种既能最大化并行度,又能最小化计算所需占用空间的顺序。
概括来说,Dask 的策略是 小目标,大步走。
小目标:优先选择总依赖者数量少且其最终依赖者总依赖数量少的任务。
我们优先处理那些有助于快速完成计算分支的任务。
更详细地说,我们计算每个任务所依赖的总依赖数量(包括其自身的依赖、其依赖项的依赖等等),然后选择那些趋向于产生总依赖数量较少结果的任务。我们选择优先完成较短计算的任务。
大步走:优先选择有许多依赖者的任务
然而,许多任务都指向相同的最终依赖者。在这些任务中,我们选择那些剩余工作量最大的任务。我们希望在开始处理较小的子计算部分之前,先完成较大的部分。
这通过 dask.order.order() 完成。更技术性的讨论可在 深入调度 中找到。https://distributed.dask.org.cn/en/latest/scheduling-policies.html 也讨论了调度,重点在于分布式调度器,其中包含此处记录的静态排序之外的额外选择。
调试¶
大多数情况下,Dask 的排序表现良好。但这确实是一个难题,在某些情况下,你可能会观察到意外的高内存使用量或通信开销,这可能是由于排序不佳造成的。本节介绍如何识别排序问题以及可以采取的一些缓解措施。
考虑一个计算过程,它独立地从磁盘加载几条数据链,将它们的部分堆叠在一起,然后进行一些归约操作。
>>> # create data on disk
>>> import dask.array as da
>>> x = da.zeros((12500, 10000), chunks=('10MB', -1))
>>> da.to_zarr(x, 'saved_x1.zarr', overwrite=True)
>>> da.to_zarr(x, 'saved_y1.zarr', overwrite=True)
>>> da.to_zarr(x, 'saved_x2.zarr', overwrite=True)
>>> da.to_zarr(x, 'saved_y2.zarr', overwrite=True)
我们可以加载数据
>>> # load the data.
>>> x1 = da.from_zarr('saved_x1.zarr')
>>> y1 = da.from_zarr('saved_x2.zarr')
>>> x2 = da.from_zarr('saved_y1.zarr')
>>> y2 = da.from_zarr('saved_y2.zarr')
并对其进行一些计算
>>> def evaluate(x1, y1, x2, y2):
... u = da.stack([x1, y1])
... v = da.stack([x2, y2])
... components = [u, v, u ** 2 + v ** 2]
... return [
... abs(c[0] - c[1]).mean(axis=-1)
... for c in components
... ]
>>> results = evaluate(x1, y1, x2, y2)
你可以使用 dask.visualize() 并设置 color="order" 参数,以可视化包含静态排序作为节点标签的任务图。像使用 dask.visualize 通常那样,你可能需要将问题规模缩小,因此我们将切取一部分数据。确保包含 optimize_graph=True 参数,以获得任务实际执行顺序的真实表示。
>>> import dask
>>> n = 125 * 4
>>> dask.visualize(evaluate(x1[:n], y1[:n], x2[:n], y2[:n]),
... optimize_graph=True, color="order",
... cmap="autumn", node_attr={"penwidth": "4"})
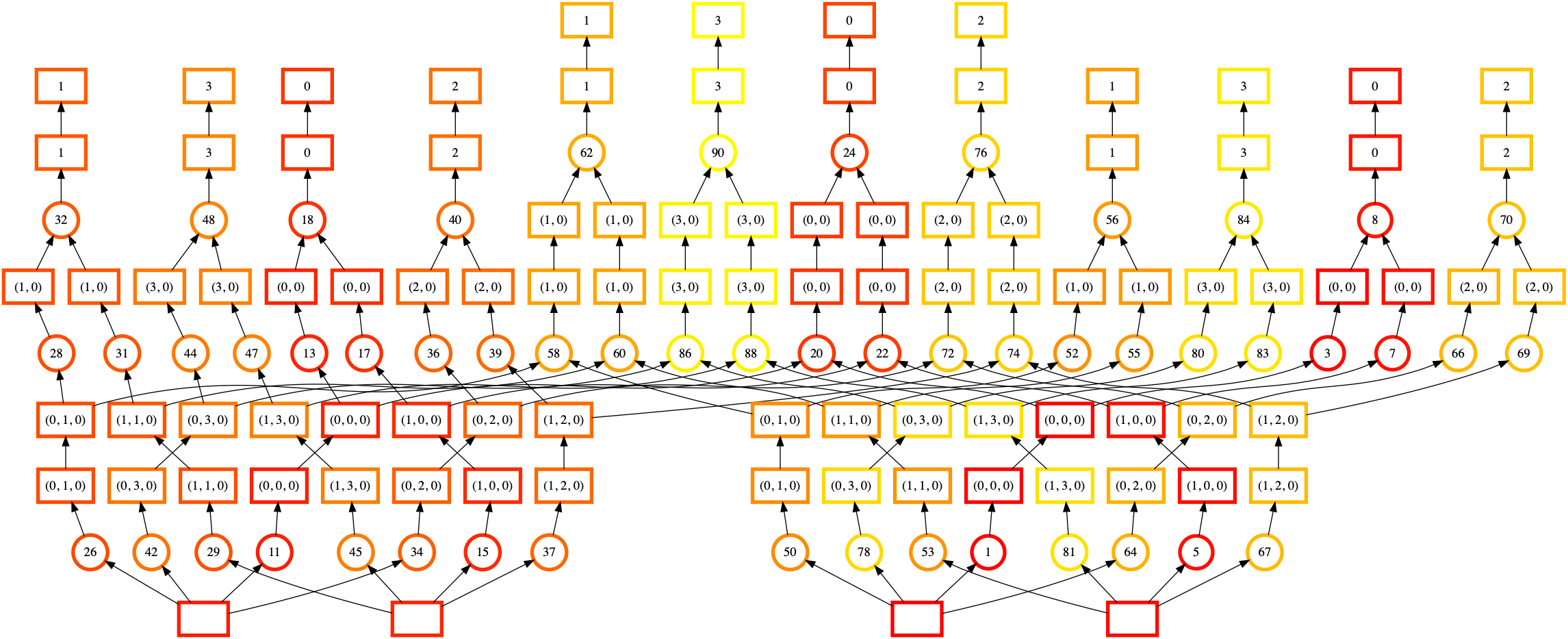
在此可视化图中,节点颜色表示执行顺序(从深红色到浅黄色),节点标签是 Dask 分配给每个任务的顺序。
这有点难以看清,但实际上这里有四个大致独立的执行“塔”。我们从右中部的数组(标签 1,底部)开始,向上移动到右上部(标签 8,右上),然后跳到完全不同的数组(标签 11,左下)。然而,计算第一个塔(标签 8 的下游,右上)需要从我们的第二个输入数组(标签 5,右下)加载一些数据。我们更希望先完成其下游的任务。
当 Dask 执行该任务图时,你可能会观察到高内存使用量。静态排序不佳意味着我们未能完成本可以释放部分数据的任务。我们一次性将更多数据块加载到内存中,从而导致更高的内存使用量。
这个特定的排序失败(可能已修复)来自于每个计算链底部的共享依赖项(每个任务底部的方框,表示输入的 Zarr 数组)。我们可以将它们内联并查看排序的效果。
>>> # load and profile data
>>> x1 = da.from_zarr('saved_x1.zarr', inline_array=True)
>>> y1 = da.from_zarr('saved_x2.zarr', inline_array=True)
>>> x2 = da.from_zarr('saved_y1.zarr', inline_array=True)
>>> y2 = da.from_zarr('saved_y2.zarr', inline_array=True)
>>> import dask
>>> n = 125 * 4
>>> dask.visualize(evaluate(x1[:n], y1[:n], x2[:n], y2[:n]),
... optimize_graph=True, color="order",
... cmap="autumn", node_attr={"penwidth": "4"})
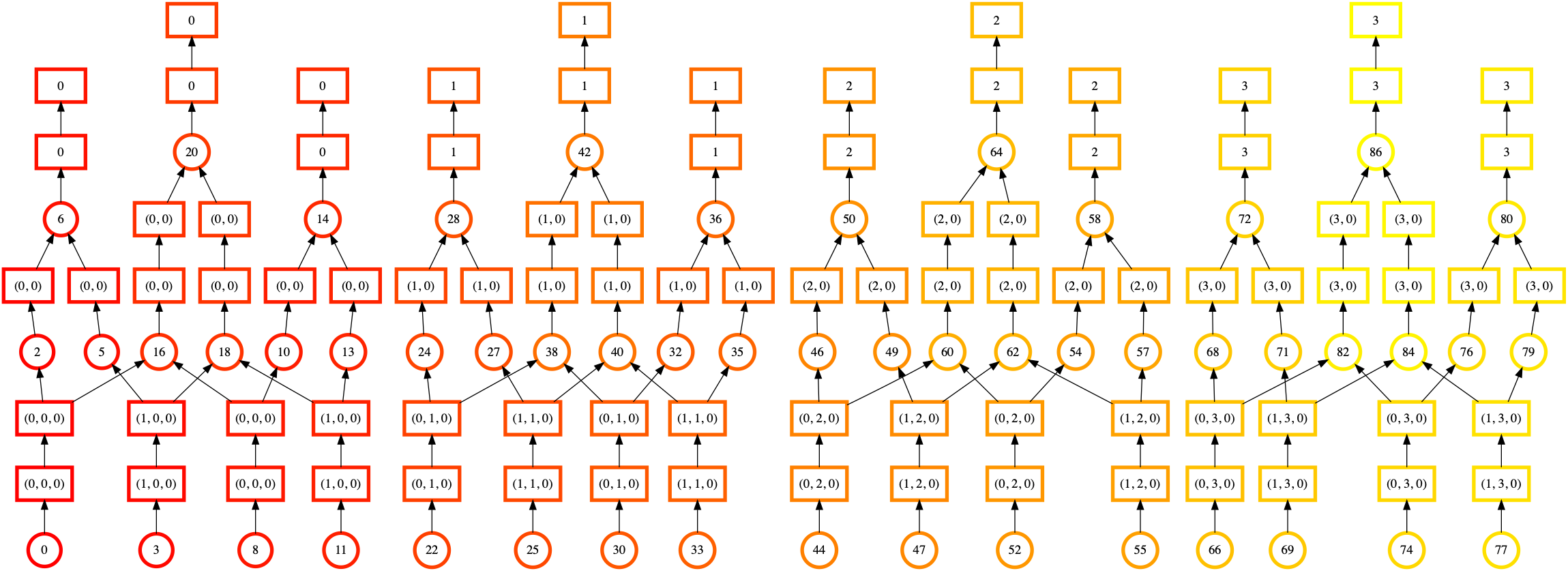
一眼看去,我们可以看到这种排序看起来更加规则和均匀。交叉的线条更少,并且排序的颜色平滑地从下到上、从左到右移动。这表明 Dask 在完成一个计算链后才会继续下一个。
这里的教训不是“始终使用 inline_array=True”。虽然静态排序看起来更好,但还有其他 计算阶段 需要考虑。实际性能是否更好将取决于比我们在此考虑的更多因素。更多信息请参阅 dask.array.from_array()。
相反,这里的经验教训是
哪些症状可能导致你诊断出 Dask 的排序有问题(例如高内存使用量)
如何生成和读取包含 Dask 排序信息的任务图。