更新日志
目录
更新日志¶
注意
此处并非全部变更。有关完整的变更列表,请参阅 git log。
2025.5.0¶
重点¶
修复了当数组和索引器都具有未知形状时 Array
setitem的问题。详情请参阅 dask#11753 (由 Tom Augspurger 提交)。修复了 2025.4.0 版本引入的几个
delayed图处理问题。详情请参阅 dask#11917、dask#11907 和 distributed#9071 (由 Florian Jetter 提交)。
其他变更
加速切片图生成 (dask#11945) Florian Jetter
优化
get_target最坏情况的 dask 排序 (dask#11935) Florian Jetter如果任务缺少依赖项,则在本地执行器上引发错误 (dask#11944) Florian Jetter
修复单分区
to_dask_array问题 (dask#11931) James Bourbeau确保 parquet 计划在优化期间完全缓存 (dask#11933) Florian Jetter
改进表达式系统的文档 (dask#11915) Florian Jetter
简化 (并加速) 剪枝 (dask#11899) Florian Jetter
更新 pre-commit (dask#11926) Florian Jetter
不要在 CI 中运行 post
setup-miniconda步骤 (dask#11925) James Bourbeau尝试为 readthedocs 固定 pip 版本 (dask#11923) Florian Jetter
修复 windows CI (dask#11919) Florian Jetter
为 py310 使用稳定的
crick版本 (distributed#9072) Florian Jetter移除
update_graph中的内部依赖映射 (distributed#9036) Florian Jetter部分遗忘的依赖项 (distributed#9068) Florian Jetter
将 CI 环境中的
filesystem-spec替换为fsspec(distributed#9069) James Bourbeau确保 actor 在 worker 故障时正确设置出错状态 (distributed#9067) Florian Jetter
重构启动集群中的超时处理 (distributed#9062) Florian Jetter
修复客户端 repr 中显示的 workers / threads / memory 问题 (distributed#9066) James Bourbeau
为 readthedocs 固定 pip 版本 (distributed#9063) Florian Jetter
跳过 TLS 功能测试 (distributed#9061) Florian Jetter
确保客户端提交不会不必要地进行序列化 (distributed#9057) Florian Jetter
2025.4.1¶
重点¶
此版本包含针对 2025.4.0 版本中引入的几个图优化问题的修复。
详情请参阅 dask#11906、dask#11898、dask#11903 和 dask#11904 (由 Florian Jetter 提交)。
其他变更
为 array-expr 实现
ufuncs和gufunc(dask#11818) Patrick Hoefler为 array-expr 实现
map_overlap(dask#11822) Patrick Hoefler
2025.4.0¶
重点¶
计算多个由 Dask-Expr 支持的集合(例如 DataFrames)时,它们现在是一起优化,而不是单独优化。
图具现化和低级优化现在在分布式集群的调度器上执行(如果可用)。
DataFrame.shuffle新增关键字参数force,它指示优化器在优化期间不要丢弃 shuffle 操作。作为参数传递给 Dask 方法的集合现在可以被正确优化。如果传递多个集合作为参数,它们将一起优化。以这种方式传递的集合禁止被重复使用,即如果集合在另一个函数调用中再次使用,它将再次计算。这种模式用于避免通常导致内存使用增加的流水线中断。避免这些应该能减少集群上的内存压力,但可能导致运行时性能下降。
(以上一点的特例) 传递给 Delayed 对象的集合现在会自动优化。
破坏性变更¶
移除了对自定义低级优化器的支持。
顶级的
dask.optimize现在将始终触发图具现化。此前并非总是如此。这也导致任何低级 HLG 注解被丢弃。DataFrame 和 Array 的计算结果现在始终在集群上拼接。此前,其行为取决于用于调用 compute 的 API(
dask.compute、DaskCollection.compute或Client.compute)。dask.base.collections_to_dsk已重命名为collections_to_expr,并且不再返回HighLevelGraph或dict对象,而是保证返回一个dask._expr.Expr对象。此外,它不再立即执行低级优化,而是延迟到Expr实例被具现化时,即返回的对象不再是一个映射,因此无法将其转换为dict或对其进行迭代。
其他变更
确保
Future值在da.from_delayed任务图中 (dask#11896) Tom Augspurger修复传递给
delayed的注解 (dask#11893) Florian Jetter迁移
delayed的unpack_collections(dask#11881) Florian Jetter移除文档中关于
Pub/Sub的引用 (dask#11891) James Bourbeau确保只有没有自定义 init 的类是单例 (dask#11886) Florian Jetter
移除
delayed表达式的自定义初始化器 (dask#11888) Florian Jetter修复同时持久化多个 DF 的问题 (dask#11887) Florian Jetter
避免总是将
DataFrame.isin的列表输入解析为对象类型的numpy数组 (dask#11869) Matthew Roeschke取消跳过 pandas-dev
cov/corr测试 (dask#11873) Tom AugspurgerHLG
blockwise修复 (dask#11871) Florian Jetter确保正确生成 HLG 对象的注解 (dask#11866) Florian Jetter
从基础
Expr类中提取单例逻辑 (dask#11868) Florian Jetter确保 HLG 在优化中正确使用依赖项 (dask#11859) Florian Jetter
确保字典以确定性方式进行分词 (tokenize) (dask#11867) Florian Jetter
确保默认 dask 调度器仅计算所需内容 (dask#11861) Florian Jetter
加速
pd.RangeIndex的分词 (tokenize) (dask#11863) Florian Jetter更新社区文档中 Quansight 的链接 (dask#11860) Pavithra Eswaramoorthy
放宽
autocorr测试的容差 (dask#11857) Tom Augspurger在
array.store中使用map_blocks以避免具现化和注解丢失 (dask#11844) Florian Jetter确保
repartition在降低阶段(即在调度器上)不触发内存大小计算 (dask#11855) Florian Jetter支持滚动聚合中的
args和kwargs(dask#11856) Florian Jetter从
upstreamCI 作业中移除 nightlyh5py(dask#11847) James Bourbeau确保
HLGExpr唯一分词 (tokenize) (dask#11849) Florian Jetter在 pandas 3 的 describe 中不注入 median (dask#11846) Florian Jetter
修复子类的
Expr.__setattr__问题 (dask#11845) Tom Augspurger将 HLG 包装在
Expr中以避免客户端具现化 (dask#11736) Florian Jetter改进关闭客户端后提交工作时的错误提示 (distributed#9049) James Bourbeau
地址解析失败时返回默认值 (distributed#9051) Sandro
提交图时避免
deepcopy(distributed#8633) Florian Jetter动态调整心跳和
scheduler_info间隔 (distributed#9046) Florian Jetter通过避免在版本检查时导入包来加快进程启动时间 (distributed#9048) Florian Jetter
减小
scheduler_info的大小 (distributed#9045) Florian Jetter缓存
WorkerState的 host 属性 (distributed#9044) Florian Jetter清除 ci 环境缓存 (distributed#9047) Florian Jetter
移除已弃用的
Pub/Sub(distributed#9039) Florian Jetter仅在提交 LLG 时执行显式剪枝步骤 (distributed#9040) Florian Jetter
不完全根据类型具现化全局注解 (distributed#9035) Florian Jetter
允许嵌套的
worker_client调用 (distributed#9038) George Sakkis转储 ci 缓存 (distributed#9037) Florian Jetter
调度器类型注解 (distributed#9030) Florian Jetter
通过移除
stripped_dep计算来减少dask.order开销 (distributed#9031) Florian Jetter使用
Expr代替 HLG (distributed#9008) Florian Jetter
2025.3.0¶
重点¶
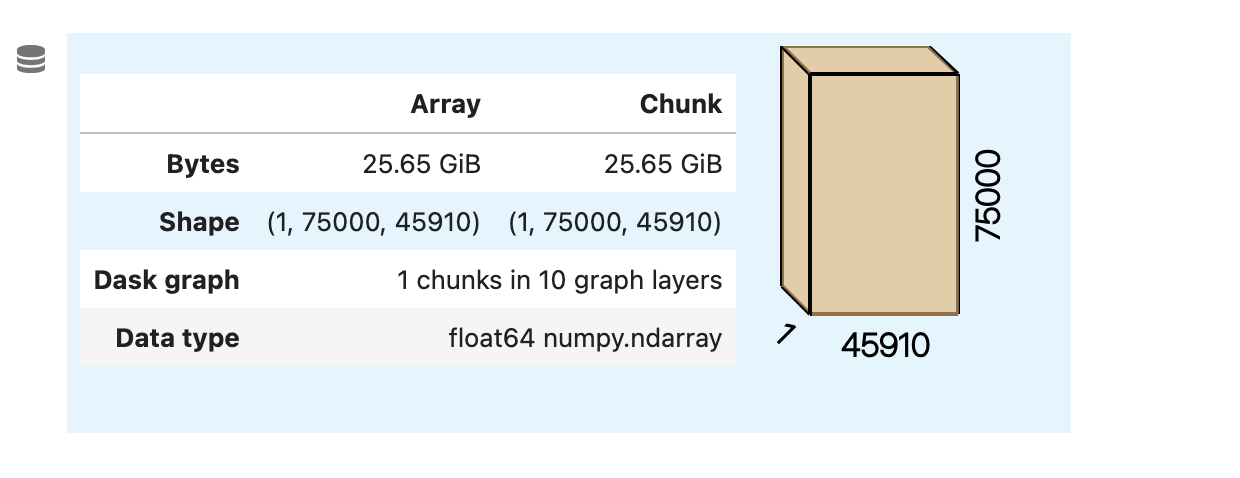
在 xarray.apply_ufunc 中自动调整块大小¶
apply_ufunc 要求核心维度具有 chunksize=-1。底层的 rechunking 操作会自动调整核心维度的块大小,但保持其他维度不变。这可能导致底层块大小爆炸。
此版本增加了一个中间步骤,该步骤会以核心维度增加的相同因子调整非核心维度的大小,以控制最大块大小。当设置 allow_rechunk=True 时,此行为自动启用。
import xarray as xr
import dask.array as da
arr = xr.DataArray(
da.random.random((1, 750, 45910), chunks=(1, "auto", -1)),
dims=["band", "y", "x"],
)
result = arr.interp(
y=arr.coords["y"],
method="linear",
)
此前
单个块大小爆炸到 25 GiB,很可能导致内存不足错误。
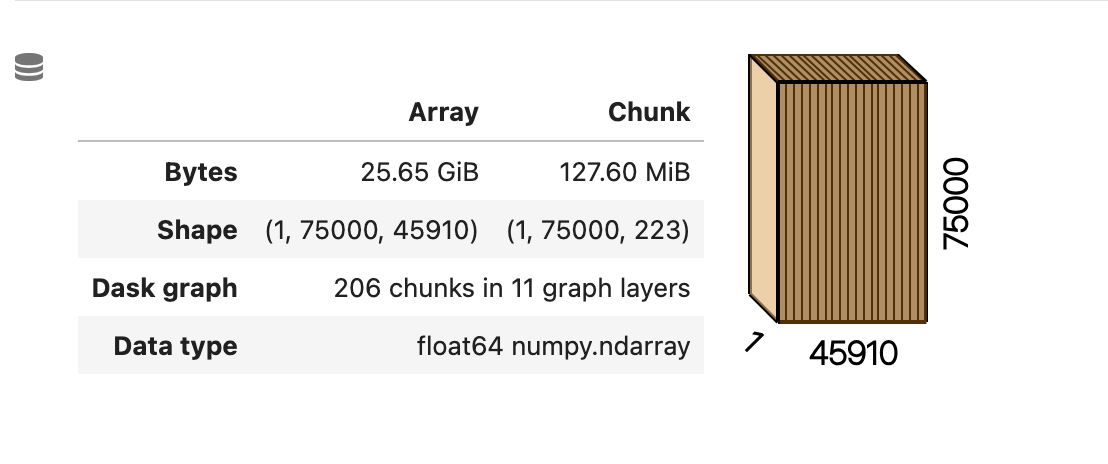
现在
Dask 现在会自动将单个块拆分为具有相同块大小减去少量容差的块。
其他变更
修复数据集信息缓存分配 (dask#11840) Florian Jetter
Expr
setattr(dask#11836) Florian Jetter表达式分词 (tokenize) 缓存的跟进 (dask#11837) Florian Jetter
整合 expr 类的
getattr(dask#11835) Florian Jetter减小
ReadParquet表达式的 pickle 大小 (dask#11797) Florian Jetterarange在~2**63处丢失精度 (dask#11801) Guido Imperiale从 upstream 构建中移除
numbagg(dask#11821) Patrick Hoefler将
nanmedian和nanquantile分派到numbagg(dask#11817) Patrick Hoefler使缺少
meta的警告更人性化 (dask#11814) Patrick Hoefler从
from_pandas中移除name文档 (dask#11812) Patrick Hoefler实现 Array Scalar (dask#11810) Patrick Hoefler
将
to_orc添加到 DataFrame API (dask#11807) Tom Augspurger为 DataFrames 实现反向索引 (dask#11803) Patrick Hoefler
为
cudf添加延迟的to_pandas_dispatch注册 (dask#11799) Richard (Rick) Zamora修复 array-expr 中缺失的导入 (dask#11796) Florian Jetter
缓存表达式上的 tokens 并在 pickle 往返后恢复 (dask#11791) Florian Jetter
在分布式测试中使用随机 dashboard 端口进行
LocalCluster(dask#11795) Florian Jetter为 array-expr 实现切片 (slicing) (dask#11783) Patrick Hoefler
调用顶级 compute 函数时,永远不要使用异步的
Client(dask#11790) Florian Jetter重构导入测试 (dask#11794) Florian Jetter
将
base.unpack_collections迁移到Task类 (dask#11793) Florian Jetter确保
map_blocks生成唯一的 tokens (dask#11792) Florian Jetter将
normalize_pickle的运行时加快 50% (dask#11788) Florian Jetter修复包含重复项的 divisions 计算问题 (dask#11787) Patrick Hoefler
修复重复 divisions 的 assign align 问题 (dask#11786) Patrick Hoefler
确保 concat optimize project 不会抛出异常 (dask#11784) Florian Jetter
添加 array-expr from_array (dask#11772) Patrick Hoefler
在
apply_gufunc中保持 chunksizes 一致 (dask#11683) Patrick Hoefler测试
dask.dataframe.__all__(dask#11782) Philipp A.为
dask.bag添加__all__(dask#11781) Philipp A.为
dask.array.__all__添加测试 (dask#11780) Philipp A.将
JamesIves/github-pages-deploy-action从 4.7.2 升级到 4.7.3 (dask#11777)导出
dask.array成员 (dask#11779) Philipp A.修复
sorted_divisions_locations包含重复项的问题 (dask#11773) Tom Augspurger修复
best-practices.rst中的小拼写错误 (dask#11775) Sergey Kolesnikov允许
blockwiseadjust_chunks中的未知块 (dask#11769) Lindsey Gray修复
asarray(..., like=...)与scipy.sparse对象冲突导致崩溃的问题 (dask#11755) Guido Imperiale移除不稳定的可选依赖项 (dask#11771) Tom Augspurger
添加对 scipy sparray 的支持 (dask#11750) Philipp A.
将
flaky添加到测试 extra (dask#11770) Tom Augspurger确保 divisions 是普通标量 (dask#11767) Tom Augspurger
移除 divisions 代码重复 (dask#11764) Florian Jetter
确保 Merge 中 divisions 不与
npartitions分歧 (dask#11762) Florian Jetter在 windows 上跳过
test_visualize_int_overflow(dask#11761) Florian Jetter减小 tasks 的 pickle 大小 (dask#11687) Florian Jetter
实现
unify_chunks和 Rechunk (dask#11692) Patrick Hoefler修复 expression getitem 以避免对齐问题 (dask#11760) Patrick Hoefler
arange(..., like=x)嵌入了 x 的图 (dask#11754) Guido Imperiale简化
assert_divisions(dask#11745) Florian Jetter修复 Series 对象的 Projection 逻辑 (dask#11747) Patrick Hoefler
移除以 bytes 作为 keys 的用法 (dask#11757) Florian Jetter
确保如果函数返回标量,
map_partitions返回 Series 对象 (dask#11756) Florian Jetter不上传 env 两次 (dask#11748) Patrick Hoefler
修复 readme 中的 badges (distributed#9029) Florian Jetter
正确转发取消原因 (distributed#9028) Florian Jetter
修复
bokehcircle (distributed#9026) Florian Jetter确保
FileInfo可以序列化 (distributed#9025) Florian Jetter在代码采样中将 ipykernel 添加到跳过的模块 (distributed#9022) Matthew Rocklin
SpecCluster: 添加一个选项,以便在集群关闭时 *不* 关闭调度器 (distributed#9021) Taylor Braun-Jones
通过使用
client.persist(collection)而不是collection.persist()来修复 CI (distributed#9020) Hendrik Makait添加从前缀根到 status 的重定向 (distributed#9015) Isaac
将
JamesIves/github-pages-deploy-action从 4.7.2 升级到 4.7.3 (distributed#9018)移除测试中的 bytes keys (distributed#9017) Jacob Tomlinson
2025.2.0¶
重点¶
此版本包含一个关键修复,解决了当 seceded 任务被重新调度或取消并重新提交时(例如由于 worker 丢失)可能出现的死锁问题。
更多详细信息请参阅 distributed#8991 by Hendrik Makait。
其他变更
添加大数组示例 (dask#11744) James Bourbeau
修复 pad 在常量填充时块大小爆炸的问题 (dask#11743) Patrick Hoefler
将 optimize 方法移至基类 (dask#11742) Florian Jetter
为修复的死锁添加 changelog 条目 (dask#11741) Hendrik Makait
修复
dask-exprto_delayed中图创建问题 (dask#11739) Patrick Hoefler从 delayed 优化中移除剪枝 (culling) (dask#11737) Patrick Hoefler
在集群上计算 from_map 的 meta (dask#11738) Patrick Hoefler
使用 dask 布尔掩码时
__setitem__的 bug (dask#11728) Guido Imperiale实现 infrastructure, random, blockwise 和 Elemwise (dask#11689) Patrick Hoefler
array/asarray同时使用like=和dtype=的问题 (dask#11733) Guido Imperiale修复注解警告测试 (dask#11734) Patrick Hoefler
使用 to_parquet 写入远程存储时捕获警告 (dask#11731) Patrick Hoefler
从测试中移除 LocalCluster (dask#11729) Patrick Hoefler
修复使用 from_array 时分区剪枝 (pruning) 的问题 (dask#11725) Patrick Hoefler
修复混合 dtype 列的拼接问题 (dask#11727) Patrick Hoefler
arange: 修复极端值问题 (dask#11707) Guido Imperiale标量
getitem->setitem导致图损坏 (dask#11723) Guido Imperialecompute() 后永不共享缓冲区 (dask#11697) Guido Imperiale
在 from_array 中从 xarray DataArray 提取 Dask Array (dask#11712) Patrick Hoefler
arange: 支持 kwargs (dask#11710) Guido Imperiale确保
normalize_token是线程安全的 (dask#11709) Florian Jetter扩展关于实例类型和进程的建议 (dask#11705) Florian Jetter
删除遗留的时间序列实现 (dask#11704) Florian Jetter
更新 Dask Cloud Provider 文档,将 Nebius 包含为支持的云选项 (dask#11703) Alexander
修复
normalize_chunks在压平到单个 chunk 时的问题 (dask#11702) Patrick Hoefler修复带
newaxis的位置索引问题 (dask#11699) Patrick Hoefler在 scipy-sparse-indexing 中设置 array 后端 (dask#11700) Tom Augspurger
修复
value_countsshuffle 策略 (dask#11698) Patrick Hoefler将核心 expression 类与 dataframe 特定代码解耦 (dask#11688) Patrick Hoefler
将
conda-incubator/setup-miniconda从 3.1.0 升级到 3.1.1 (dask#11685)修正从 array 方法转换 dataframe 的问题 (dask#11684) Patrick Hoefler
移除
fastparquet的剩余痕迹 (dask#11682) Patrick Hoefler移除
sizeof失败警告中的追溯信息 (distributed#9006) Jacob TomlinsonHotfix: 忽略负数 occupancy (distributed#9012) Hendrik Makait
移除昂贵的 tokenization 以进行 key 唯一性检查 (distributed#9009) Patrick Hoefler
修复
from_map更改后的 CI (distributed#9011) Patrick Hoefler避免在调度器上处理过期的长时间运行消息 (distributed#8991) Hendrik Makait
增加
test_stress超时时间 (distributed#9002) Tom Augspurger在
test_rmm_metrics测试中进行轮询 (distributed#9004) Tom Augspurger在
WorkStealing.balance()中缓存 occupancy (distributed#9005) Hendrik Makait通过考虑进行中的请求实现同质平衡 (distributed#9003) Hendrik Makait
在 stealing、adaptive 和 occupancy 计算之间保持任务持续时间估计一致 (distributed#9000) Hendrik Makait
将默认 work-stealing 间隔增加 10 倍 (distributed#8997) Hendrik Makait
从 status dashboard 中移除 occupancy 图表 (distributed#8995) Hendrik Makait
将
conda-incubator/setup-miniconda从 3.1.0 升级到 3.1.1 (distributed#8990)
2025.1.0¶
重点¶
移除了遗留的 Dask DataFrame 实现¶
此版本移除了遗留的 Dask DataFrame 实现。带查询规划的 API 现在是唯一的 Dask DataFrame 实现。
这强制执行了配置的弃用
dask.config.set({"dataframe.query-planning": False})
Dask-Expr 已合并到 dask 包以及 dask/dask 仓库中。不再需要单独安装 dask-expr。
减少 Xarray 工作负载的内存压力¶
Dask 在 2022 年引入了一种称为 根任务排队(root task queuing) 的机制。该机制允许 Dask 检测从存储中读取数据的任务,并防御性地调度它们,以避免通过过度生产这些任务而给集群带来内存压力。底层的机制非常脆弱,对于特定类型的计算(例如打开多个 zarr 存储或加载大量 netcdf 文件)会失败。
Dask 任务图表示的最新更改使得根任务的检测更加鲁棒。此更改使得检测机制独立于运行的工作负载,并且尤其有益于 Xarray 工作负载。
这显著提高了内存稳定性,并减少了此前根任务检测失败的工作负载的内存占用,使得预期的内存配置文件具有确定性且独立于任务图的拓扑结构。
2024.12.1¶
重点¶
提高了调度器对大型任务图的响应能力¶
此版本减少了 Dask 调度器用于跟踪任务的 Python 对象引用数量。这通过减少调度器运行垃圾回收所需的时间来提高调度器的响应能力。
更多详细信息请参阅 dask#8958, dask#11608, dask#11600, dask#11598, dask#11597, 和 distributed#8963 by Hendrik Makait。
其他变更
修复了
map_overlaprechunking 和trim=False导致 chunks 不一致的 bug (dask#11605) Patrick Hoefler在 read-csv 中避免遗留实现 (dask#11603) Patrick Hoefler
移除遗留 DataFrame 导入 (dask#11604) Patrick Hoefler
asarray忽略 array 输入的dtype(dask#11586) crusaderky将 LLM 聊天机器人重新添加回 Dask 文档 (dask#11594) dchudz
将
JamesIves/github-pages-deploy-action从 4.6.9 升级到 4.7.2 (dask#11593)将 dask array 创建例程迁移到任务规范 (task spec) (dask#11582) James Bourbeau
将大部分 dask array random 迁移到任务规范 (task spec) (dask#11581) James Bourbeau
在
array.push中不使用本地函数 (dask#11576) Florian Jetter将
conda-incubator/setup-miniconda从 3.0.3 升级到 3.1.0 (distributed#8922)在测试中选取随机的 dashboard 端口 (distributed#8965) Hendrik Makait
修复
NoValidWorkerException消息的格式问题 (distributed#8967) Hendrik Makait在 WSL 中支持
pynvml>=11.5(distributed#8962) Richard (Rick) Zamora将
JamesIves/github-pages-deploy-action从 4.6.9 升级到 4.7.2 (distributed#8960)
2024.12.0¶
重点¶
支持 Python 3.13¶
此版本新增对 Python 3.13 的支持。Dask 现在支持 Python 3.10-3.13。
更多详细信息请参阅 dask#11456 和 distributed#8904 by Patrick Hoefler 和 James Bourbeau。
其他变更
恢复“添加 LLM 聊天机器人到 Dask 文档 (dask#11556)” (dask#11577) dchudz
如果
to_zarr中的数组具有不规则块,则自动进行 rechunking (dask#11553) Patrick HoeflerBlockwise 使用
Task类 (dask#11568) Florian Jetter将
rechunk和reshape迁移到 task spec (dask#11555) Patrick Hoefler缓存数组的 svg-表示 (dask#11560) Deepak Cherian
修复容器的空输入问题 (dask#11571) Florian Jetter
在优化期间将
Bag图转换为TaskSpec图 (dask#11569) Florian Jetter添加 LLM 聊天机器人到 Dask 文档 (dask#11556) dchudz
在线性融合中也融合数据节点 (dask#11549) Patrick Hoefler
将切片代码迁移到 task spec (dask#11548) Patrick Hoefler
加快
ArraySliceDep的 tokenization (dask#11551) Patrick Hoefler修复
p2pbarrier 任务的融合问题 (dask#11543) Patrick Hoefler移除 GPU CI 的基础设施/提及 (dask#11546) Charles Blackmon-Luca
暂时禁用 gpuCI 更新 CI 作业 (dask#11545) James Bourbeau
使用
BlockwiseDep实现map_blocks关键字参数 (dask#11542) Patrick Hoefler移除
optimize_slices(dask#11538) Patrick Hoefler如果形状相同,将
reshape_blockwise设为无操作 (noop) (dask#11541) Patrick Hoefler移除
open_zarr中open_arry的只读标志 (dask#11539) Patrick Hoefler为 task spec 类实现
linear_fusion(dask#11525) Patrick Hoefler移除
TaskSpec中的递归 (dask#11477) Florian Jetter修正 dask-expr 更改后的测试 (dask#11536) Patrick Hoefler
将
codecov/codecov-action从 3 升级到 5 (dask#11532)直接创建 dask-expr frame 而无需 roundtripping (dask#11529) Patrick Hoefler
将
scikit-imagenightly 重新添加到 upstream CI (dask#11530) James Bourbeau移除
from_dask_dataframe导入 (dask#11528) Patrick Hoefler确保
from_array创建一个副本 (dask#11524) Patrick Hoefler简化并提高 normalize chunks 的性能 (dask#11521) Patrick Hoefler
修复不稳定的
nanquantile测试 (dask#11518) Patrick Hoefler修复 zarr=3 中新的
read_onlykwarg 导致的测试问题 (dask#11516) Patrick Hoefler修复
test_jupyter.py::test_shutsdown_cleanly(distributed#8954) Hendrik Makait在 Python 3.13 CI 中从
conda-forge安装tornado(distributed#8951) James Bourbeau恢复 retire workers API (distributed#8939) Florian Jetter
正确将 finalize 依赖项转换为引用 (distributed#8949) Hendrik Makait
barrier 任务的 Block fusion (distributed#8944) Patrick Hoefler
移除 GPUCI 的基础设施/提及 (distributed#8946) Charles Blackmon-Luca
暂时禁用 gpuCI 更新 CI 作业 (distributed#8945) James Bourbeau
移除 task spec 中的递归 (distributed#8920) Florian Jetter
减少 remove 和 register worker 的日志消息详细程度 (distributed#8938) Florian Jetter
在
retire_workers中不记录完整的 worker 信息 (distributed#8935) Florian Jetter
2024.11.2¶
注意
版本 2024.11.0 和 2024.11.1 包含一个关键的性能回归问题,所有用户都应跳过这两个版本。
重点¶
遗留 Dask DataFrame 已弃用¶
此版本弃用了遗留的 Dask DataFrame 实现。旧的实现将在未来的版本中完全移除。鼓励用户现在切换到新的实现,并报告遇到的任何问题。
也鼓励用户检查他们只从 dask.dataframe 导入函数,而不是任何子模块。
Dask Array API 新增 quantile 方法¶
Dask Array 新增了 quantile 和 nanquantile 方法。此前,Dask 分派给 NumPy 实现,这会大量阻塞 GIL。这导致 worker 在拥有多个线程时出现严重 slowdown,并且可能导致每个 chunk 的运行时超过 200 秒。
新的 quantile 实现避免了许多这些问题,并将运行时减少到每个 chunk 大约 1 秒,且与线程数量无关。
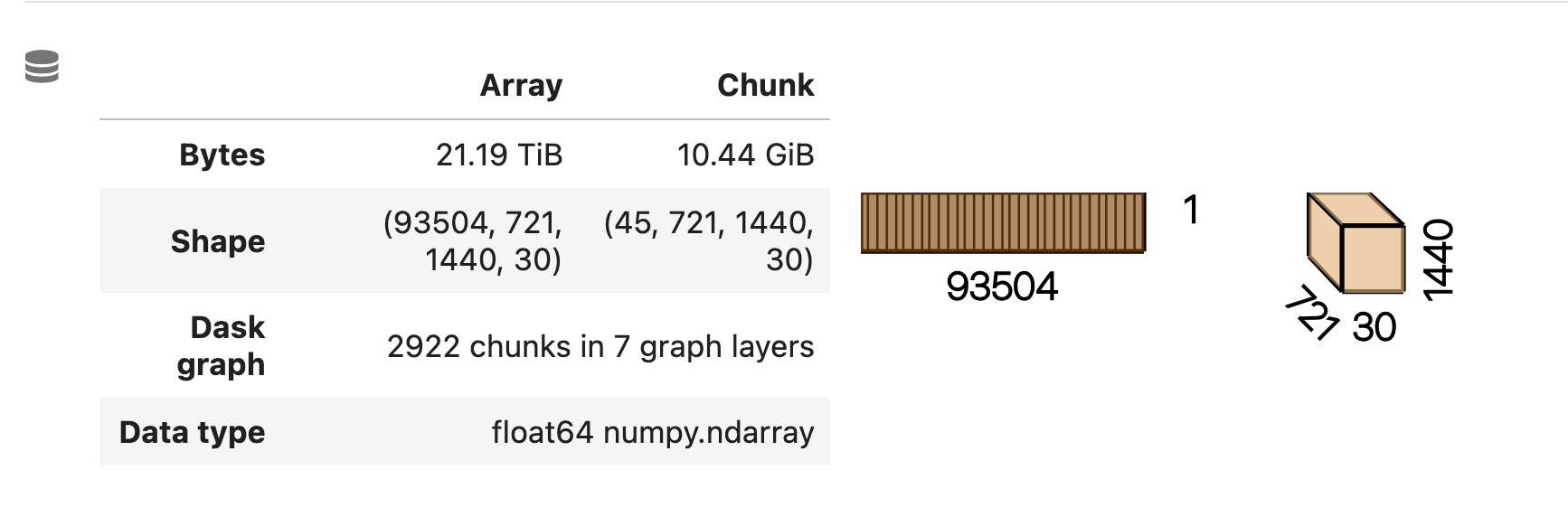
Xarray rolling-construct 中一致的块大小¶
在 Dask Arrays 中使用 Xarrays rolling(...).construct(...) 会导致非常大的块大小,这些块大小通常不适合单个 worker 的内存。
底层操作是对较小的 NumPy 数组的视图,但触发数据复制将导致非常大的内存使用。
import xarray as xr
import dask.array as da
arr = xr.DataArray(
da.ones((93504, 721, 1440), chunks=("auto", -1, -1)),
dims=["time", "lat", "longitude"],
) # Initial chunks are ~128 MiB
arr.rolling(time=30).construct("window_dim")
此前
单个块大小爆炸到 10 GiB,很可能导致内存不足错误。
现在
Dask 现在会自动将单个块拆分为具有相同块大小减去少量容差的块。

提高了 map overlap 的效率¶
map_overlap 现在创建更小、更高效的图,以保持任务图整体小得多。
旧版本注入了许多不必要的任务,将任务数量增加了实际所需数量的 2-10 倍。这对调度器造成了很大压力。
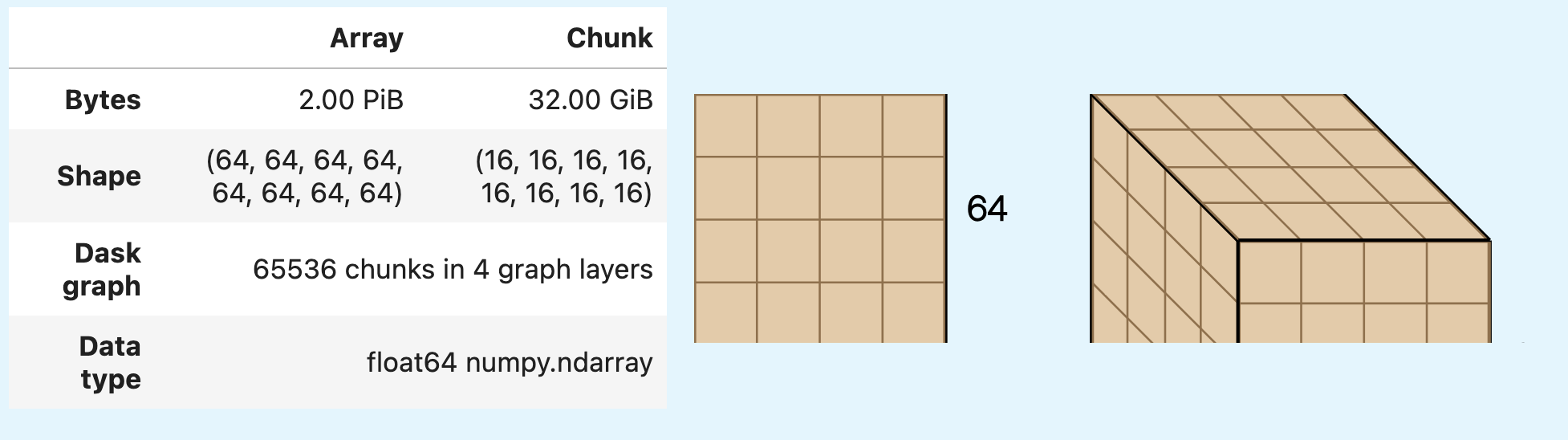
爱因斯坦求和 (Einstein summation) 的一致块大小¶
如果应用于多个 Dask Array,爱因斯坦求和此前会导致非常大的块大小。此行为继承自 NumPy,但导致 worker 上出现内存不足错误。
import dask.array as da
arr = da.random.random((1024, 64, 64, 64, 64), chunks=(256, 16, 16, 16, 16)) # Initial chunks are 128 MiB
result = da.einsum("aijkl,amnop->ijklmnop", arr, arr)
此前
单个块大小爆炸到 32 GiB,很可能导致内存不足错误。
现在
该操作保持单个块大小不变。
其他变更
为 Dask 发布添加 changelog (dask#11502) Patrick Hoefler
可选依赖表的小幅更新 (dask#11503) James Bourbeau
为类似
ffill的操作添加push(dask#11501) Patrick Hoefler移除
TaskSpec的func打包 (dask#11496) Florian Jetter使
vindex的 tokenization 更高效 (dask#11493) Patrick Hoefler缩短 einstein summation 测试的运行时 (dask#11499) Patrick Hoefler
改进
test_rot90的测试运行时 (dask#11498) Florian Jetter禁用 Bags 中
TaskSpec的低级优化 (dask#11495) Florian Jetter为 sliding-window-view 添加自动 rechunking (dask#11479) Patrick Hoefler
为
dask.array.store添加load_storedkwarg (dask#11465) Deepak Cherian修复二维
quantile错误 (dask#11489) Patrick Hoefler将
conda-incubator/setup-miniconda从 3.0.4 升级到 3.1.0 (dask#11490)更新
map_blocksdocstring (dask#11491) Patrick Hoefler修复带空数组的
einsum问题 (dask#11488) Patrick Hoefler实现不阻塞 gil 的
quantile方法 (dask#11473) Patrick Hoefler在
map_overlap中使用内部关键字参数进行修剪,以减小图的大小 (dask#11486) Patrick Hoefler小幅重构 dask
order(dask#11467) Florian Jetter从
map_overlap中移除空任务 (dask#11483) Patrick Hoefler修复 auto chunks 计算,如果单个 chunk 小于 1 (dask#11485) Patrick Hoefler
修复 pandas upstream 更改后的 CI (dask#11482) Patrick Hoefler
确保
block_id和block_info不会创建额外的任务 (dask#11484) Patrick Hoefler使用 repeat 构建最近的边界 (dask#9666) Jean-Baptiste Bayle
移除
make_blockwise中的死代码 (dask#11478) Florian Jetter修补
rioxarray的 auto-chunks 计算问题 (dask#11480) Patrick Hoefler由于警告不稳定,跳过 legacy test (dask#11475) Patrick Hoefler
取消跳过一些
dask-expr测试 (dask#11474) Patrick Hoefler在
einsum中保持块大小一致 (dask#11464) Patrick Hoefler改进设置“auto”时
normalize_chunks合并块的方式 (dask#11468) Patrick Hoefler修复图中存在多个别名时
resolve_aliases的问题 (dask#11469) Patrick Hoefler避免
dask.array中的循环导入 (dask#11472) Hendrik Makait恢复跳过的 dataframe 测试 (dask#11471) Patrick Hoefler
改进大型图的
dask.order性能 (dask#11466) Florian Jetter确保
slice(None)只映射键 (dask#11450) Patrick Hoefler修复未反序列化对象的
Task.__repr__()(dask#11463) Peter Andreas Entschev在本地 dask 执行中使用
TaskSpec(dask#11378) Florian Jetter调整
test_solve_triangular_vector中的精度 (dask#11461) Florian Jetter更新 Aggregation docstring (dask#11459) Guillaume Eynard-Bontemps
实现
delayed对象的 fuse 选项 (dask#11441) Patrick Hoefler废弃旧版 dask dataframe 实现 (dask#11437) Patrick Hoefler
修复
groupby.agg使用 arrow dtypes 时的na转换行为 (dask#11118) Patrick Hoefler修复
TaskSpec节点的keys_in_tasks行为 (dask#11445) Florian Jetter在可视化大型任务图时,将 dtype 转换为 int 而不是 np.uint8 (dask#11440) Patrick Hoefler
确保依赖不被修改 (dask#11438) Florian Jetter
dask.order完全支持 task spec (dask#11347) Florian Jetter移除
P2PBarrierTask中的冗余方法 (distributed#8924) Florian Jetter修复
test_tell_workers_when_peers_have_left的skipif条件 (distributed#8929) Florian Jetter确保
ConnectionPool被关闭,即使网络栈吞噬了CancelledErrors(distributed#8928) Florian Jetter修复不稳定的
test_server_comms_mark_active_handlers(distributed#8927) Florian Jetter明确 P2P 屏障机制中的假设 (distributed#8926) Hendrik Makait
调整 Jupyter cli 测试中的超时时间 (distributed#8925) Florian Jetter
向
update_graph插件钩子添加stimulus_id(distributed#8923) Hendrik Makait减少 P2P 传输任务开销 (distributed#8912) Hendrik Makait
在 Python 3.11 上禁用 profiler (distributed#8916) Florian Jetter
修复
test_restarting_does_not_deadlock(distributed#8849) Florian Jetter调整
popen测试超时时间 (distributed#8848) Florian Jetter向 shuffle 广播添加重试 (distributed#8900) Florian Jetter
修复
test_shuffle_with_array_conversion(distributed#8909) Florian Jetter重构部分测试 (distributed#8908) Florian Jetter
将
dask-expr从 contrib 升级到核心项目 (distributed#8911) Hendrik Makait在 py10 上跳过
test_tell_workers_when_peers_have_left(distributed#8910) Florian JetterP2P 代码内部清理 (distributed#8907) Hendrik Makait
使用
Task类而不是 tuple (distributed#8797) Florian Jetter增加
test_tell_workers_when_peers_have_left的连接超时 (distributed#8906) Florian Jetter移除
TaskCollection中的调度 (distributed#8903) Florian Jetter在 P2P 中对 scheduler 的请求去重 (distributed#8899) Hendrik Makait
添加 rootish taskgroup 阈值的配置 (distributed#8898) Patrick Hoefler
2024.10.0¶
显著变化¶
Zarr-Python 3 兼容性 (dask#11388)
避免在 overlap 中任务图呈指数增长 (dask#11423)
确保 numba tokenization 不使用慢速 pickle 路径 (dask#11419)
其他变更
确保
broadcast_shapes()返回整数,而不是 NumPy scalar。 (dask#11434) Martin Yeo(修复): 稀疏索引 (dask#11430) Ilan Gold
确保递归调用 tokenize 时遵守 ensure_deterministic (dask#11431) Florian Jetter
使 P2P 更具可配置性 (distributed#8469) Hendrik Makait
仪表盘工作表适应页面宽度 (distributed#8897) Jacob Tomlinson
使用错误的插件基类时引发有帮助的错误 (distributed#8893) Jacob Tomlinson
修复异常仪表盘中非字符串键的 url 转义问题 (distributed#8891) Patrick Hoefler
在写入期间磁盘空间不足异常时添加有意义的错误信息 (distributed#8886) Hendrik Makait
修复左侧为标量时的二进制操作 (dask-expr#1150) Patrick Hoefler
计算除法时引发异常 (dask-expr#1149) Patrick Hoefler
修复单分区的 merge_asof (dask-expr#1145) Patrick Hoefler
改进
analyze和explain中可选依赖的处理 (dask-expr#1146) Hendrik Makait修复 groupby 索引访问器中的对齐问题 (dask-expr#1142) Patrick Hoefler
修复时间戳标量显示问题 (dask-expr#1141) Patrick Hoefler
2024.9.1¶
亮点¶
改进的自适应扩展弹性¶
自适应扩展集群现在可以从扩展期间的虚假错误中恢复。
更多详细信息请参见 distributed#8871,作者 Hendrik Makait。
其他变更
改进 meta 信息中列顺序不正确的错误消息 (dask#11393) Dmitry Balabka
将 gpuCI
RAPIDS_VER更新到24.12(dask#11407)将
jacobtomlinson/gha-anaconda-package-version从 0.1.3 提升到 0.1.4 (dask#11405)改用
zarr.open_array而不是zarr.Array构造函数 (dask#11387) Joe Hamman将 gpuCI
RAPIDS_VER更新到24.12(distributed#8879)在执行
Scheduler.update_graph时不将 scheduler 视为闲置 (distributed#8877) Hendrik Makait将
jacobtomlinson/gha-anaconda-package-version从 0.1.3 提升到 0.1.4 (distributed#8878)支持 P2P 对 datetime 数组进行 rechunking (distributed#8875) James Bourbeau
2024.9.0¶
亮点¶
将 Bokeh 最低版本提升到 3.1.0¶
诊断和分布式集群仪表盘现在需要 bokeh>=3.1.0。
更多详细信息请参见 dask#11375 和 distributed#8861,作者 James Bourbeau。
引入新的 Task 类¶
添加 Task 类,用于替代 tuple 进行任务规范。
更多详细信息请参见 dask#11248,作者 Florian Jetter。
其他变更
将
peter-evans/create-pull-request从 6 提升到 7 (dask#11380)减少 tokenize 中的开销 (dask#11373) Florian Jetter
将
tokenize移至专用子模块 (dask#11371) Florian Jetter确保在存在多个分割时
process_runnables不过于急切 (dask#11367) Florian Jetter在 shuffle 中使用
np.min_scalar_type(dask#11369) James Bourbeau将索引数组写入 dask 图以减小多个 xarray 变量的大小 (dask#11362) Patrick Hoefler
在 shuffle 中将 indexer 转换为最小
dtype(dask#11364) Patrick Hoefler减少
dask.order的内存使用 (dask#11361) Florian Jetter将
JamesIves/github-pages-deploy-action从 4.6.3 提升到 4.6.4 (dask#11366)precommit自动更新 (dask#11360) Florian Jetter均匀调度 P2P 的 unpack 任务 (distributed#8873) Hendrik Makait
解决/修复 localhost 防火墙问题 (distributed#8868) Mario Linker
使用新的
tokenize模块 (distributed#8858) James Bourbeau使用幂等插件警告指向用户代码 (distributed#8856) James Bourbeau
修复测试 nanny 超时问题 (distributed#8847) Florian Jetter
将 JamesIves/github-pages-deploy-action 从 4.5.0 提升到 4.6.4 (distributed#8853)
通过只计算一次
func和kwargs的token来加速Client.map(distributed#8855) Florian Jetter更新
pre-commit(distributed#8852) Florian Jetter
2024.8.2¶
亮点¶
rechunking 方法的自动选择¶
为了使用户能够以比以前更大的规模重新分块数据,Dask 现在在集群上进行 rechunking 时会自动选择合适的 rechunking 方法。这不需要额外的配置,并且默认启用。
具体来说,Dask 在基于任务的 rechunking 和 P2P rechunking 之间进行选择。基于任务的 rechunking 是以前的默认方法,而当 rechunking 需要新旧块之间几乎所有对所有的通信时(例如,在空间和时间分块之间切换时),P2P rechunking 更具优势。在这些情况下,P2P rechunking 提供恒定的内存使用量并创建更小的任务图。因此,它适用于以前基于任务的 rechunking 会失败的情况。
要禁用自动选择,用户可以通过配置选择他们偏好的方法
import dask.config
# Choose either "tasks" or "p2p"
dask.config.set({"array.rechunk.method": "tasks"})
或在 rechunking 时
import dask.array as da
arr = da.random.random(size=(1000, 1000, 365), chunks=(-1, -1, "auto"))
# Choose either "tasks" or "p2p"
arr = arr.rechunk(("auto", "auto", -1), method="tasks")
更多详细信息请参见 dask#11337,作者 Hendrik Makait。
Dask 数组的新 shuffle API¶
Dask 为 Dask 数组添加了一个 shuffle API。这个 API 允许沿单个维度对数据进行混洗 (shuffling)。它将确保沿此维度的每组元素都恰好位于一个块中。这对于 Xarray 中的 GroupBy-Map 模式来说是一个非常有用的操作。有关更多信息和 API 签名,参见 shuffle()。
更多详细信息请参见 dask#11267、dask#11311 和 dask#11326,作者 Patrick Hoefler。
Dask 数组的新 blockwise_reshape API¶
新的 blockwise_reshape() 可以在你不关心底层数组顺序的情况下进行“非常并行化”(embarassingly parallel) 的重塑操作。它是“非常并行化”的,并且不再在底层触发 rechunking 操作。这在你不需要关心结果数组的顺序时很有用,例如对数组应用归约(reduction)时,或者重塑只是临时操作时。
arr = da.random.random(size=(100, 100, 48_000), chunks=(1000, 100, 83)
result = reshape_blockwise(arr, (10_000, 48_000))
result.sum()
# or: do something that preserves the shape of each chunk
result = reshape_blockwise(result, (100, 100, 48_000), chunks=arr.chunks)
如果维度数量减少,Dask 将自动计算结果块;如果维度数量增加,则必须指定结果块。
重塑 Dask 数组通常会在中间产生包含 rechunk 操作的非常复杂的计算,因为 Dask 默认遵循数组的 C 顺序。这确保了生成的 Dask 数组以与相应 NumPy 数组相同的顺序返回。然而,这可能导致非常低效的计算。如果你不关心顺序,blockwise_reshape 比默认实现效率高得多。
警告
Blockwise 重塑操作比默认操作更有效率,但它们会返回顺序不同的数组。请谨慎使用!
更多详细信息请参见 dask#11328,作者 Patrick Hoefler。
保持块大小一致的多维位置索引¶
以前,使用 vindex() 索引 Dask 数组会在被索引的维度上创建一个单一的输出块。vindex 通常在 Xarray 中用于一次性索引多个维度,例如:
arr = xr.DataArray(
da.random.random((100, 100, 100), chunks=(5, 5, 50)),
dims=['a', "b", "c"],
)
以前,这将索引的维度放入一个单一的块中

Dask 现在使用改进的算法来确保块大小保持一致

更多详细信息请参见 dask#11330,作者 Patrick Hoefler。
其他变更
为 shuffle、
vindex和blockwise_reshape添加更新日志条目 (dask#11350) Patrick Hoefler确保持久化集合在没有 GC 的情况下释放 (dask#11348) Florian Jetter
更新 dask 会议的 zoom 链接 (dask#11357) Sarah Charlotte Johnson
为
normalize_chunks添加更多 docstring 示例 (dask#11271) Illviljan自动选择基于任务的 rechunking 或 P2P rechunking (dask#11337) Hendrik Makait
为数组实现 blockwise 重塑 API (dask#11328) Patrick Hoefler
使 shuffle 中的 rechunking 更智能,以便在必要时进行不均匀分布 (dask#11326) Patrick Hoefler
提高 GPU CI 更新的可见性 (dask#11345) Charles Blackmon-Luca
更新安装文档中的
numpy和pyarrow版本 (dask#11340) James Bourbeau修复 dask 和 distributed 依赖问题 (dask#11338) Patrick Hoefler
将
numpy>=1.24和pyarrow>=14.0.1的最低版本提升 (dask#11331) James Bourbeau将
crick添加回 Python 3.11+ CI 构建 (dask#11335) James Bourbeau在
vindex中保留 chunksizes (dask#11330) Patrick Hoefler修复
dask.array.fft与 Numpy 接口不匹配的问题(添加对norm参数的支持)(dask#10665) joanrue将额外参数传递给
rechunk_p2p(dask#11319) Hendrik Makait修复
map_overlap的 docstring 格式问题 (dask#11332) Tao Xin修复 NumPy 2.0 上
prod的溢出问题 (dask#11327) Patrick Hoefler确保
axes是正数 / 添加负数轴的测试 (dask#10812) joanrue修复带有
new_axis的map_overlap问题 (dask#11128) David Stansby避免捕获
xdist的代码 (distributed#8846) Florian Jetter减少剔除 P2P rechunking 的内存占用 (distributed#8845) Hendrik Makait
添加选择默认 rechunking 方法的测试 (distributed#8843) Hendrik Makait
提高 GPU CI 更新的可见性 (distributed#8841) Charles Blackmon-Luca
增加
test_pause_while_idle超时时间 (distributed#8844) Florian Jetter在 P2P rechunking 之前连接小的输入块 (distributed#8832) Hendrik Makait
从
gen_cluster中移除 dump cluster 功能 (distributed#8823) Florian Jetter将
numpy>=1.24和pyarrow>=14.0.1的最低版本提升 (distributed#8837) James Bourbeau修复
Worker上的PipInstall插件问题 (distributed#8839) Hendrik Makait移除更多 Python 3.10 兼容性代码 (distributed#8824) James Bourbeau
使用基于任务的 rechunking 沿着部分边界进行预分块 (distributed#8831) Hendrik Makait
确保
client_desires_keys不会损坏Scheduler状态 (distributed#8827) Florian Jetter将 `cloudpickle` 的最低版本提升到 3 (distributed#8836) James Bourbeau
2024.8.1¶
亮点¶
改进重塑 Dask 数组的输出块大小¶
重塑 Dask 数组通常会将需要重塑的维度压缩到一个单一的块中。这导致了非常大的输出块,随后产生了许多内存不足错误和性能问题。
arr = da.ones(shape=(1000, 100, 48_000), chunks=(1000, 100, 83))
arr.reshape(1000, 100, 4, 12_000)
以前,这将最后一个维度放入一个大小为 12_000 的单一块中。

新算法将确保输入和输出之间的块大小保持一致。这将避免块大小的大幅增加和块的碎片化。

提高 Xarray Rechunk-GroupBy-Reduce 模式的调度效率¶
以前,scheduler 为使用 cohorts 策略的 Xarray GroupBy-Reduction 模式创建了低效的执行图
import xarray as xr
arr = xr.open_zarr(...)
arr.chunk(time=TimeResampler("ME")).groupby("time.month").mean()
生成任务图执行顺序的算法存在一个问题,导致了低效的执行策略,在集群上累积了许多不必要的内存。这项改进与 2024.08.0 中的先前排序改进非常相似。
放弃对 Python 3.9 的支持¶
根据 NEP 29,此版本放弃对 Python 3.9 的支持。Python 3.10 现在是运行 Dask 所需的最低版本。
更多详细信息请参见 dask#11245 和 distributed#8793,作者 Patrick Hoefler。
其他变更
确保
pickle不会改变 token (dask#11320) Florian Jetter为
reshape和排序改进添加更新日志条目 (dask#11324) Patrick Hoefler重命名
chunksize-tolerance选项 (dask#11317) Patrick Hoefler升级 gpuCI 并修复使用 “cupy” 后端导致的 Dask Array 失败问题 (dask#11309) Richard (Rick) Zamora
实现
shuffle的自动 rechunking (dask#11311) Patrick Hoefler确保我们在 CI 中针对
numpy2 进行测试 (dask#11182) James Bourbeau撤销“在 distributed scheduler 上测试排序 (dask#11310)” (dask#11321) Florian Jetter
在 distributed scheduler 上测试排序 (dask#11310) Florian Jetter
添加测试以覆盖新的
reshape实现的更多情况 (dask#11313) Patrick Hoefler排序:为具有多个叶节点的 branches 选择更好的目标 (dask#11303) Patrick Hoefler
排序:确保可运行任务确实是可运行的 (dask#11305) Florian Jetter
修复上游
numpy构建问题 (dask#11304) Patrick Hoefler如果可能,使
shuffle成为无操作 (dask#11291) Patrick Hoefler在
reshape中保持chunksize一致 (dask#11273) Patrick Hoefler启用只包含一个未知块的切片 (dask#11301) Patrick Hoefler
在 Dask 文档中链接到
dask与spark的基准测试 (dask#11289) Sarah Charlotte Johnson修复 masked arrays 的切片问题 (dask#11300) Patrick Hoefler
数组:修复带有
dtype的数组输入的asarray(dask#11288) Lucas Colley将
numpy常量添加到数组 api (dask#11287) Lucas Colley忽略返回值的类型标注 (dask#11286) Patrick Hoefler
移除 reshape 中的自动 resizing (dask#11269) Patrick Hoefler
API:在
dask.array命名空间中暴露npdtypes (dask#11178) Lucas Colley降低非托管内存使用警告的频率 (distributed#8834) Patrick Hoefler
将 gpuCI
RAPIDS_VER更新到24.10(distributed#8786)避免在
Server._shift_counters()中出现RuntimeError: dictionary changed size during iteration(distributed#8828) Hendrik Makait改进 scheduler 的并发关闭 (distributed#8829) Hendrik Makait
次要:从 P2P rechunking 的部分连接中提取截断逻辑 (distributed#8826) Hendrik Makait
避免
remove_from_task_prefix_count过多的属性访问开销 (distributed#8821) Florian Jetter如果验证被禁用,避免进行键验证 (distributed#8822) Florian Jetter
记录
worker_client事件 (distributed#8819) James Bourbeau
2024.8.0¶
亮点¶
提高使用位置索引器进行切片的效率和性能¶
使用位置索引器对 Dask 数组进行切片的性能改进。现在随机访问模式更稳定,并产生更易于使用的结果。
x[slice(None), [1, 1, 3, 6, 3, 4, 5]]
以前使用位置索引器容易导致输出块数量急剧增加并生成非常大的任务图。这已通过更高效的算法得到修复。
新算法将沿被索引的轴保持相同的块大小,以避免块的碎片化或块大小的大幅增加。
更多详细信息和性能基准测试请参见 dask#11262 和 dask#11267,作者 Patrick Hoefler。
提高 Xarray GroupBy-Reduce 模式的调度效率¶
以前,scheduler 为诸如以下 Xarray GroupBy-Reduction 模式创建了低效的执行图:
import xarray as xr
arr = xr.open_zarr(...)
arr.groupby("time.month").mean()
生成任务图执行顺序的算法存在一个问题,导致了低效的执行策略,在集群上累积了许多不必要的内存。
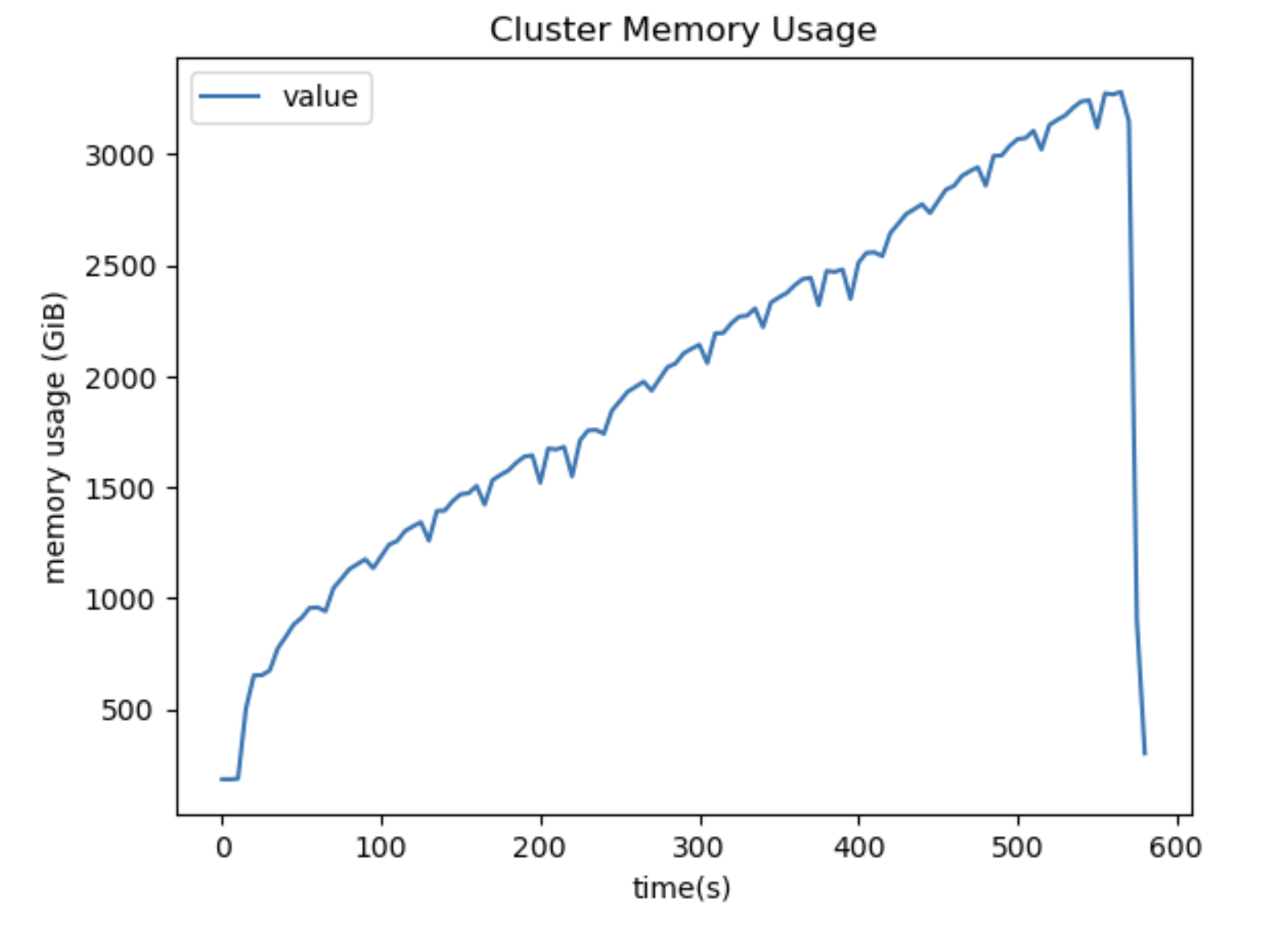
该操作本身是“非常并行化”的。使用正确的执行策略,scheduler 现在可以用恒定内存执行操作,避免溢出,并允许我们扩展到更大的数据集。
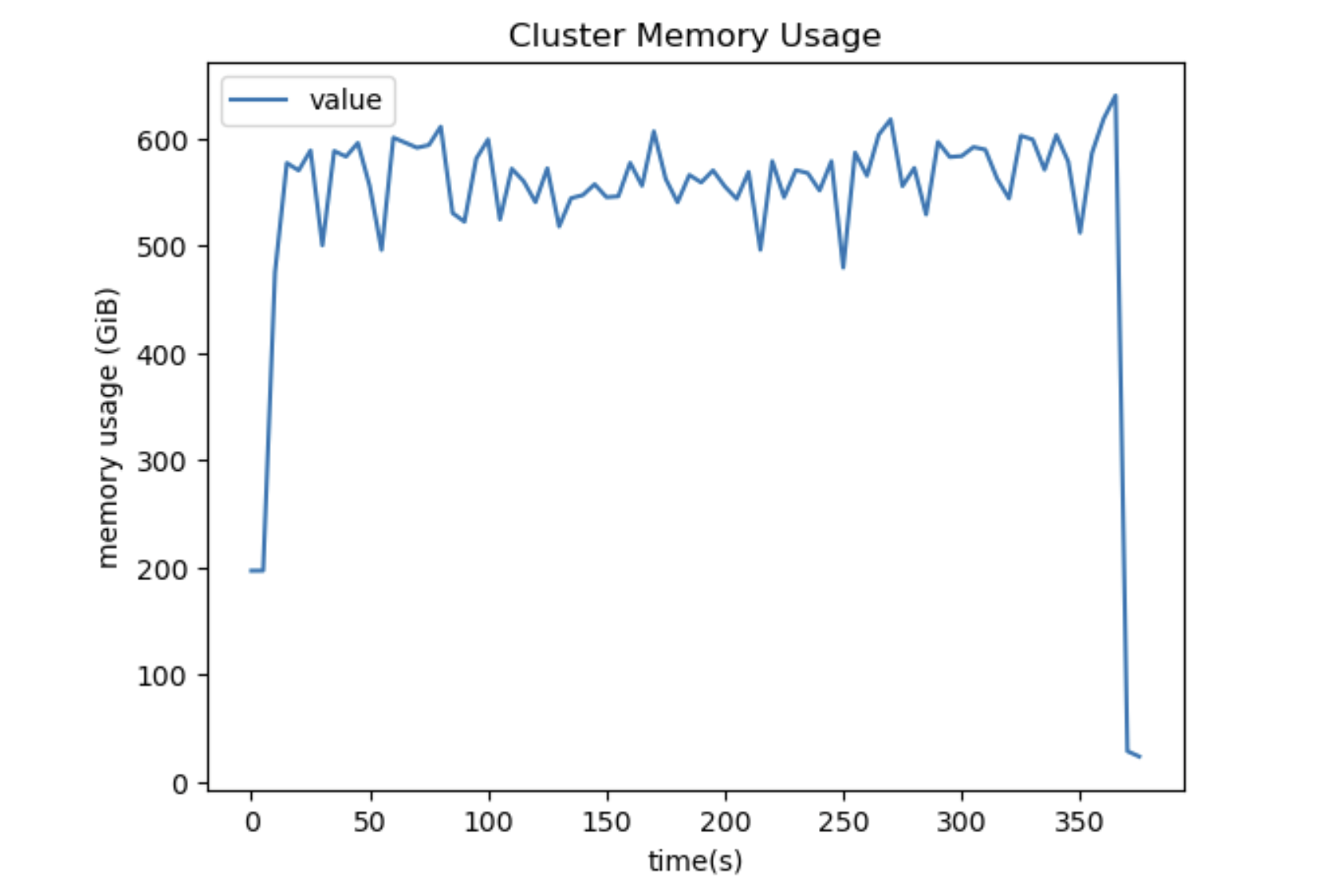
更多详细信息和示例请参见 distributed#8818,作者 Patrick Hoefler。
其他变更
为 dask order 补丁添加更新日志 (dask#11278) Patrick Hoefler
为
xarraymap reduce 添加回归测试 (dask#11277) Florian Jetter为
take添加更新日志条目 (dask#11274) Patrick Hoefler撤销“order: 移除数据任务图规范化” (dask#11276) Patrick Hoefler
对
take使用 shuffle 算法 (dask#11267) Patrick Hoefler实现基于任务的数组 shuffle (dask#11262) Patrick Hoefler
移除数据任务图规范化 (dask#11263) Florian Jetter
更新月度会议的 zoom 链接 (dask#11265) Sarah Charlotte Johnson
更新最佳实践中的数据加载部分 (dask#11247) Patrick Hoefler
将 docstring 中的默认
chunksize与代码中实际设置的默认值匹配 (dask#11254) Bernhard Raml修复
pandas3 中的 casting 错误 (dask#11250) Patrick Hoefler跳过来自
pandas的新警告 (dask#11249) Patrick Hoefler修复
pandas夜间构建中的错误 (dask#11244) Patrick Hoefler在 dask order 之后运行图规范化 (distributed#8818) Patrick Hoefler
更新大型图大小警告,移除 scatter 建议 (distributed#8815) Patrick Hoefler
使超过
no-workers-timeout的任务失败 (distributed#8806) Hendrik Makait修复
NannyPlugin.setup和NannyPlugin.teardown的异常处理 (distributed#8811) Hendrik Makait修复
WorkerPlugin.setup和WorkerPlugin.teardown的异常处理 (distributed#8810) Hendrik Makait拼写错误修复 (distributed#8812) alex-rakowski
修复
send_recv_from_rpc的if/else问题 (distributed#8809) Patrick Hoefler确保 adaptive 只停止一次 (distributed#8807) Hendrik Makait
减少与 GC 相关的日志噪声 (distributed#8804) Hendrik Makait
从
Scheduler中移除未使用的delete_interval和synchronize_worker_interval(distributed#8801) Hendrik Makait更改 Compute Failed 日志消息的日志级别 (distributed#8802) Patrick Hoefler
添加 GC 耗时相关的 Prometheus 指标 (distributed#8803) Hendrik Makait
添加
dask_worker_{added|removed}_total的 Prometheus 指标 (distributed#8798) Hendrik Makait添加
worker-ttl-timed-out的日志事件 (distributed#8800) Hendrik Makait添加
dask_client_connections_{added|removed}_total的 Prometheus 指标 (distributed#8799) Hendrik Makait修复
PackageInstall插件 (distributed#8794) Hendrik Makait使窃取更健壮 (distributed#8788) Hendrik Makait
留下关于未来实例化的警告 (distributed#8782) Florian Jetter
2024.7.1¶
亮点¶
更具弹性的分布式锁¶
distributed.Lock (¶) 现在对 worker 故障具有弹性。以前,在持有锁的 worker 丢失和/或因错误未能释放锁的情况下,可能会发生死锁。
更多详细信息请参见 distributed#8770,作者 Florian Jetter。
其他变更
移除 persist 使用并发出警告 (dask#11237) Patrick Hoefler
在创建
meta时保留timestamp单位 (dask#11233) Patrick Hoefler确保
dask-exprDataFrames在放入delayed时被优化 (dask#11231) Patrick Hoefler修复
pandas=3中dfreq 废弃的问题 (dask#11228) James Bourbeau提高
test_quantile的近似阈值 (dask#10720) Florian Jetter将
xarray-contrib/issue-from-pytest-log从 1.2.8 提升到 1.3.0 (dask#11221)将
JamesIves/github-pages-deploy-action从 4.6.1 提升到 4.6.3 (dask#11222)确保
Lock总是向 scheduler 注册 (distributed#8781) Florian Jetter临时固定
setuptools < 71(distributed#8785) James Bourbeau恢复
TaskPrefix上的len()(distributed#8783) Hendrik Makait避免
p2p-failed日志事件的误报 (distributed#8777) Hendrik Makait在 prometheus 中分别暴露暂停和退役的 worker (distributed#8613) Patrick Hoefler
创建 transitions-failures 日志事件 (distributed#8776) alex-rakowski
为 P2P rechunking 实现 HLG 层 (distributed#8751) Hendrik Makait
添加另一个测试以验证 (distributed#8703) 可能导致的死锁场景 ((distributed#8769)) Hendrik Makait
如果对具有已释放 futures 的持久化集合进行计算,则引发错误 (distributed#8764) Florian Jetter
从失败的 P2P 任务中重新引发
P2PConsistencyError(distributed#8748) Hendrik Makait更健壮更快的测试内存采样器 (distributed#8758) Florian Jetter
修复
scheduler_bokeh::test_shuffling(distributed#8766) Florian Jetter增加
pubsub::test_client_worker的超时时间 (distributed#8765) Florian Jetter提取异步 taskgroup (distributed#8756) Florian Jetter
在 worker 表中不要按字典顺序对键进行排序 (distributed#8753) Florian Jetter
对于频繁调用的函数,使用
functools.cache而不是functools.lru_cache(distributed#8762) Jonas Dedden更健壮的深度嵌套结构 (distributed#8730) Florian Jetter
将 HLG 添加到 MAP (distributed#8740) alex-rakowski
在 worker 信息页面添加关闭 worker 按钮 (distributed#8742) James Bourbeau
2024.7.0¶
亮点¶
放弃对 pandas 1.x 的支持¶
此版本放弃对 pandas<2 的支持。pandas 2.0 现在是运行 Dask DataFrame 所需的最低版本。
partd 的最低版本也提升到 1.4.0。1.4 版本之前的不兼容 pandas 2。
更多详细信息请参见 dask#11199,作者 Patrick Hoefler。
发布-订阅 API 废弃¶
distributed.Pub (¶) 和 distributed.Sub (¶) 已被废弃,并将在未来版本中移除。请改用 distributed.Client.log_event() (¶) 和 distributed.Worker.log_event() (¶)。
更多详细信息请参见 distributed#8724,作者 Hendrik Makait。
其他变更
对于
xarray的sizeof,只计算内存中的数据 (dask#11206) Florian Jetter修复
botocore重新引发错误的问题 (dask#11209) Patrick Hoefler更新文档中的 Coiled 链接 (dask#11211) Sarah Charlotte Johnson
添加一些 array-expr 方法 (dask#11210) Patrick Hoefler
修复 arrow dtypes 的
quantile问题 (dask#11202) Patrick Hoefler添加用于验证可选依赖的工具 (dask#11205) Patrick Hoefler
实现数组表达式开关 (dask#11203) Patrick Hoefler
移除不再支持的
ipython引用 (dask#11196) Patrick Hoefler移除
from_delayed引用 (dask#11195) Patrick Hoefler将其他 IO 连接器添加到文档中 (dask#11189) Patrick Hoefler
修复从
cudf导入assert_eq的问题 (distributed#8747) James Bourbeau任务错误时记录 traceback (distributed#8746) Hendrik Makait
轮询 Prometheus 指标时更新系统监视器 (distributed#8745) Hendrik Makait
在
mindeps构建中将pandas提升到 2.0 (distributed#8743) James Bourbeau将事件日志功能重构到 broker 中 (distributed#8731) Hendrik Makait
放弃对 pandas 1.X 的支持 (distributed#8741) Hendrik Makait
移除
is_python_shutting_down(distributed#8492) Hendrik Makait修复
test_task_state_instance_are_garbage_collected(distributed#8735) Hendrik Makait修复浮点精度问题 (distributed#8736) Hendrik Makait
修复
pynvml句柄问题 (distributed#8693) Benjamin Zaitlenget_ip:处理获取0.0.0.0的情况 (distributed#8712) Adam Williamson移除
test_task_state_instance_are_garbage_collected中的FutureWarning(distributed#8734) Hendrik Makait修复 CI 上的
mindeps测试问题 (distributed#8728) Hendrik Makait将与事件日志相关的测试提取到单独的文件中 (distributed#8733) Hendrik Makait
对
ProcessPoolExecutor使用更安全的上下文 (distributed#8715) Elliott Sales de Andrade在仪表盘中缓存 worker 地址的 URL 编码 (distributed#8725) Florian Jetter
更健壮的
bokehtest_shuffling(distributed#8727) Florian Jetter修复 actor 文档中的类型错误 (distributed#8711) Sultan Orazbayev
如果提供了插件类型而不是实例,给出更有用的警告 (distributed#8689) Florian Jetter
改进因断开连接导致任务取消时的错误信息 (distributed#8705) Hendrik Makait
修复
test_forget_errors的等待条件 (distributed#8714) Elliott Sales de Andrade跳过
test_deadlock_dependency_of_queued_released(distributed#8723) Hendrik Makait修复
test_quiet_client_close(distributed#8722) Hendrik Makait修复
save_sys_modules中的清理迭代问题 (distributed#8713) Elliott Sales de Andrade为缺失的
bokeh安装命令添加引号 (distributed#8717) James Bourbeau
2024.6.2¶
这是为了解决 2024.6.1 版本中 dask 和 distributed 版本固定问题而发布的补丁版本。
其他变更
使文档构建通过 (dask#11184) James Bourbeau
profile._f_lineno:处理 Python 3.13 中next_line为None的情况 (dask#8710) Adam Williamson
2024.6.1¶
亮点¶
此版本包含一个关键修复,修复了当 root-ish 任务的依赖被重新调度时(例如由于 worker 丢失)可能出现的死锁问题。
更多详细信息请参见 distributed#8703,作者 Hendrik Makait。
其他变更
缓存全局查询计划配置 (dask#11183) Richard (Rick) Zamora
Python 3.13 修复 (dask#11185) Adam Williamson
修复
pandas=3的test_map_freq_to_period_start(dask#11181) James Bourbeau将 release-drafter/release-drafter 从 5 提升到 6 (distributed#8699)
2024.6.0¶
亮点¶
memmap 数组 tokenization¶
现在对 memmap 数组进行 tokenization 将避免将数组实体化到内存中。
更多详细信息请参见 dask#11161,作者 Florian Jetter。
其他变更
修复禁用查询计划时的
test_dt_accessor问题 (dask#11177) James Bourbeau使用
packaging.version.Version(dask#11171) James Bourbeau移除废弃的
dask.compatibility模块 (dask#11172) James Bourbeau确保与
xarray.NamedArray的兼容性 (dask#11168) Hendrik Makait估计
xarray集合的大小 (dask#11166) Florian Jetter添加关于 futures 和 variables 的部分 (dask#11164) Florian Jetter
更新 Dask 社区会议信息合并文档 (dask#11159) Sarah Charlotte Johnson
避免在
test_prometheus_collect_count_total_by_cost_multipliers中出现舍入错误 (distributed#8687) Hendrik Makait在
update_graph日志事件中记录键冲突计数 (distributed#8692) Hendrik Makait当推送新标签时自动发布 GitHub 版本 (distributed#8626) Jacob Tomlinson
修复具有多个主题的日志事件 (distributed#8691) Hendrik Makait
将
safe重命名为expected在Scheduler.remove_worker中 (distributed#8686) Hendrik Makait记录故障期间的日志事件 (distributed#8663) Hendrik Makait
积极更新
TaskPrefix的聚合统计信息,而不是按需计算 (distributed#8681) Hendrik Makait通过避免将解包递归到索引中,提高 P2P 分块重组的图提交时间 (distributed#8672) Florian Jetter
向
remove-worker事件添加 safe 关键字 (distributed#8647) alex-rakowski改进了 P2P RPC 调用的错误处理并减少了日志记录 (distributed#8666) Hendrik Makait
调整
dask-expr的 P2P 测试 (distributed#8662) Hendrik Makait迭代
Server.digests_total_since_heartbeat的副本,以避免RuntimeError(distributed#8670) Hendrik Makait在计算失败中记录任务状态 (distributed#8668) Hendrik Makait
为任务组添加 Prometheus gauge (distributed#8661) Hendrik Makait
修复
pandas子类 shuffle 代码中过于严格的断言 (distributed#8667) Joris Van den Bossche减少不应运行的错误任务产生的干扰 (distributed#8664) Hendrik Makait
2024.5.2¶
此版本主要包含一些小的错误修复。
其他变更
修复 CI 中 Zarr 夜间构建的安装问题 (dask#11151) James Bourbeau
向 GPU CI 添加 python 3.11 构建 (dask#11135) Charles Blackmon-Luca
将 gpuCI
RAPIDS_VER更新到24.08(dask#11141)更新
test_groupby_grouper_dispatch(dask#11144) Richard (Rick) Zamora将
JamesIves/github-pages-deploy-action从 4.6.0 升级到 4.6.1 (dask#11136)在新
sparse版本中取消跳过test_array_function_sparse(dask#11139) James Bourbeau修复
test_parse_dates_multi_column在pandas=3上的问题 (dask#11132) James Bourbeau不要为标记的提交起草发布说明 (dask#11138) Jacob Tomlinson
减少部分 P2P 分块重组的任务组计数 (distributed#8655) Hendrik Makait
将 gpuCI
RAPIDS_VER更新到24.08(distributed#8652)向调度器提交集合元数据 (distributed#8612) Florian Jetter
修复
task-launch.rst代码示例中的缩进问题 (distributed#8650) Ray Bell避免多个
WorkerStatesphinx 错误 (distributed#8643) James Bourbeau
2024.5.1¶
亮点¶
支持 NumPy 2.0¶
此版本包含对即将发布的 NumPy 2.0 版本的兼容性更新。
详见 dask#11096 (由 Benjamin Zaitlen 提交) 和 dask#11106 (由 James Bourbeau 提交) 了解更多详情。
增加对 Zarr 存储的支持¶
此版本增加了对 MutableMapping 支持的 Zarr 存储(如 zarr.storage.DirectoryStore 等)的支持。
详见 dask#10422 (由 Greg M. Fleishman 提交) 了解更多详情。
其他变更
机器学习页面的小更新 (dask#11129) James Bourbeau
跳过在 0.15.2 上失败的
sparse测试 (dask#11131) James Bourbeau确保在上游 CI 构建中安装了夜间版
pyarrow(dask#11121) James Bourbeau添加机器学习概述文档的初步草稿 (dask#11114) Matthew Rocklin
在 gpuCI 中测试查询规划 (dask#11060) Richard (Rick) Zamora
跳过 NumPy 2.0 测试时避免
pytest错误 (dask#11110) James Bourbeau在上游 CI 构建中使用夜间版
h5py(dask#11108) James Bourbeau在上游 CI 构建中使用夜间版
scikit-image(dask#11107) James Bourbeau将
actions/checkout从 4.1.4 升级到 4.1.5 (dask#11105)修复后启用 parquet 追加测试 (dask#11104) Patrick Hoefler
跳过
numpy2 的fastparquet测试 (dask#11103) Patrick Hoefler修复 codespell 发现的拼写错误 (dask#11097) Dimitri Papadopoulos Orfanos
修复文档构建 (dask#11099) Patrick Hoefler
清理
percentiles_summary逻辑 (dask#11094) Richard (Rick) Zamora应用
ruff/flake8-implicit-str-concat规则 ISC001 (dask#11098) Dimitri Papadopoulos Orfanos修复 Windows 上 Python 3.13 的时钟问题 (distributed#8642) Victor Stinner
修复 Mac OS (arm64) 上“打印主机信息”CI 步骤的问题 (distributed#8638) Hendrik Makait
2024.5.0¶
亮点¶
此版本主要包含一些小的错误修复。
其他变更
不要链接到
clickintersphinx dev 版本 (dask#11091) M Bussonnier修复某些
dask-expr表达式的 API 文档链接 (dask#11092) Patrick Hoefler向 上游构建 添加
dask-expr(dask#11086) Patrick Hoefler在启用
query-planning时添加melt支持 (dask#11088) Richard (Rick) Zamora在
numpy2 环境中跳过 dataframe/product (dask#11089) Benjamin Zaitlen添加图表说明优化器作用 (dask#11072) Patrick Hoefler
修复
pandas上游测试 (dask#11085) Patrick Hoefler将
conda-incubator/setup-miniconda从 3.0.3 升级到 3.0.4 (dask#11084)将
actions/checkout从 4.1.3 升级到 4.1.4 (dask#11083)修复
pytest更改后的 CI 问题 (dask#11082) Patrick Hoefler修复更高效
dask-expr实现的测试 (dask#11071) Patrick Hoefler泛化
clear_known_categories工具 (dask#11059) Richard (Rick) Zamora将
JamesIves/github-pages-deploy-action从 4.5.0 升级到 4.6.0 (dask#11062)将
release-drafter/release-drafter从 5 升级到 6 (dask#11063)将
actions/checkout从 4.1.2 升级到 4.1.3 (dask#11061)更新 GPU CI
RAPIDS_VER到 24.06,禁用查询规划 (dask#11045) Charles Blackmon-Luca移动测试 (distributed#8631) Hendrik Makait
将
actions/checkout从 4.1.2 升级到 4.1.3 (distributed#8628)
2024.4.2¶
亮点¶
简化合并实现¶
查询优化器将检查查询以确定 merge(...) 或 groupby(...).apply(...) 是否需要 shuffle。如果 DataFrame 在之前的步骤中已在相同列上进行了 shuffle,并且中间没有任何操作改变分区布局或每个分区中的相关值,则可以避免 shuffle。
>>> result = df.merge(df2, on="a")
>>> result = result.merge(df3, on="a")
查询优化器将识别出 result 之前也在 "a" 上进行了 shuffle,因此在执行块式合并之前,只对 df3 进行 shuffle。
在 read_parquet 中自动分区¶
如果单个分区过小,查询优化器将自动对从 Parquet 文件读取的数据集进行重新分区。这将减少分区的数量,从而减小任务图的大小。
优化器旨在生成至少 75MB 的分区,并在必要时合并多个文件以达到此阈值。该值可以通过以下方式配置
>>> dask.config.set({"dataframe.parquet.minimum-partition-size": 100_000_000})
该值以字节为单位。默认阈值相对保守,以避免每个线程内存量相对较小的工作节点上的内存问题。
其他变更
添加 GitHub Releases 自动化 (dask#11057) Jacob Tomlinson
为新版本添加更改日志条目 (dask#11058) Patrick Hoefler
在
_bind_property中恢复 try/except 块 (dask#11049) Lawrence Mitchell修复查询规划文档的链接 (dask#11054) Patrick Hoefler
为 parquet 文件大小添加配置参数 (dask#11052) Patrick Hoefler
更新
percentiledocstring (dask#11053) Abel Aoun添加查询优化器文档 (dask#11043) Patrick Hoefler
将 np.ma.masked 赋值给对象类型数组 (dask#9627) David Hassell
如果未安装
dask_expr,则不报错 (dask#11048) Simon Høxbro Hansen为 “cudf” 后端调整
test_set_index(dask#11029) Richard (Rick) Zamora使用
to/from_legacy_dataframe代替to/from_dask_dataframe(dask#11025) Richard (Rick) Zamora对 bag
groupby键进行 Tokenization (dask#10734) Charles Stern为 P2P 相关分派函数添加 “cudf” 的延迟注册 (dask#11040) Richard (Rick) Zamora
在异常时收集
memray配置 (distributed#8625) Florian Jetter确保
inproc正确模拟序列化协议 (distributed#8622) Florian Jetter放宽测试统计信息 profiling2 (distributed#8621) Florian Jetter
当
worker-ttl过期时重启 workers (distributed#8538) crusaderky使用
monotonic进行截止时间测试 (distributed#8620) Florian Jetter修复带有注解的 published futures 的竞争条件 (distributed#8577) Florian Jetter
按 worker 而非
worker->nthreads进行 scatter (distributed#8590) Miles如果 worker 因内存压力而重启,则发送日志事件 (distributed#8617) Patrick Hoefler
不在 CI 中打印 xfailed 测试 (distributed#8619) Florian Jetter
确保 workers 参与 P2P 时不会被缩减 (distributed#8610) Florian Jetter
针对 stable
fsspec运行 (distributed#8615) Florian Jetter
2024.4.1¶
这是一个小的错误修复版本,它修复了在 Python 3.11.9 中导入 dask.dataframe 时出现的错误。
详见 dask#11035 和 dask#11039 (由 Richard (Rick) Zamora 提交) 了解详情。
其他变更
移除命名聚合的跳过项 (dask#11036) Patrick Hoefler
在 unpickle 时不对只读缓冲区进行深拷贝 (distributed#8609) crusaderky
向
daskconda recipe 添加dask-expr(distributed#8601) Charles Blackmon-Luca
2024.4.0¶
亮点¶
查询规划修复¶
此版本包含 Dask DataFrame 新查询规划器的各种错误修复。
GPU 指标仪表板修复¶
GPU 内存和利用率仪表板功能已恢复。此前这些图表意外留白。
详见 distributed#8572 (由 Benjamin Zaitlen 提交) 了解详情。
其他变更
在标签发布时构建夜间版本 (dask#11014) Charles Blackmon-Luca
从测试套件中移除
xfail回溯信息 (dask#11028) Patrick Hoefler修复上游
pandas更改导致的 CI 问题 (dask#11027) Patrick Hoefler修复分支只包含 NaNs 时
value_counts抛出异常的问题 (dask#11023) Patrick Hoefler在
dask_cudf中启用自定义表达式 (dask#11013) Richard (Rick) Zamora当无法导入
dask-expr时,抛出ImportError而非ValueError(dask#11007) James Lamb向
ecosystem.rst添加 HypersSpy (dask#11008) Jonas Lähnemann向
fsspec兼容的远程服务列表添加 Hugging Facehf://(dask#11012) Quentin Lhoest将
actions/checkout从 4.1.1 升级到 4.1.2 (dask#11009)更新注解和 span 的文档 (distributed#8593) crusaderky
修复
pandas的弃用警告 (distributed#8564) Patrick Hoefler向 GPU CI 矩阵添加 Python 3.11 (distributed#8598) Charles Blackmon-Luca
截止时间使用 monotonic timer (distributed#8597) crusaderky
将 gpuCI
RAPIDS_VER更新到24.06(distributed#8588)重构
restart()和restart_workers()(distributed#8550) crusaderky将
actions/checkout从 4.1.1 升级到 4.1.2 (distributed#8587)修复
bokeh弃用问题 (distributed#8594) Miles修复不稳定的测试:
test_shutsdown_cleanly(distributed#8582) Miles在失败的
sizeof警告中包含类型 (distributed#8580) James Bourbeau
2024.3.1¶
这是一个小型版本,主要将未安装 dask-expr 时的异常降级为警告。
其他变更
仅在未安装
dask-expr时发出警告 (dask#11003) Florian Jetter修复 codespell 发现的拼写错误 (dask#10993) Dimitri Papadopoulos Orfanos
禁用
dask-expr的额外 CI job (distributed#8583) crusaderky修复 worker 仪表板代理 (distributed#8528) Miles
修复不稳定的
test_restart_waits_for_new_workers(distributed#8573) crusaderky修复不稳定的
test_raise_on_incompatible_partitions(distributed#8571) crusaderky
2024.3.0¶
发布于 2024 年 3 月 11 日
亮点¶
查询规划¶
此版本默认对所有 dask.dataframe 用户启用查询规划。
查询规划功能表示使用 dask-expr 重写了 DataFrame。这是一个直接替换,我们预计大多数用户无需调整任何代码。任何反馈都可以在 Dask 问题跟踪器或 查询规划反馈问题上报告。
如果遇到任何问题,您仍然可以通过设置以下选项来选择退出:
>>> import dask
>>> dask.config.set({'dataframe.query-planning': False})
结束对 Pandas 1.X 的支持¶
新的查询规划后端至少需要 pandas 2.0。如果您通过 conda 安装,或者通过 pip 使用 dask[complete] 或 dask[dataframe] 安装,将自动安装此 pandas 版本。
如果您在安装 dask 时不带 extras,旧的 DataFrame 实现仍然支持 pandas 1.X。
其他变更
使用 dask-expr 更新 pandas nightlies 的测试 (dask#10989) Patrick Hoefler
使用 dask-expr 文档作为 DataFrame 的主要参考文档 (dask#10990) Patrick Hoefler
为 dask-expr 调整 from_array 测试 (dask#10988) Patrick Hoefler
取消跳过
to_delayed测试 (dask#10985) Patrick Hoefler将 conda-incubator/setup-miniconda 从 3.0.1 升级到 3.0.3 (dask#10978)
修复启用 dask-expr 时的错误 (dask#10977) Patrick Hoefler
更新 dask-expr 的文档和要求,并移除警告 (dask#10976) Patrick Hoefler
修复 numpy 2 与 ogrid 用法的兼容性问题 (dask#10929) David Hoese
开启 dask-expr 开关 (dask#10967) Patrick Hoefler
强制使用相同的字节顺序解释器初始化随机种子... (dask#10970) Elliott Sales de Andrade
读取 CSV 时使用正确的行终止符编码 (dask#10972) Elliott Sales de Andrade
性能:在 _optimize_blockwise 中不要不必要地重新计算输入/输出索引 (dask#10966) Lindsey Gray
为 dask-expr 中的字符串选项调整测试 (dask#10968) Patrick Hoefler
为 dask-expr 中的数组转换调整测试 (dask#10973) Patrick Hoefler
TST: 修复 32 位上的 sizeof 测试 (dask#10971) Elliott Sales de Andrade
TST: 为 pyarrow 添加缺少的跳过项 (dask#10969) Elliott Sales de Andrade
实现
bag.to_dataframe的 dask-expr 转换 (dask#10963) Patrick Hoefler修复 dask-expr 导入错误 (dask#10964) Miles
清理
dask.config的 Sphinx 文档 (dask#10959) crusaderky在 Python 3.12+ 上使用 stdlib
importlib.metadata(dask#10955) wim glenn将 partitioning_index 转换为较小的尺寸 (dask#10953) Florian Jetter
重用 dask/dask groupby Aggregation (dask#10952) Patrick Hoefler
确保 futures 上的 tokens 是唯一的 (distributed#8569) Florian Jetter
不要模糊细微性能指标故障 (distributed#8568) crusaderky
在 dask-expr 中标记 shuffle fast 任务 (distributed#8563) crusaderky
按持续时间权重计算 gilknocker Prometheus metric (distributed#8558) crusaderky
修复调度器在 memory->erred 上的转换错误 (distributed#8549) Hendrik Makait
再次让 CI 满意 (distributed#8560) Miles
修复不稳定的 test_Future_release_sync (distributed#8562) crusaderky
修复不稳定的 test_flaky_connect_recover_with_retry (distributed#8556) Hendrik Makait
scheduler.py 中的类型调整 (distributed#8551) crusaderky
将 conda-incubator/setup-miniconda 从 3.0.2 升级到 3.0.3 (distributed#8553)
在 CI 上安装 dask-expr (distributed#8552) Hendrik Makait
P2P shuffle 可以在写入磁盘前删除分区列 (distributed#8531) Hendrik Makait
worker 移除的更好日志记录 (distributed#8517) crusaderky
为 merge 添加 indicator 支持 (distributed#8539) Patrick Hoefler
将 conda-incubator/setup-miniconda 从 3.0.1 升级到 3.0.2 (distributed#8535)
获取模块路径时避免迭代错误 (distributed#8533) James Bourbeau
在代码收集时忽略 stdlib threading 模块 (distributed#8532) James Bourbeau
防止 P2P 重试时日志过多 (distributed#8511) Hendrik Makait
防止 retire_workers 参数中出现拼写错误 (distributed#8524) crusaderky
test_steal 的清理 (回溯 #8185) (distributed#8509) crusaderky
修复不稳定的 test_compute_per_key (distributed#8521) crusaderky
修复不稳定的 test_no_workers_timeout_queued (distributed#8523) crusaderky
2024.2.1¶
发布于 2024 年 2 月 23 日
亮点¶
允许静默 dask.DataFrame 弃用警告¶
上一个版本包含一个 DeprecationWarning,它提醒用户 dask.dafaframe 即将切换到支持查询规划的新后端(详见 dask#10934)。
此 DeprecationWarning 在导入 dask.dataframe 模块时触发,社区对此过于冗长表示担忧。
现在可以静默此警告:
# via Python
>>> dask.config.set({'dataframe.query-planning-warning': False})
# via CLI
dask config set dataframe.query-planning-warning False
详见 dask#10936 和 dask#10925 (由 Miles 提交) 了解详情。
针对罕见键冲突的更健壮的分布式调度器¶
块式融合优化可能导致任务键冲突,分布式调度器未能正确处理(详见 dask#9888)。用户通常会通过看到导致系统死锁或关键故障的各种内部异常之一来注意到这一点。虽然此问题无法修复,但调度器现在实现了一种机制,可以缓解大多数情况,并在检测到问题时发出警告。
详见 distributed#8185 (由 crusaderky 和 Florian Jetter 提交) 了解详情。
在此过程中,对 tokenization 进行了各种改进。详见 dask#10913, dask#10884, dask#10919, dask#10896,以及主要由 crusaderky 提交的 dask#10883 了解更多详情。
在大型集群上更健壮的自适应扩缩容¶
以前,如果在缩减时需要移动大量任务,自适应扩缩容可能会丢失数据。这通常(但不限于)发生在大型集群上,表现为任务的重新计算,可能导致集群在扩容和缩减之间振荡而永远无法完成。
详见 distributed#8522 (由 crusaderky 提交) 了解更多详情。
其他变更
移除不稳定的 fastparquet 测试 (dask#10948) Patrick Hoefler
启用 dask-expr 中的 Aggregation (dask#10947) Patrick Hoefler
为 dask-expr 中的 assign 更改更新测试 (dask#10944) Patrick Hoefler
调整 pandas large string 更改 (dask#10942) Patrick Hoefler
修复不稳定的 test_describe_empty (dask#10943) crusaderky
使用 Python 3.12 作为参考环境 (dask#10939) crusaderky
[装饰性] 清理 test_config.py 中的临时路径 (dask#10938) crusaderky
[CLI]
dask config set和dask config find更新 (dask#10930) Miles当 chunk 只包含 NaN 时 combine_first (dask#10932) crusaderky
正确解析 CLI 中小写 true/false 配置 (dask#10926) crusaderky
修复打印 None 值时
dask config get的问题 (dask#10927) crusaderkyquery-planning 不能是 None (dask#10928) crusaderky
添加
dask config set(dask#10921) Miles让 nunique 再次变快 (dask#10922) Patrick Hoefler
清理一些 Cython 警告处理 (dask#10924) crusaderky
将 pre-commit/action 从 3.0.0 升级到 3.0.1 (dask#10920)
Raise 并避免 meta 提供给 P2P shuffle 错误时数据丢失 (distributed#8520) Florian Jetter
修复 gpuci: np.product 已弃用 (distributed#8518) crusaderky
将 gpuCI
RAPIDS_VER更新到24.04(distributed#8471)在 Python 3.12 上取消 pin ipywidgets (distributed#8516) crusaderky
在 run_spec 冲突时保留旧依赖项 (distributed#8512) crusaderky
简单的 mypy 修复 (distributed#8513) crusaderky
确保大型 payload 可以序列化并通过 comms 发送 (distributed#8507) Florian Jetter
允许配置大型图警告阈值 (distributed#8508) Florian Jetter
与 Tokenization 相关的测试调整 (回溯 #8185) (distributed#8499) crusaderky
update_graph调整 (回溯 #8185) (distributed#8498) crusaderkyAMM: 测试增量退役 (distributed#8501) crusaderky
在 CI 中抑制 dask-expr 警告 (distributed#8505) crusaderky
在 CI 中忽略 dask-expr 警告 (distributed#8504) James Bourbeau
改进 P2P stable ordering 的测试 (distributed#8458) Hendrik Makait
将 pre-commit/action 从 3.0.0 升级到 3.0.1 (distributed#8503)
2024.2.0¶
发布于 2024 年 2 月 9 日
亮点¶
弃用 Dask DataFrame 实现¶
当前的 Dask DataFrame 实现已被弃用。在未来的版本中,Dask DataFrame 将使用包含多项改进(包括逻辑查询规划)的新实现。面向用户的 DataFrame API 将保持不变。
新实现已可用,可通过安装 dask-expr 库来启用
$ pip install dask-expr
并开启查询规划选项
>>> import dask
>>> dask.config.set({'dataframe.query-planning': True})
>>> import dask.dataframe as dd
新实现的 API 文档可在 https://docs.dask.org.cn/en/stable/dataframe-api.html 查看。
任何反馈都可以在 Dask 问题跟踪器 https://github.com/dask/dask/issues 上报告。
详见 dask#10912 (由 Patrick Hoefler 提交) 了解详情。
改进的 tokenization¶
此版本包含 Dask 对象 tokenization 逻辑的多项改进。现在有更多对象生成确定性的 tokens,这可以通过缓存中间结果来提高性能。
详见 dask#10898, dask#10904, dask#10876, dask#10874, 和 dask#10865 (由 crusaderky 提交) 了解详情。
其他变更
修复字符串转换时对只读数组进行原地修改的问题 (dask#10886) Patrick Hoefler
为
dask-expr添加变更日志条目 (dask#10915) Patrick Hoefler修复
cudf的leftsemi合并问题 (dask#10914) Patrick Hoefler略微更新
dask-expr警告 (dask#10916) James Bourbeau提高
groupby.nunique的性能 (dask#10910) Patrick Hoefler为
dask-expr中的leftsemi合并添加配置 (dask#10908) Patrick Hoefler调整
dask-expr的 assign 测试 (dask#10907) Patrick Hoefler在 GPU CI 中避免
test_to_datetime中的pytest.warns(dask#10902) Richard (Rick) Zamora更新文档主页中的部署选项 (dask#10901) James Bourbeau
修复 dataframe 文档中的拼写错误 (dask#10900) Matthew Rocklin
将
peter-evans/create-pull-request从 5 升级到 6 (dask#10894)修复 mimesis API
>=13.1.0- 使用random.randint(dask#10888) Miles调整无效测试 (dask#10897) Patrick Hoefler
Pickle
da.argwhere和da.count_nonzero(dask#10885) crusaderky修复 singleton pr 后的
dask-expr测试 (dask#10892) Patrick Hoefler为
s3fs设置下限版本 (dask#10889) Miles为新的 parquet 缓存添加几个
dask-expr修复 (dask#10880) Florian Jetter更新部署文档 (dask#10882) Matthew Rocklin
开始构建
dask-expr文档 (dask#10879) Patrick Hoefler测试静态方法和类方法的 tokenization (dask#10872) crusaderky
将
distributed.print和distributed.warn添加到 API 文档 (dask#10878) James Bourbeau在 M1 架构上运行 macos ci (dask#10877) Patrick Hoefler
更新
dask-expr测试 (dask#10838) Patrick Hoefler更新 parquet 测试以与
dask-expr修复保持一致 (dask#10851) Richard (Rick) Zamora修复
test_graph_manipulation中的回归 (dask#10873) crusaderky为 dask-expr ci 调整
pytest错误 (dask#10871) Patrick Hoefler当
pandas<2.1时,为numba设置上限版本 (dask#10890) Miles弃用
DataFrame.fillna中的method参数 (dask#10846) Miles从
pyproject.toml中移除警告过滤器 (dask#10867) Patrick Hoefler跳过 fastparquet 的
test_append_with_partition(dask#10828) Patrick Hoefler修复
pytest8 的问题 (dask#10868) Patrick Hoefler调整测试以支持
dask-expr中Groupby.aggregate对median的支持 (2/2) (dask#10870) Hendrik Makait在
sort_values中允许 ascending 的长度大于一 (dask#10864) Florian Jetter允许在 Python 3.9 中抛出其他消息 (dask#10862) Hendrik Makait
在病态情况下获取计算代码时不要崩溃 (distributed#8502) James Bourbeau
将
peter-evans/create-pull-request从 5 升级到 6 (distributed#8494)修复
cudfspilling metrics 测试 (distributed#8478) Mads R. B. Kristensen升级到
pytest8 (distributed#8482) crusaderky修复
test_two_consecutive_clients_share_results(distributed#8484) crusaderky客户端单词混淆 (distributed#8481) templiert
2024.1.1¶
发布于 2024 年 1 月 26 日
亮点¶
支持 Pandas 2.2 和 Scipy 1.12¶
此版本包含对最新 pandas 和 scipy 版本的兼容性更新。
详见 dask#10834, dask#10849, dask#10845, 和 distributed#8474 (由 crusaderky 提交) 了解详情。
弃用项¶
弃用
apply中的convert_dtype(dask#10827) Miles弃用
DataFrame.rolling中的axis(dask#10803) Miles在大多数 DataFrame 方法中弃用
out=和dtype=参数 (dask#10800) crusaderky弃用
groupby累积变换器中的axis(dask#10796) Miles在剩余方法中将
shuffle重命名为shuffle_method(dask#10797) Miles
其他变更
在部署文档中添加推荐的部署选项 (dask#10866) James Bourbeau
改进
_agg_finalize以符合输出预期 (dask#10835) Hendrik Makait实现 hlg 的确定性 tokenization (dask#10817) Patrick Hoefler
重构:将
tokenize()的测试移到其自己的模块 (dask#10863) crusaderky更新 DataFrame 示例部分 (dask#10856) James Bourbeau
暂时 pin
mimesis<13.1.0(dask#10860) James Bourbeau对
_testing.py进行简单的装饰性调整 (dask#10857) crusaderky取消跳过并调整使用
dask-expr对median进行groupby-aggregate 的测试 (dask#10832) Hendrik Makait修复上游 CI 中
sizeof(pd.MultiIndex)的测试 (dask#10850) crusaderkynumpy2.0: 修复通过uint64数组进行切片的问题 (dask#10854) crusaderky重命名
numpy版本常量以匹配pandas(dask#10843) crusaderky将
actions/cache从 3 升级到 4 (dask#10852)将 gpuCI
RAPIDS_VER更新到24.04(dask#10841)修复 doctest 中的弃用问题 (dask#10844) crusaderky
在
numpy2.x 中更改dtype算术 (dask#10831) crusaderky调整测试以支持
dask-expr中的median支持 (dask#10839) Patrick Hoefler调整测试以支持
dask-expr中groupby-aggregate对median的支持 (dask#10840) Hendrik Makaitnumpy2.x: 修复MaskedArray上的std()问题 (dask#10837) crusaderky如果测试失败,则使
dask-exprci 失败 (dask#10829) Patrick Hoefler导出测试时激活
query_planning(dask#10833) Patrick Hoefler暴露 dataframe 测试 (dask#10830) Patrick Hoefler
numpy2: n 维fft函数中的弃用 (dask#10821) crusaderky为
dask-expr泛化CreationDispatch(dask#10794) Richard (Rick) Zamora启用
dask-expr时移除循环导入 (dask#10824) MilesMinor[CI]:
publish-test-results未标记为失败 (dask#10825) Miles修复更多使用
pytest.warns()的测试 (dask#10818) Michał Górnynp.unique(): 在numpy2 中 inverse 已整形 (dask#10819) crusaderky将
test_split_adaptive_files锁定到pyarrow引擎 (dask#10820) Patrick Hoefler调整
dask/dask中剩余的测试 (dask#10813) Patrick Hoefler将测试限制为仅使用 Arrow (dask#10814) Patrick Hoefler
过滤来自
std测试的警告 (dask#10815) Patrick Hoefler主要调整索引测试 (dask#10790) Patrick Hoefler
更新部署文档 (dask#10778) Sarah Charlotte Johnson
解除文档构建的阻塞 (dask#10807) Miles
调整
test_to_datetime以兼容dask-exprHendrik Makait上游 CI 微调 (dask#10806) crusaderky
改进
to_numeric的测试 (dask#10804) Hendrik Makait修复测试报告缓存键缩进 (dask#10798) Miles
添加测试报告工作流程 (dask#10783) Miles
处理矩阵子类序列化 (distributed#8480) Florian Jetter
在 P2P 中对分区列使用最小的数据类型 (distributed#8479) Florian Jetter
pandas2.2: 修复test_dataframe_groupby_tasks(distributed#8475) crusaderky将
actions/cache从 3 升级到 4 (distributed#8477)pandas2.2 对比pyarrow14: 废弃的DatetimeTZBlock(distributed#8476) crusaderkypandas2.2.0: 废弃了频率别名M,推荐使用ME(distributed#8473) Hendrik Makait修复文档构建 (distributed#8472) Hendrik Makait
修复带有显式
npartitions的 P2P 合并 (distributed#8470) Hendrik Makait在
test_report.py脚本中忽略dask-expr(distributed#8464) Miles细微调整:在测试报告环境中硬编码 Python 版本 (distributed#8462) crusaderky
更改
test_report.py- 跳过dask/dask中不好的构件 (distributed#8461) Miles替换所有出现的
sys.is_finalizing(distributed#8449) Florian Jetter
2024.1.0¶
发布于 2024 年 1 月 12 日
亮点¶
P2P 内的部分重新分块¶
P2P 重新分块现在利用了输入和输出块之间的关系。对于不需要全对全数据传输的情况,这可以显著减少运行时间和内存/磁盘占用。它还支持任务裁剪。
详情请参阅 distributed#8330,由 Hendrik Makait 贡献。
Fastparquet 引擎已废弃¶
fastparquet Parquet 引擎已被废弃。用户应迁移到 pyarrow 引擎,方法是安装 PyArrow 并在 read_parquet 或 to_parquet 调用中移除 engine="fastparquet"。
详情请参阅 dask#10743,由 crusaderky 贡献。
改进了任意数据的序列化¶
此版本提高了任意数据的序列化健壮性。以前在某些情况下,对于非 msgpack 可序列化的数据,序列化可能会失败。在这些情况下,我们现在回退到使用 pickle。
详情请参阅 dask#8447,由 Hendrik Makait 贡献。
额外废弃项¶
废弃 DataFrame 方法中的
shuffle关键字,推荐使用shuffle_method(dask#10738) Hendrik Makait废弃
repartition中的自动参数推断 (dask#10691) Patrick Hoefler废弃
set_index中的compute参数 (dask#10784) Miles废弃
eval中的inplace(dask#10785) Miles废弃
Series.view(dask#10754) Miles废弃
set_index和sort_values的npartitions="auto"(dask#10750) Miles
其他变更
避免任务 shuffle 中的快捷方式导致数据丢失 (dask#10763) Patrick Hoefler
排序时忽略数据任务 (dask#10706) Florian Jetter
从
dask-expr添加get_dummies(dask#10791) Patrick Hoefler调整 IO 测试以适应
dask-expr迁移 (dask#10776) Patrick Hoefler移除关于
groupby中sort和split_out的废弃警告 (dask#10788) Patrick Hoefler处理
pandas废弃项 (dask#10789) Patrick Hoefler在
get_scheduler中只导入distributed一次 (dask#10771) Florian Jetter简化 GitHub actions (dask#10781) crusaderky
添加单元测试概览 (dask#10769) Miles
清理 CI 中冗余的部分 (dask#10768) crusaderky
更新
ufunc的测试 (dask#10773) Patrick Hoefler使用
pytest.mark.skipif(DASK_EXPR_ENABLED)(dask#10774) crusaderky调整 shuffle 测试以兼容
dask-expr(dask#10759) Patrick Hoefler修复来自
pandas的一些废弃警告 (dask#10749) Patrick Hoefler调整 shuffle 测试以兼容
dask-expr(dask#10762) Patrick Hoefler更新
pre-commit(dask#10767) Hendrik Makait清理 CI 中的配置开关 (dask#10766) crusaderky
改进
validate_key的异常处理 (dask#10765) Hendrik Makait处理
set_index中带有未知划分的datetimeindexes(dask#10757) Patrick Hoefler添加 decimals 的哈希计算 (dask#10758) Patrick Hoefler
审查
is_monotonic的测试 (dask#10756) crusaderky更改
value_counts_aggregate中的参数顺序 (dask#10751) Patrick Hoefler调整一些 groupby 测试以兼容
dask-expr(dask#10752) Patrick Hoefler将 mimesis 限制在
< 12以进行 3.9 构建 (dask#10755) Patrick Hoefler不在跳过条件中评估配置 (dask#10753) Patrick Hoefler
调整一些测试以兼容
dask-expr(dask#10714) Patrick Hoefler使
dask.array.utils函数更通用以适用于其他 Dask Arrays (dask#10676) Matthew Rocklin移除重复的“单机”部分 (dask#10747) Matthew Rocklin
调整 ORC
engine=参数 (dask#10746) crusaderky为 pandas 3.0 废弃项和
dask-expr迁移准备添加内容 (dask#10723) Miles在文档主页添加任务图动画 (dask#10730) Sarah Charlotte Johnson
使用新的 Xarray logo (dask#10729) James Bourbeau
更新“Dask 十分入门”页面上的 Tab 样式 (dask#10728) James Bourbeau
更新 CI 中的环境文件上传步骤 (dask#10726) James Bourbeau
如果
split_out>1,不要在 GroupBy.nunique 中复制未观测到的分类 (dask#10716) Patrick Hoefler用于更新
dask.order的更新日志条目 (dask#10715) Florian Jetter放宽
_check_dsk中的冗余键检查 (dask#10701) Richard (Rick) Zamora修复
test_report.py(distributed#8459) Miles恢复
pickle更改 (distributed#8456) Florian Jetter调整
test_report.py以支持dask/dask仓库 (distributed#8450) Miles为 P2P shuffle 保持稳定的排序 (distributed#8453) Hendrik Makait
为调度器添加无 worker 超时 (distributed#8371) FTang21
允许由维护者手动分派测试工作流程 (distributed#8445) Erik Sundell
将调度器相关的转换功能设为私有 (distributed#8448) Hendrik Makait
更新
pre-commit钩子 (distributed#8444) Hendrik Makaitpickling 时不要总是检查
__main__ in result(distributed#8443) Florian Jetter仅在实现时将
wait_for_workers委托给集群实例 (distributed#8441) Erik Sundell延长
test_pandas中的休眠时间 (distributed#8440) Julian Gilbey避免使用废弃的
shuffle关键字 (distributed#8439) Hendrik MakaitShuffle 指标 4/4: 移除定制诊断 (distributed#8367) crusaderky
不要在测试套件中运行
gilknocker(distributed#8423) Florian Jetter调整
abstractmethods(distributed#8427) crusaderkyShuffle 指标 3/4: 捕获后台指标 (distributed#8366) crusaderky
Shuffle 指标 2/4: 添加后台指标 (distributed#8365) crusaderky
Shuffle 指标 1/4: 添加前台指标 (distributed#8364) crusaderky
将
actions/upload-artifact从 3 升级到 4 (distributed#8420)修复
test_merge_p2p_shuffle_reused_dataframe_with_different_parameters(distributed#8422) Hendrik Makait扩展
Client.upload_file文档示例 (distributed#8313) Miles改进 P2P 调度器插件中的日志记录 (distributed#8410) Hendrik Makait
重新启用
test_decide_worker_coschedule_order_neighbors(distributed#8402) Florian Jetter将 cuDF 溢出统计信息添加到 RMM/GPU 内存图表 (distributed#8148) Charles Blackmon-Luca
修复 Nanny 启动的 workers 的哈希不一致问题 (distributed#8400) Charles Stern
如果 workers 正在运行耗时任务 (例如
worker_client),不允许其下扩 (distributed#7481) Florian Jetter修复不稳定的
test_subprocess_cluster_does_not_depend_on_logging(distributed#8417) crusaderky
2023.12.1¶
发布于 2023 年 12 月 15 日
亮点¶
Dask DataFrame 现已支持逻辑查询计划¶
Dask DataFrame 通过使用逻辑查询规划器,现在性能显著提升。此功能目前默认关闭,但可以通过以下方式开启:
dask.config.set({"dataframe.query-planning": True})
您还需要安装 dask-expr
pip install dask-expr
我们已经看到有希望的性能改进,更多信息请参阅 这篇博文 和这些定期更新的基准测试。关于查询优化器工作原理的更详细解释可以在 这篇博文 中找到。
此功能仍在积极开发中,API 尚未稳定,因此可能会发生重大更改。我们预计明年初将查询优化器设为默认选项。
详情请参阅 dask#10634,由 Patrick Hoefler 贡献。
read_parquet 中的 Dtype 推断¶
read_parquet 现在将把 Arrow 类型 pa.date32(), pa.date64() 和 pa.decimal() 推断为 pandas 中的 ArrowDtype。这些 dtypes 由原始 Arrow 数组支持,因此避免了转换为 NumPy object。此外,read_parquet 将不再将嵌套和二进制类型推断为字符串,它们将存储在 NumPy object 数组中。
详情请参阅 dask#10698 和 dask#10705,由 Patrick Hoefler 贡献。
改进调度以减少内存使用¶
此版本包括对我们调度逻辑核心部分的重大重写。它包括 dask.order 中拓扑排序算法的新方法,该方法确定任务的运行顺序。已知不当的排序是导致集群内存压力过大的主要因素。
此版本中的更新修复了 2023.10.0 版本中引入的一些性能回退(参阅 dask#10535)。通常,如果数据不再需要存在于内存中,计算现在会更积极地释放数据。
详情请参阅 dask#10660 和 dask#10697,由 Florian Jetter 贡献。
改进了基于 P2P 的合并健壮性和性能¶
此版本包含多项更新,修复了 2023.9.2 中引入的可能死锁问题,并提高了集群动态扩容时基于 P2P 合并的健壮性。
详情请参阅 distributed#8415, distributed#8416, 和 distributed#8414,由 Hendrik Makait 贡献。
移除禁用 pickle 选项¶
distributed.scheduler.pickle 配置选项不再支持。从 2023.4.0 版本开始,pickle 用于传输任务图,因此无法再禁用。当 distributed.scheduler.pickle 设置为 False 时,我们现在会抛出一个信息性错误。
详情请参阅 distributed#8401,由 Florian Jetter 贡献。
其他变更
为最近的 P2P 合并修复添加更新日志条目 (dask#10712) Hendrik Makait
更新 DataFrame 页面 (dask#10710) Matthew Rocklin
为
dask-expr开关添加更新日志条目 (dask#10704) Patrick Hoefler改进
PipInstall更改的更新日志条目 (dask#10711) Hendrik Makait移除 PR labeler (dask#10709) James Bourbeau
为
Delayed对象添加.__wrapped__(dask#10695) Andrew S. Rosen将
actions/labeler从 4.3.0 升级到 5.0.0 (dask#10689)将
actions/stale从 8 升级到 9 (dask#10690)[Dask.order] 从排序中移除不可运行的叶节点 (dask#10697) Florian Jetter
更新安装文档 (dask#10699) Matthew Rocklin
修复文档中的软件环境链接 (dask#10700) James Bourbeau
避免将非字符串转换为 arrow 字符串用于 read_parquet (dask#10692) Patrick Hoefler
将
xarray-contrib/issue-from-pytest-log从 1.2.7 升级到 1.2.8 (dask#10687)修复
pd.DateOffset的tokenize(dask#10664) jochenott写入空数组到 zarr 的 Bugfix (dask#10506) Ben
文档更新,修复样式,提及 free (dask#10679) Matthew Rocklin
更新部署文档 (dask#10680) Matthew Rocklin
使用关键路径方法重写 Dask.order (dask#10660) Florian Jetter
避免替换多次出现的键 (dask#10646) Florian Jetter
在文档中添加缺失的图片 (dask#10694) Matthew Rocklin
将
actions/setup-python从 4 升级到 5 (dask#10688)更新 landing 页面 (dask#10674) Matthew Rocklin
在 dispatch 中简化元信息检查 (dask#10638) Patrick Hoefler
锁定 PR Labeler (dask#10675) Matthew Rocklin
稍微重新组织文档索引 (dask#10669) Matthew Rocklin
将
actions/setup-java从 3 升级到 4 (dask#10667)将
conda-incubator/setup-miniconda从 2.2.0 升级到 3.0.1 (dask#10668)将
xarray-contrib/issue-from-pytest-log从 1.2.6 升级到 1.2.7 (dask#10666)使用 nightly
pyarrow修复test_categorize_info(dask#10662) James Bourbeau重写
test_subprocess_cluster_does_not_depend_on_logging(distributed#8409) Hendrik Makait当 pickling
SpillBuffer中的 key 失败并使用tblib=3时,避免RecursionError(distributed#8404) Hendrik Makait允许任务覆盖
is_rootish启发式算法 (distributed#8412) Hendrik Makait移除 GPU 执行器 (distributed#8399) Hendrik Makait
subprocess cluster 不要依赖日志记录 (distributed#8398) Hendrik Makait
更新 gpuCI
RAPIDS_VER到24.02(distributed#8384)将
actions/setup-python从 4 升级到 5 (distributed#8396)确保 P2P rechunking 中的输出块均匀分布 (distributed#8207) Florian Jetter
小调整:修复拼写错误 (distributed#8395) crusaderky
将
JamesIves/github-pages-deploy-action从 4.4.3 升级到 4.5.0 (distributed#8387)将
conda-incubator/setup-miniconda从 3.0.0 升级到 3.0.1 (distributed#8388)
2023.12.0¶
发布于 2023 年 12 月 1 日
亮点¶
PipInstall 重启和环境变量¶
distributed.PipInstall 插件现在具有更健壮的重启逻辑,并且还支持环境变量。
下面展示了用户如何使用 distributed.PipInstall 插件和 TOKEN 环境变量来安全地从私有仓库安装包
from dask.distributed import PipInstall
plugin = PipInstall(packages=["private_package@git+https://${TOKEN}@github.com/dask/private_package.git])
client.register_plugin(plugin)
详情请参阅 distributed#8374, distributed#8357, 和 distributed#8343,由 Hendrik Makait 贡献。
Bokeh 3.3.0 兼容性¶
此版本包含使用 bokeh>=3.3.0 与代理 Dask dashboards 的兼容性更新。之前 dashboard plots 的内容不会显示。
详情请参阅 distributed#8347 和 distributed#8381,由 Jacob Tomlinson 贡献。
其他变更
为
test_pyarrow_filesystem_option_real_data添加network标记 (dask#10653) Richard (Rick) Zamora将 GPU CI 提升到 CUDA 11.8 (dask#10656) Charles Blackmon-Luca
确定性地对
pandas偏移量进行 tokenize (dask#10643) Patrick Hoefler添加 tokenize
pd.NA功能 (dask#10640) Patrick Hoefler更新 gpuCI
RAPIDS_VER到24.02(dask#10636)修复
array.linalg.norm中的精度处理 (dask#10556) joanrue为
DataFrame.clip和Series.clip添加axis参数 (dask#10616) Richard (Rick) Zamora更新内存中 rechunking 的更新日志条目 (dask#10630) Florian Jetter
修复不稳定的
test_resources_reset_after_cancelled_task(distributed#8373) crusaderky将 GPU CI 提升到 CUDA 11.8 (distributed#8376) Charles Blackmon-Luca
将
conda-incubator/setup-miniconda从 2.2.0 升级到 3.0.0 (distributed#8372)向 P2P 调度器插件添加调试日志 (distributed#8358) Hendrik Makait
O(1)访问/info/task/端点 (distributed#8363) crusaderky移除 shuffle 注解中的字符串化 (distributed#8362) crusaderky
不要将
int指标强制转换为float(distributed#8361) crusaderky移除 asyncio TCP 后端 (distributed#8355) Florian Jetter
为
context_meter.add_callback添加 offload 支持 (distributed#8360) crusaderky测试
sync()是否传播 contextvars (distributed#8354) crusaderkycaptured_context_meter(distributed#8352) crusaderkycontext_meter.clear_callbacks(distributed#8353) crusaderky使用
@log_errors装饰器 (distributed#8351) crusaderky修复
test_statistical_profiling_cycle(distributed#8356) Florian JetterShuffle: 不要在每次 RPC 时解析 dask.config (distributed#8350) crusaderky
将
Client.register_plugin的idempotent参数替换为插件上的.idempotent属性 (distributed#8342) Hendrik Makait修复测试报告生成 (distributed#8346) Hendrik Makait
在
mindeps-pandasCI 上安装pyarrow-hotfix(distributed#8344) Hendrik Makait减少调度器进程的内存使用 - 优化
scheduler.py::TaskState类 (distributed#8331) Miles升级
pre-commitlinters (distributed#8340) crusaderky使用显式
dtype=object更新 cuDF 测试 (distributed#8339) Peter Andreas Entschev修复
Cluster/SpecCluster调用异步 close 方法 (distributed#8327) Peter Andreas Entschev
2023.11.0¶
发布于 2023 年 11 月 10 日
亮点¶
零拷贝 P2P 数组重新分块¶
在使用内存中 P2P 数组重新分块时,用户应看到显著的性能提升。这是由于不再复制底层数据缓冲区。
下面展示了一个简单的示例,我们比较了不同 rechunking 方法的性能。
shape = (30_000, 6_000, 150) # 201.17 GiB
input_chunks = (60, -1, -1) # 411.99 MiB
output_chunks = (-1, 6, -1) # 205.99 MiB
arr = da.random.random(size, chunks=input_chunks)
with dask.config.set({
"array.rechunk.method": "p2p",
"distributed.p2p.disk": True,
}):
(
da.random.random(size, chunks=input_chunks)
.rechunk(output_chunks)
.sum()
.compute()
)
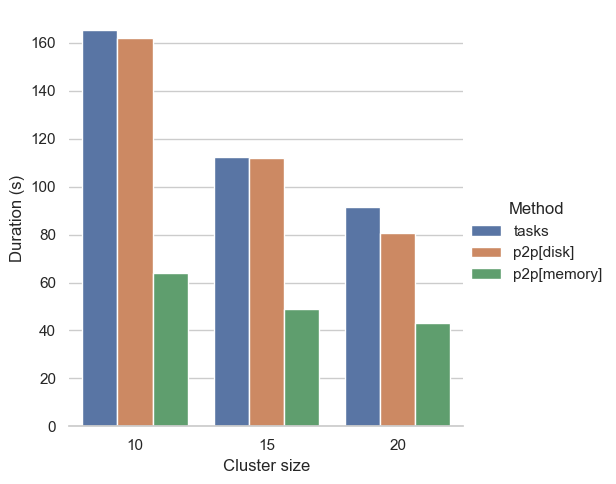
详情请参阅 distributed#8282, distributed#8318, distributed#8321,由 crusaderky 贡献;以及 (distributed#8322),由 Hendrik Makait 贡献。
废弃 PyArrow <14.0.1¶
从本版本开始废弃使用 pyarrow<14.0.1。建议所有用户升级他们的 pyarrow 版本或安装 pyarrow-hotfix。详情请参阅 此 CVE。
详情请参阅 dask#10622,由 Florian Jetter 贡献。
改进 Parquet 的 PyArrow 文件系统¶
读取 Parquet 数据集时使用 filesystem="arrow" 现在可以正确推断访问远程、云托管数据时的正确云区域。
详情请参阅 dask#10590,由 Richard (Rick) Zamora 贡献。
改进 P2P Shuffling 中的类型协调¶
详情请参阅 distributed#8332,由 Hendrik Makait 贡献。
其他变更
修复
test_dataframe::test_quantile的偶发失败 (dask#10625) Miles将最低
click版本提升到>=8.1(dask#10623) Jacob Tomlinson重构
test_quantile(dask#10620) Miles避免 fragmented DataFrame 的
PerformanceWarning(dask#10621) Patrick Hoefler在 GPU CI 更新工作流程中泛化
NEW_*_VER的计算 (dask#10610) Charles Blackmon-Luca切换到较新的 GPU CI 镜像 (dask#10608) Charles Blackmon-Luca
移除
fsspec测试中的双斜杠 (dask#10605) Mario Šaško重新启用
test_ucx_config_w_env_var(distributed#8272) Peter Andreas Entschev从网络接收时不要共享
host_array(distributed#8308) crusaderky在 GPU CI 更新工作流程中泛化
NEW_*_VER的计算 (distributed#8319) Charles Blackmon-Luca切换到较新的 GPU CI 镜像 (distributed#8316) Charles Blackmon-Luca
shuffle dashboard 的微小更新 (distributed#8315) Matthew Rocklin
不要使用
bytearray().join(distributed#8312) crusaderky在 P2P hash join 中重用相同的 shuffle (distributed#8306) Hendrik Makait
2023.10.1¶
发布于 2023 年 10 月 27 日
亮点¶
Python 3.12¶
此版本添加了对 Python 3.12 的官方支持。
详情请参阅 dask#10544 和 distributed#8223,由 Thomas Grainger 贡献。
其他变更
避免过于激进地将 parquet 文件拆分为行组 (dask#10600) Matthew Rocklin
加快常见情况下的
normalize_chunks(dask#10579) Martin Durantupstream 和 doctests CI 构建使用 Python 3.11 (dask#10596) Thomas Grainger
将
actions/checkout从 4.1.0 升级到 4.1.1 (dask#10592)切换到 PyTables
HEAD(dask#10580) Thomas Grainger移除
numpy.core警告过滤器,链接到pyarrow引起的BlockManager警告的问题 (dask#10571) Thomas Grainger取消忽略并修复废弃的 freq 别名 (dask#10577) Thomas Grainger
将
register_assert_rewrite移到conftest中更早的位置以修复警告 (dask#10578) Thomas Grainger将
versioneer升级到 0.29 (dask#10575) Thomas Grainger更改
test_concat_categorical为非严格模式 (dask#10574) Thomas Grainger使用 NumPy 2.0 启用 SciPy 测试 Thomas Grainger
使用 NumPy 2.0 启用 scikit-image 测试 (dask#10569) Thomas Grainger
修复 upstream 构建 (dask#10549) Thomas Grainger
为
drop_duplicates添加优化代码路径 (dask#10542) Richard (Rick) Zamora在
dd.DataFrame.sort_values中支持cudf后端 (dask#10551) Richard (Rick) Zamora在图表标签中将“GIL Contention”重命名为 GIL (distributed#8305) Matthew Rocklin
将
actions/checkout从 4.1.0 升级到 4.1.1 (distributed#8299)修复 dashboard (distributed#8293) Hendrik Makait
异步任务使用
@log_errors装饰器 (distributed#8294) crusaderkyserialize_bytes 的注解和更好测试 (distributed#8300) crusaderky
临时将
test_decide_worker_coschedule_order_neighbors标记为 xfail 以解除 CI 阻塞 (distributed#8298) James Bourbeau在代码示例中跳过
xdist和matplotlib(distributed#8290) Matthew Rocklinnumpy>=2.dev0时使用numpy._core(distributed#8291) Thomas Grainger修复
MemoryShardsBuffer.bytes_read的计算 (distributed#8289) crusaderky允许 P2P 在内存中存储数据 (distributed#8279) Hendrik Makait
将
versioneer升级到 0.29 (distributed#8288) Thomas Grainger允许
ResourceLimiter无限制 (distributed#8276) Hendrik Makait运行
pre-commit自动更新 (distributed#8281) Thomas Grainger为 P2P 层注解实例变量 (distributed#8280) Hendrik Makait
优雅地移除 worker 不应将任务标记为可疑 (distributed#8234) Thomas Grainger
为
dask spec添加信号处理 (distributed#8261) Thomas Grainger为
sync添加类型提示 (distributed#8275) Hendrik Makait改进 shuffle offload 的注解 (distributed#8277) crusaderky
测试 p2p shuffle 的最低版本 (distributed#8270) crusaderky
在测试失败时运行 coverage (distributed#8269) crusaderky
使用带有扩展的
aiohttp(distributed#8274) Thomas Grainger
2023.10.0¶
发布于 2023 年 10 月 13 日
亮点¶
减少多数组规约的内存压力¶
此版本包含对 Dask 任务图调度逻辑核心部分的重大更新。此处的更新显著减少了数组规约的内存压力。我们预计这将对数组计算社区产生强烈影响。
详情请参阅 dask#10535 (作者:Florian Jetter)。
改进的 P2P Shuffle 稳健性¶
以下列出了几项更新,它们使得 P2P Shuffle 更加稳健,失败的可能性更低。
详情请参阅 distributed#8262、distributed#8264、distributed#8242、distributed#8244 和 distributed#8235 (作者:Hendrik Makait),以及 distributed#8124 (作者:Charles Blackmon-Luca)。
减少大型图的调度器 CPU 负载¶
用户在计算大型任务图时,应该会发现其调度器的 CPU 负载降低了。
详情请参阅 distributed#8238 和 dask#10547 (作者:Florian Jetter),以及 distributed#8240 (作者:crusaderky)。
其他变更
分派用于磁盘 Shuffle 的
partd.Encode类 (dask#10552) Richard (Rick) Zamora添加关于 Hive 分区的文档 (dask#10454) Richard (Rick) Zamora
添加
dask.order的类型提示 (dask#10553) Florian Jetter允许在
dd.read_csv中传递index_col=False(dask#9961) Michael Leslie收紧
HighLevelGraph注解 (dask#10524) crusaderky支持最新的
ipykernel/ipywidgets(distributed#8253) crusaderky检查 P2P 合并所需的最低
pyarrow版本 (distributed#8266) Hendrik Makait支持 Python 3.12 (distributed#8223) Thomas Grainger
在警告大型图发送时使用
memoryview.nbytes(distributed#8268) crusaderky运行测试时排除
gilknocker(distributed#8263) crusaderky在 MacOS CI 上禁用 ipv6 (distributed#8254) crusaderky
清理冗余的最低版本要求 (distributed#8251) crusaderky
清理调度器插件中
BARRIER_PREFIX的使用 (distributed#8252) crusaderky改进 P2P 工作进程插件中的 Shuffle 运行处理 (distributed#8245) Hendrik Makait
显式设置
charset=utf-8(distributed#8250) crusaderky对 distributed#8239 的类型提示调整 (distributed#8247) crusaderky
简化调度器断言 (distributed#8246) crusaderky
改进类型提示 (distributed#8239) Hendrik Makait
遵守 cgroups v2 的“low”内存限制 (distributed#8243) Samantha Hughes
通过将其变为调度器插件来修复
PackageInstall(distributed#8142) Hendrik Makait将
test_ucx_config_w_env_var标记为预期失败 (distributed#8241) crusaderkySpecCluster对故障工作进程的弹性 (distributed#8233) crusaderky抑制取消任务的
SpillBuffer堆栈跟踪 (distributed#8232) crusaderky在字符串化更改后更新注解 (distributed#8195) crusaderky
减少配置文件的最大递归深度 (distributed#8224) crusaderky
卸载深度嵌套的对象 (distributed#8214) crusaderky
修复不稳定的
test_close_connections(distributed#8231) crusaderky修复不稳定的
test_popen_timeout(distributed#8229) crusaderky修复不稳定的
test_adapt_then_manual(distributed#8228) crusaderky防止
SpillBuffer中的冲突 (distributed#8226) crusaderky允许
retire_workers并行运行 (distributed#8056) Florian Jetter修复
TaskState对象的 HTML repr (distributed#8188) Florian Jetter修复在
profile.py中出现的builtin_function_or_method的AttributeError(distributed#8181) Florian Jetter修复不稳定的
test_spans(v2) (distributed#8222) crusaderky
2023.9.3¶
发布于 2023 年 9 月 29 日
亮点¶
恢复之前的配置覆盖行为¶
2023.9.2 版本引入了非预期的破坏性更改,影响了在 dask.config.get 中使用 override_with= 关键字覆盖配置选项的方式(参见 dask#10519)。本次发布恢复了之前的行为。
详情请参阅 dask#10521 (作者:crusaderky)。
Dask Array Reduction 中的复数 dtype¶
本次发布改进了对在 Dask Array 中使用常见 Reduction(例如 var、std、moment)处理复数 dtype 的支持。
详情请参阅 dask#10009 (作者:wkrasnicki)。
其他变更
将
actions/checkout从 4.0.0 升级到 4.1.0 (dask#10532)匹配
pandas回退apply弃用 (dask#10531) James Bourbeau将 gpuCI
RAPIDS_VER更新到23.12(dask#10526)暂时跳过在
fsspec==2023.9.1下失败的测试 (dask#10520) James Bourbeau
2023.9.2¶
发布于 2023 年 9 月 15 日
亮点¶
P2P Shuffle 在安装过时 PyArrow 时抛出错误¶
之前,如果安装了旧版本的 pyarrow,默认的 Shuffle 方法会静默地从 P2P 回退到基于任务的 Shuffle。现在,我们不再静默回退,而是抛出一个包含 P2P 所需最低 pyarrow 版本的提示性错误。
详情请参阅 dask#10496 (作者:Hendrik Makait)。
admin.traceback.shorten 的弃用周期¶
2023.9.0 版本修改了 admin.traceback.shorten 配置选项,但未引入弃用周期。这导致在某些情况下无法创建 Dask 集群。本次发布为这项配置更改引入了弃用周期。
详情请参阅 dask#10509 (作者:crusaderky)。
其他变更
避免在
delayed任务中具体化所有迭代器 (dask#10498) James Bourbeau彻底改进
dask.config中的弃用系统 (dask#10499) crusaderky移除
timeseries中不必要的检查 (dask#10447) Patrick Hoefler在测试中使用
register_plugin(dask#10503) James Bourbeau在
pyarrow_schema_dispatch中显式设置preserve_index(dask#10501) Hendrik Makait为
pyarrow_schema_dispatch添加**kwargs支持 (dask#10500) Hendrik Makait集中并键入
no_default(dask#10495) crusaderky
2023.9.1¶
发布于 2023 年 9 月 6 日
注意
这是一个热修复版本,修复了 2023.9.0 版本引入的 P2P Shuffle Bug(参见 dask#10493)。
改进¶
对 dask keys 使用更严格的数据类型 (dask#10485) crusaderky
对
DASK_环境变量中的None进行特殊处理 (dask#10487) crusaderky
Bug 修复¶
修复
DataFrame.set_index和DataFrame.sort_values中meta的_partitionsdtype问题 (dask#10493) Hendrik Makait处理
derived_from中的cached_property装饰器 (dask#10490) Lawrence Mitchell
维护¶
将
actions/checkout从 3.6.0 升级到 4.0.0 (dask#10492)简化一些导入
distributed的测试 (dask#10484) crusaderky
2023.9.0¶
发布于 2023 年 9 月 1 日
Bug 修复¶
移除对 keys 中
np.int64的支持 (dask#10483) crusaderky修复 Shuffle 中
meta的_partitionsdtype问题 (dask#10462) Hendrik Makait不使用异常钩子缩短回溯 (dask#10456) crusaderky
文档¶
在 DataFrame 文档中添加
p2pShuffle 选项 (dask#10477) Patrick Hoefler
维护¶
跳过
pandas=2.1.0时失败的测试 (dask#10488) Patrick Hoefler更新
pandas=2.1.0的测试 (dask#10439) Patrick Hoefler启用
pytest-timeout(dask#10482) crusaderky将
actions/checkout从 3.5.3 升级到 3.6.0 (dask#10470)
2023.8.1¶
发布于 2023 年 8 月 18 日
改进¶
添加对 cgroup v2 在
cpu_count中的支持 (dask#10419) Johan Olsson支持
sort=True和split_out>1的多列groupby(dask#10425) Richard (Rick) Zamora添加
DataFrame.enforce_runtime_divisions方法 (dask#10404) Richard (Rick) Zamora允许 Dask DataFrame
to_csv在single_file=True时使用文件mode="x"(dask#10443) Genevieve Buckley
Bug 修复¶
修复在附加模式且
single_file为True时运行to_csv导致的ValueError(dask#10441) Ben
维护¶
为
pandas添加默认的types_mapper到from_pyarrow_table_dispatch(dask#10446) Richard (Rick) Zamora
2023.8.0¶
发布于 2023 年 8 月 4 日
改进¶
修复
make_timeseries性能回归问题 (dask#10428) Irina Truong
文档¶
将
distributed.print添加到调试文档 (dask#10435) James Bourbeau记录 NumPy 函数与 Dask 函数的兼容性 (dask#9941) Chiara Marmo
维护¶
在
license元数据中使用 SPDX (dask#10437) John A Kirkham在
dask[dataframe]中要求dask[array](dask#10357) John A Kirkham将 gpuCI
RAPIDS_VER更新到23.10(dask#10427)简化兼容性代码 (dask#10426) Hendrik Makait
修复兼容性变量命名问题 (dask#10424) Hendrik Makait
修复 upstream
pandas和pyarrow的一些错误 (dask#10412) Irina Truong
2023.7.1¶
发布于 2023 年 7 月 20 日
注意
本次发布更新了 Dask DataFrame,如果安装了 pandas>=2 和 pyarrow>=12,将自动把使用 object 数据类型的文本数据转换为 string[pyarrow]。
这应该会显著减少许多处理文本数据的工作流程的内存消耗,并提高计算性能。
您可以通过设置配置值 dataframe.convert-string 为 False 来禁用此更改:
dask.config.set({"dataframe.convert-string": False})
改进¶
如果安装了适当的依赖项,转换为
pyarrow字符串 (dask#10400) James Bourbeau对于
p2p,避免在shuffle前进行repartition(dask#10421) Patrick Hoefler生成随机 Dask DataFrame 的 API (dask#10392) Irina Truong
加速
dask.bag.Bag.random_sample(dask#10356) crusaderky为无效的时间单位抛出有用的
ValueError(dask#10408) Nat Tabris当 divisions 匹配时(divisions 以列表形式提供),使
repartition成为无操作 (dask#10395) Nicolas Grandemange
Bug 修复¶
在
read_parquettoken 中使用dataframe.convert-string(dask#10411) James Bourbeau连接
MultiIndex时,Categorydtype会丢失 (dask#10407) Irina Truong修复
FutureWarning: The provided callable...警告 (dask#10405) Irina Truong在
read_parquet中启用非分类的 Hive 分区列 (dask#10353) Richard (Rick) Zamora忽略没有列的
DataFrame进行concat(dask#10359) Patrick Hoefler
2023.7.0¶
发布于 2023 年 7 月 7 日
改进¶
尝试加载 CLI 入口点时捕获异常 (dask#10380) Jacob Tomlinson
Bug 修复¶
修复
_clean_ipython_traceback中的拼写错误 (dask#10385) Alexander Clausen确保
df在from_pandas后是不可变的 (dask#10383) Patrick Hoefler对
Series.rename中的inplace始终发出警告 (dask#10313) Patrick Hoefler
文档¶
在 rechunk 文档中添加关于输出形状和重塑的说明 (dask#10377) Swayam Patil
维护¶
简化
astype实现 (dask#10393) Patrick Hoefler修复
test_first_and_last以适应已弃用的last(dask#10373) James Bourbeau将
level添加到create_merge_tree(dask#10391) Patrick Hoefler不从
scipy.stats.chisquare文档字符串中派生 (dask#10382) Doug Davis
2023.6.1¶
发布于 2023 年 6 月 26 日
改进¶
移除不再支持的
clip_lower和clip_upper(dask#10371) Patrick Hoefler支持
DataFrame.set_index(..., sort=False)(dask#10342) Miles清理远程回溯 (dask#10354) Irina Truong
为
pyarrow.Table转换添加分派机制 (dask#10312) Richard (Rick) Zamora即使启用了融合,也选择 P2P (dask#10344) Hendrik Makait
在图生成早期验证 rechunking 是否可能 (dask#10336) Hendrik Makait
Bug 修复¶
修复传递给
read_csv的header问题 (dask#10355) GALI PREM SAGAR在
GroupBy.var和GroupBy.std中尊重dropna和observed(dask#10350) Patrick Hoefler修复使用 distributed client 写入 hdf 时出现的
H5FD_lock错误 (dask#10309) Irina Truong修复
bag.map()的total_mem_usage问题 (dask#10341) Irina Truong
弃用¶
弃用带
method参数的DataFrame.fillna/Series.fillna(dask#10349) Irina Truong弃用
DataFrame.first和Series.first(dask#10352) Irina Truong
维护¶
弃用
numpy.compat(dask#10370) Irina Truong修复注解和跨度在线程间泄漏的问题 (dask#10367) Irina Truong
在
pyarrow_table_dispatch函数中使用通用 kwargs (dask#10364) Richard (Rick) Zamora移除
isna中不必要的try/except(dask#10363) Patrick Hoefler对 numpy 1.25 的
mypy支持 (dask#10362) crusaderky将
actions/checkout从 3.5.2 升级到 3.5.3 (dask#10348)在
upstream构建中恢复numba(dask#10330) James Bourbeau更新
pandas/numpy/scipy的每夜 wheel 索引 (dask#10346) Matthew Roeschke将 rechunk 配置值添加到 yaml (dask#10343) Hendrik Makait
2023.6.0¶
发布于 2023 年 6 月 9 日
改进¶
在
read_parquet中添加缺失的not in谓词支持 (dask#10320) Richard (Rick) Zamora
Bug 修复¶
修复不正确的
value_counts(dask#10323) Irina Truong更新空的
describetop 和 freq 值 (dask#10319) James Bourbeau
文档¶
修复 hetzner 拼写错误 (dask#10332) Sarah Charlotte Johnson
维护¶
在 Python 3.11 上使用
numba和sparse进行测试 (dask#10329) Thomas Grainger移除
numpy.find_common_type警告忽略 (dask#10311) James Bourbeau将 gpuCI
RAPIDS_VER更新到23.08(dask#10310)
2023.5.1¶
发布于 2023 年 5 月 26 日
注意
此版本取消对 Python 3.8 的支持。截至本版本,Dask 支持 Python 3.9、3.10 和 3.11。详情请参阅 此社区议题。
改进¶
取消对 Python 3.8 的支持 (dask#10295) Thomas Grainger
更改 Dask Bag 分区方案以提高集群饱和度 (dask#10294) Jacob Tomlinson
泛化 GPU 加速集合的
dd.to_datetime,引入get_meta_library工具 (dask#9881) Charles Blackmon-Luca将
na_action添加到DataFrame.map(dask#10305) Patrick Hoefler当未提供
columns时,在DataFrame.nsmallest和DataFrame.nlargest中抛出TypeError(dask#10301) Patrick Hoefler改进
pd.MultiIndex的sizeof(dask#10230) Patrick Hoefler支持在许多
DataFrame方法中使用重复列 (dask#10261) Patrick Hoefler为
DataFrame.idxmin和DataFrame.idxmax添加numeric_only支持 (dask#10253) Patrick Hoefler实现
DataFrame.quantile的numeric_only支持 (dask#10259) Patrick Hoefler在
DataFrame.std中添加对numeric_only=False的支持 (dask#10251) Patrick Hoefler实现
GroupBy.cumprod和GroupBy.cumsum的numeric_only=False(dask#10262) Patrick Hoefler实现
skew和kurtosis的numeric_only(dask#10258) Patrick Hoeflermask和where应该接受一个callable(dask#10289) Irina Truong修复
read_parquet中从Categorical到pa.dictionary的转换问题 (dask#10285) Patrick Hoefler
Bug 修复¶
嵌套注解中出现多余配置 (dask#10318) crusaderky
修复已知和未知块大小维度上的 rechunking 行为问题 (dask#10157) Hendrik Makait
启用
drop支持分区不匹配的情况 (dask#10300) James Bourbeau修复
to_timestamp的divisions构造问题 (dask#10304) Patrick Hoefler在
SeriesReduction 操作中抛出 pandasExtensionDtype异常 (dask#10149) Patrick Hoefler修复
da.random接口的回归问题 (dask#10247) Eray Aslanda.coarsen不会裁剪 meta 中的空块 (dask#10281) Irina Truong修复
read_csv中engine="pyarrow"的 dtype 推断问题 (dask#10280) Patrick Hoefler
文档¶
将
meta_from_array添加到 API 文档 (dask#10306) Ruth Comer更新 Coiled 链接 (dask#10296) Sarah Charlotte Johnson
添加演示日文档 (dask#10288) Matthew Rocklin
维护¶
上传 conda nightly 版本时,从 conda-forge 显式安装
anaconda-client(dask#10316) Charles Blackmon-Luca配置
isort添加from __future__ import annotations(dask#10314) Thomas Grainger避免在测试中出现 pandas
Series.__getitem__弃用警告 (dask#10308) James Bourbeau忽略 pandas
numpy.find_common_type警告 (dask#10307) James Bourbeau添加测试以检查
DataFrame.__setitem__不会就地修改df(dask#10223) Patrick Hoefler清理
value_counts中dropna的默认值 (dask#10299) Patrick Hoefler将
pytest-cov添加到testextra (dask#10271) James Bourbeau
2023.5.0¶
发布于 2023 年 5 月 12 日
改进¶
为
GroupBy.corr和GroupBy.cov实现numeric_only=False(dask#10264) Patrick Hoefler在
DataFrame.var中添加对numeric_only=False的支持 (dask#10250) Patrick Hoefler为
DataFrame.mode添加numeric_only支持 (dask#10257) Patrick Hoefler将
DataFrame.map添加到dask.DataFrameAPI (dask#10246) Patrick Hoefler调整以适应
DataFrame.applymap弃用和所有NAconcat行为变更 (dask#10245) Patrick Hoefler在
DataFrame.count中启用numeric_only=False(dask#10234) Patrick Hoeflermask和where应该接受callable(dask#10163) Irina Truong支持
GroupBy.corr和GroupBy.cov的numeric_only=True(dask#10227) Patrick Hoefler为
GroupBy.median添加numeric_only支持 (dask#10236) Patrick Hoefler支持
dask.datasets中的mimesis=9(dask#10241) James Bourbeau为
min、max和prod添加dask#10219) Patrick Hoefler为
GroupBy.cumsum和GroupBy.cumprod添加numeric_only=True支持 (dask#10224) Patrick Hoefler添加解包
numeric_only关键字的辅助函数 (dask#10228) Patrick Hoefler
Bug 修复¶
修复
clone+from_array失败问题 (dask#10211) crusaderky修复 ea dtypes 的 DataFrame Reduction 问题 (dask#10150) Patrick Hoefler
避免在
numpy=1.25中出现标量转换弃用警告 (dask#10248) James Bourbeau确保 transform 输出与输入具有相同的索引 (dask#10184) Irina Truong
修复在单行分区上执行
corr和cov的问题 (dask#9756) Irina Truong修复
test_groupby_numeric_only_supported和test_groupby_aggregate_categorical_observed上游错误 (dask#10243) Irina Truong
文档¶
清理 futures 文档 (dask#10266) Matthew Rocklin
添加
IndexAPI 参考 (dask#10263) hotpotato
维护¶
在将 meta 传递给
apply时发出警告 (dask#10256) Patrick Hoefler移除 CI 中
imageio的版本限制 (dask#10260) Patrick Hoefler移除未使用的
DataFrame方差方法 (dask#10252) Patrick Hoefler取消将
test_categories标记为预期失败(在使用pyarrow字符串和pyarrow>=12时) (dask#10244) Irina Truong将 gpuCI 的
PYTHON_VER从 3.8 升级到 3.9 (dask#10233) Charles Blackmon-Luca
2023.4.1¶
发布于 2023 年 4 月 28 日
改进¶
为
DataFrame.sum实现numeric_only支持 (dask#10194) Patrick Hoefler在
GroupBy操作中添加对numeric_only=True的支持 (dask#10222) Patrick Hoefler在针对
pandas1.4 及更高版本时,避免在DataFrame.__setitem__中进行深拷贝 (dask#10221) Patrick Hoefler避免使用
_meta_nonempty调用Series.apply(dask#10212) Patrick Hoefler取消锁定
sqlalchemy并修复兼容性问题 (dask#10140) Patrick Hoefler
Bug 修复¶
部分回退默认客户端发现 (dask#10225) Florian Jetter
在
Indexmeta 创建中支持 arrow dtypes (dask#10170) Patrick Hoefler在截断浮点数时,使用扩展 dtype 进行重新分区会抛出错误 (dask#10169) Patrick Hoefler
将来自
fastparquet的空Index调整为objectdtype (dask#10179) Patrick Hoefler
文档¶
更新 Kubernetes 文档 (dask#10232) Jacob Tomlinson
将
DataFrame.reduction添加到 API 文档 (dask#10229) James Bourbeau将
DataFrame.persist添加到文档并修复链接 (dask#10231) Patrick Hoefler添加关于
GroupBy.transform的文档 (dask#10185) Irina Truong修复随机数生成文档中的格式问题 (dask#10189) Eray Aslan
维护¶
将 imageio 锁定到
<2.28版本 (dask#10216) Patrick Hoefler添加关于
importlib_metadatabackport 的注释 (dask#10207) James Bourbeau将
xarray重新添加到 Python 3.11 CI 构建中 (dask#10200) James Bourbeau添加包含所有可选依赖项的
mindeps构建 (dask#10161) Charles Blackmon-Luca在
percentiles_summary中为array_safe提供合适的like值 (dask#10156) Charles Blackmon-Luca避免在
read_hdf中多次重新打开 hdf 文件 (dask#10205) Thomas Grainger添加关于可空列的合并测试 (dask#10071) Charles Blackmon-Luca
修复 coverage 配置 (dask#10203) Thomas Grainger
移除
is_period_dtype和is_sparse_dtype(dask#10197) Patrick Hoefler将
actions/checkout从 3.5.0 升级到 3.5.2 (dask#10201)避免使用 pandas 中已废弃的
is_categorical_dtype(dask#10180) Patrick Hoefler调整以适应已废弃的
is_interval_dtype和is_datetime64tz_dtype(dask#10188) Patrick Hoefler
2023.4.0¶
发布于 2023 年 4 月 14 日
改进¶
在
update_defaults中覆盖旧的默认值 (dask#10159) Gabe Joseph添加一个 CLI 命令,用于从 Dask 配置中
list和get值 (dask#9936) Irina Truong处理
read_json中的基于字符串的 engine 参数 (dask#9947) Richard (Rick) Zamora避免使用已废弃的
GroupBy.dtypes(dask#10111) Irina Truong
Bug 修复¶
恢复与
grouper相关的更改 (dask#10182) Irina TruongGroupBy.cov在非数字分组列时引发异常 (dask#10171) Patrick Hoefler更新了支持
numpy数字 dtype 的Index(dask#10154) Irina Truong使用
pyarrow读取时,保留分区列的dtype(dask#10115) Patrick Hoefler修复
to_hdf的注释 (dask#10123) Hendrik Makait检查列是否全部为数字时,处理
None列名 (dask#10128) Lawrence Mitchell修复
valid_divisions在传入tuple时的行为 (dask#10126) Brian Phillips在
DataFrame.categorize中保持注释 (dask#10120) Hendrik Makait修复过滤时处理缺失的 parquet 最小/最大统计信息的问题 (dask#10042) Richard (Rick) Zamora
废弃项¶
废弃
use_nullable_dtypes=并添加dtype_backend=(dask#10076) Irina Truong废弃
Series.apply中的convert_dtype(dask#10133) Irina Truong
文档¶
记录基于
Generator的随机数生成 (dask#10134) Eray Aslan
维护¶
将
dataframe.convert_string更新为dataframe.convert-string(dask#10191) Irina Truong将
python-cityhash添加到 CI 环境中 (dask#10190) Charles Blackmon-Luca临时锁定
scikit-image版本以修复 Windows CI (dask#10186) Patrick Hoefler处理
to_pydatetime和apply的 pandas 废弃警告 (dask#10168) Patrick Hoefler移除
bokeh<3限制 (dask#10177) James Bourbeau修复写时复制模式下的测试失败问题 (dask#10173) Patrick Hoefler
允许
pyarrowCI 失败 (dask#10176) James Bourbeau在
dask.array中切换到Generator进行随机数生成 (dask#10003) Eray Aslan将
peter-evans/create-pull-request从 4 升级到 5 (dask#10166)修复
test_arithmetic中不稳定的modf操作 (dask#10162) Irina Truong在使用
pandas2.0 的 CI 中临时移除xarray(dask#10153) James Bourbeau修复
test_default_scheduler_on_worker中的update_graph计数逻辑 (dask#10145) James Bourbeau修复使用
pandas2.0 构建文档的问题 (dask#10138) James Bourbeau从 gpuCI 更新评审人中移除
dask/gpu(dask#10135) Charles Blackmon-Luca将 gpuCI
RAPIDS_VER更新到23.06(dask#10129)将
actions/stale从 6 升级到 8 (dask#10121)使用声明式
setuptools(dask#10102) Thomas Grainger放宽对
Scalar类对象的assert_eq检查 (dask#10125) Matthew Rocklin将 readthedocs 配置升级到 ubuntu 22.04 和 Python 3.11 (dask#10124) Thomas Grainger
将
actions/checkout从 3.4.0 升级到 3.5.0 (dask#10122)修复 `pyarrow` CI 构建中的
test_null_partition_pyarrow问题 (dask#10116) Irina Truong移除分布式 pack (dask#9988) Florian Jetter
将
dask.compatibility设为私有 (dask#10114) Jacob Tomlinson
2023.3.2¶
发布于 2023 年 3 月 24 日
改进¶
对于使用分类变量的 `groupby`,废弃
observed=False(dask#10095) Irina Truong废弃一些 groupby 操作中的
axis=参数 (dask#10094) James BourbeauDataFrame.rolling/Series.rolling中的axis关键字已废弃 (dask#10110) Irina Truongpandas中的DataFrame._data已废弃 (dask#10081) Irina Truong使用
importlib_metadata向后移植以避免 CLIUserWarning(dask#10070) Thomas Grainger将选项解析逻辑从
dask.dataframe.read_parquet移植到to_parquet(dask#9981) Anton Loukianov
Bug 修复¶
避免在 groupby-apply 中使用
dd.shuffle(dask#10043) Richard (Rick) Zamora使用
pyarrowparquet 引擎时启用空 hive 分区 (dask#10007) Richard (Rick) Zamora支持
*_like函数中的未知形状 (dask#10064) Doug Davis
文档¶
将
to_backend方法添加到 API 文档中 (dask#10093) Lawrence Mitchell移除开发者文档中损坏的 gpuCI 链接 (dask#10065) Charles Blackmon-Luca
维护¶
将 readthedocs sphinx 警告配置为错误 (dask#10104) Thomas Grainger
在启用
pyarrow字符串时,取消对test_division_or_partition的 `xfail` 标记 (dask#10108) Irina Truong在启用
pyarrow字符串时,取消对test_different_columns_are_allowed的 `xfail` 标记 (dask#10109) Irina Truong恢复 Entrypoints 兼容性 (dask#10113) Jacob Tomlinson
在启用
pyarrow字符串时,取消对test_to_dataframe_optimize_graph的 `xfail` 标记 (dask#10087) Irina Truong仅在可编辑安装中运行
test_development_guidelines_matches_ci(dask#10106) Charles Blackmon-Luca在启用
pyarrow字符串时,取消对test_dataframe_cull_key_dependencies_materialized的 `xfail` 标记 (dask#10088) Irina Truong在 CI 环境中安装
mimesis(dask#10105) Charles Blackmon-Luca修复没有名为
ipykernel的模块的问题 (dask#10101) Irina Truong通过安装
ipykernel修复文档构建问题 (dask#10103) Thomas Grainger允许
pyarrow构建在失败时继续执行 (dask#10097) James Bourbeau将
actions/checkout从 3.3.0 升级到 3.4.0 (dask#10096)修复在启用
pyarrow字符串时test_set_index_on_empty的问题 (dask#10054) Irina Truong取消对
pyarrowpickling 测试的 `xfail` 标记 (dask#10082) James BourbeauCI 环境文件清理 (dask#10078) James Bourbeau
取消对更多
pyarrow测试的 `xfail` 标记 (dask#10066) Irina Truong使用 pandas 2.0 时,临时跳过
pyarrow_compat测试 (dask#10063) James Bourbeau修复在启用
pyarrow字符串时test_melt的问题 (dask#10052) Irina Truong修复在启用
pyarrow字符串时test_str_accessor的问题 (dask#10048) James Bourbeau修复在启用
pyarrow字符串时test_better_errors_object_reductions的问题 (dask#10051) James Bourbeau修复在启用
pyarrow字符串时test_loc_with_non_boolean_series的问题 (dask#10046) James Bourbeau修复在启用
pyarrow字符串时test_values的问题 (dask#10050) James Bourbeau临时将
test_upstream_packages_installed标记为 `xfail` (dask#10047) James Bourbeau
2023.3.1¶
发布于 2023 年 3 月 10 日
改进¶
支持
MultiIndex中的 pyarrow 字符串 (dask#10040) Irina Truong改进对
pyarrow字符串的支持 (dask#10000) Irina Truong修复数组规约期间不稳定的
RuntimeWarning问题 (dask#10030) James Bourbeau扩展
completeextras (dask#10023) James Bourbeau当
dataframe.convert-string=True且pandas<2.0时引发错误 (dask#10033) Irina Truong将 shuffle/rechunk 配置选项/关键字参数重命名为
method(dask#10013) James Bourbeau添加对将
pandas扩展 dtype 转换为数组的初步支持 (dask#10018) James Bourbeau移除
randomgen支持 (dask#9987) Eray Aslan
Bug 修复¶
当 rechunk 到相同块且大小未知时跳过 rechunk 操作 (dask#10027) Hendrik Makait
用于将 parquet 过滤器转换为
pyarrow表达式的自定义工具 (dask#9885) Richard (Rick) Zamora填充时将
numpy标量和 0d 数组视为标量 (dask#9653) Justus Magin修复自适应
read_parquet操作后的 parquet 覆盖行为 (dask#10002) Richard (Rick) Zamora
文档¶
添加和更新数据传输部分的文档 (dask#10022) Miles
维护¶
从
pyarrowparquet 引擎中移除过时的 hive 分区代码 (dask#10039) Richard (Rick) Zamora将
pyarrow的最低支持版本提高到 7.0 (dask#10024) James Bourbeau恢复“准备移除 packunpack (dask#9994)” (dask#10037) Florian Jetter
让 codecov 等待更多构建完成后再报告 (dask#10031) James Bourbeau
准备移除 packunpack (dask#9994) Florian Jetter
添加启用
pyarrow字符串的 CI 作业 (dask#10017) James Bourbeau修复针对
pandas2.0 的test_groupby_dropna_with_agg问题 (dask#10001) Irina Truong修复针对
pandas2.0 的test_pickle_roundtrip问题 (dask#10011) James Bourbeau
2023.3.0¶
发布于 2023 年 3 月 1 日
Bug 修复¶
Bag 不得将 p2p 选为默认 shuffle 方法 (dask#10005) Florian Jetter
文档¶
对默认使用 P2P 的次要跟进 (dask#10008) James Bourbeau
维护¶
为可选的
jinja2依赖项添加最低版本要求 (dask#9999) Charles Blackmon-Luca
2023.2.1¶
发布于 2023 年 2 月 24 日
注意
此版本将默认的 DataFrame shuffle 算法更改为 p2p,以提高稳定性和性能。在此了解更多信息,并请在此讨论中提供反馈。
如果您在使用此新算法时遇到问题,请参阅文档以获取更多信息以及如何切换回旧模式。
改进¶
默认启用 P2P shuffle (dask#9991) Florian Jetter
P2P rechunking (dask#9939) Hendrik Makait
为 read_parquet 提供高效的 dataframe.convert-string 支持 (dask#9979) Irina Truong
允许在 DataFrame 合并时使用 p2p shuffle kwarg (dask#9900) Florian Jetter
将
split_row_groups默认值更改为“infer” (dask#9637) Richard (Rick) Zamora添加用于将字符串数据转换为使用
pyarrow字符串的选项 (dask#9926) James Bourbeau添加对多列
sort_values的支持 (dask#8263) Charles Blackmon-Luca在``dask.array`` 中基于
Generator的随机数生成 (dask#9038) Eray Aslan支持针对
pandas2.0 兼容性的简单 groupby 聚合中的numeric_only(dask#9889) Irina Truong
Bug 修复¶
修复 profilers 绘图未与上下文管理器进入时间对齐的问题 (dask#9739) David Hoese
放宽 dask.dataframe assert_eq 类型检查 (dask#9989) Matthew Rocklin
恢复针对
pandas2.0 的describe兼容性 (dask#9982) James Bourbeau
文档¶
改进部署 Dask 的文档 (dask#9912) Sarah Charlotte Johnson
补充
DataFrame.partitions的文档 (dask#9976) Tom Augspurger更新文档,补充有关默认 Delayed 调度器的信息 (dask#9903) Guillaume Eynard-Bontemps
部署注意事项文档 (dask#9933) Gabe Joseph
维护¶
临时重新运行不稳定的测试 (dask#9983) James Bourbeau
更新 FULL_RAPIDS_VER/FULL_UCX_PY_VER 的解析逻辑 (dask#9990) Charles Blackmon-Luca
将最低支持版本提高到
pandas=1.3和numpy=1.21(dask#9950) James Bourbeau修复
std以支持pandas2.0 中的numeric_only(dask#9960) Irina Truong临时将
test_roundtrip_partitioned_pyarrow_dataset标记为 `xfail` (dask#9977) James Bourbeau修复 test_idxmaxmin 中的写时复制失败问题 (dask#9944) Patrick Hoefler
升级
pre-commit版本 (dask#9955) crusaderky修复针对
pandas2.0 的test_groupby_unaligned_index问题 (dask#9963) Irina Truong针对
pandas2.0,取消对test_set_index_overlap_2的 `xfail` 标记 (dask#9959) James Bourbeau修复
test_merge_by_index_patterns以兼容pandas2.0 (dask#9930) Irina Truong将 jacobtomlinson/gha-find-replace 从 2 升级到 3 (dask#9953) James Bourbeau
修复
test_rolling_agg_aggregate以兼容pandas2.0 (dask#9948) Irina Truong将
black升级到23.1.0(dask#9956) crusaderky在 python 3.8 和 3.10 上运行 GPU 测试 (dask#9940) Charles Blackmon-Luca
修复
test_to_timestamp以兼容pandas2.0 (dask#9932) Irina Truong修复
groupbyvalue_counts在pandas2.0 兼容性方面的问题 (dask#9928) Irina Truong配置转换器:将所有破折号替换为下划线 (dask#9945) Jacob Tomlinson
CI:在上游测试构建中使用 nightly wheel 安装 pyarrow (dask#9873) Joris Van den Bossche
2023.2.0¶
发布于 2023 年 2 月 10 日
改进¶
更新
numeric_only在quantile中的默认值以兼容pandas2.0 (dask#9854) Irina Truong当 divisions 匹配时,使
repartition成为无操作 (dask#9924) James Bourbeau更新
datetime_is_numeric在describe中的行为以兼容pandas2.0 (dask#9868) Irina Truong更新
value_counts在pandas2.0 中返回正确的名称 (dask#9919) Irina Truong支持
pandas2.0 中某些归约操作的新axis=None行为 (dask#9867) James Bourbeau在 chunk 级别过滤掉
nanmin和nanmax的全 nanRuntimeWarning(dask#9916) Julia Signell修复
pandas2.0 中数值型meta_nonemptyindexcreation的问题 (dask#9908) James Bourbeau修复
DataFrame.info()测试以兼容pandas2.0 (dask#9909) James Bourbeau
错误修复¶
修复
GroupBy.value_counts处理多个groupby列的问题 (dask#9905) Charles Blackmon-Luca
文档¶
修复开发指南中一些过时信息/拼写错误 (dask#9893) Patrick Hoefler
在
drop_duplicates文档字符串中添加关于keep=False的说明 (dask#9887) Jayesh Manani向 dask Array 添加
meta详细信息 (dask#9886) Jayesh Manani澄清任务流显示行数多于线程数的问题 (dask#9906) Gabe Joseph
维护¶
修复
test_numeric_column_names以兼容pandas2.0 (dask#9937) Irina Truong修复
dask/dataframe/tests/test_utils_dataframe.py测试以兼容pandas2.0 (dask#9788) James Bourbeau将
index.is_numeric替换为is_any_real_numeric_dtype以兼容pandas2.0 (dask#9918) Irina Truong避免在 dask 工具中导入
pd.core(dask#9907) Matthew Roeschke在 pull request 上使用标签进行
upstream构建 (dask#9910) James Bourbeau拓宽对
sqlalchemy.exc.RemovedIn20Warning的异常捕获范围 (dask#9904) James Bourbeau在 CI 中临时限制
sqlalchemy < 2(dask#9897) James Bourbeau将
isort版本更新到 5.12.0 (dask#9895) Lawrence Mitchell在
read_csv中移除未使用的skiprows变量 (dask#9892) Patrick Hoefler
2023.1.1¶
发布于 2023 年 1 月 27 日
改进¶
向
Array和_Frame添加to_backend方法 (dask#9758) Richard (Rick) Zamora修复
pandas2.0 中时间戳索引 divisions 的一个小问题 (dask#9872) Irina Truong向
DataFrame.cov和DataFrame.corr添加numeric_only参数 (dask#9787) James Bourbeau修复与
pandas2.0 中group_keys默认值更改相关的问题 (dask#9855) Irina Truonginfer_datetime_format兼容pandas2.0 (dask#9783) James Bourbeau
错误修复¶
修复
BroadcastJoinLayer中的序列化错误 (dask#9871) Richard (Rick) Zamora满足
DataFrame.merge中的broadcast参数 (dask#9852) Richard (Rick) Zamora
文档¶
修复文档警告“duplicate explicit target name” (dask#9863) Chiara Marmo
修复“Defining a new collection backend”文档中的代码格式问题 (dask#9864) Chiara Marmo
更新仪表盘关于内存图表的文档 (dask#9768) Jayesh Manani
添加关于
no-worker任务的文档章节 (dask#9839) Florian Jetter
维护¶
检测
distributed调度器的额外更新 (dask#9890) James Bourbeau将 gpuCI 的
RAPIDS_VER更新到23.04(dask#9876)颠倒 collection 和
distributed默认设置之间的优先级 (dask#9869) Florian Jetter将
xarray-contrib/issue-from-pytest-log更新到版本 1.2.6 (dask#9865) James Bourbeau不再需要 dask config 中的 shuffle 默认设置 (dask#9826) Florian Jetter
取消
xfail标记,修复新的fastparquet的datetime64Parquet 往返测试 (dask#9811) James Bourbeau添加手动运行
upstreamCI 构建的选项 (dask#9853) James Bourbeau在 CI 构建中使用自定义超时设置 (dask#9844) James Bourbeau
从
make_blockwise_graph中移除kwargs(dask#9838) Florian Jetter在
test_setitem_extended_API_2d_mask中的persist调用上忽略警告 (dask#9843) Charles Blackmon-Luca修复在本地运行 S3 测试的问题 (dask#9833) James Bourbeau
2023.1.0¶
发布于 2023 年 1 月 13 日
改进¶
即使没有设置配置,也使用
distributed默认客户端 (dask#9808) Florian Jetter实现
ma.where和ma.nonzero(dask#9760) Erik Holmgren更新
zarr存储创建函数 (dask#9790) Ryan Abernatheyiteritems兼容pandas2.0 (dask#9785) James Bourbeaupandasstring[python]数据类型的准确sizeof(dask#9781) crusaderky减小
pandas对象类型重复引用的sizeof()(dask#9776) crusaderkyGroupBy.__getitem__兼容pandas2.0 (dask#9779) James Bourbeauappend兼容pandas2.0 (dask#9750) James Bourbeauget_dummies兼容pandas2.0 (dask#9752) James Bourbeauis_monotonic兼容pandas2.0 (dask#9751) James Bourbeaunumpy=1.24兼容性 (dask#9777) James Bourbeau
文档¶
在
to_json的文档字符串中移除重复的encodingkwarg (dask#9796) Sultan Orazbayev在
LocalCluster文档中提及SubprocessCluster(dask#9784) Hendrik Makait将 Prometheus 文档移到
dask/distributed(dask#9761) crusaderky
维护¶
在
test_setitem_extended_API_2d_mask中临时忽略RuntimeWarning(dask#9828) James Bourbeau修复
test_threaded.py::test_interrupt中的不稳定性问题 (dask#9827) Hendrik Makait在
upstream报告中更新xarray-contrib/issue-from-pytest-log(dask#9822) James Bourbeau在 gpuCI 构建中通过
pip安装 dask (dask#9816) Charles Blackmon-Luca将
actions/checkout从 3.2.0 升级到 3.3.0 (dask#9815)解决
mindeps测试中sqlalchemy导入失败的问题 (dask#9809) Charles Blackmon-Luca忽略
sqlalchemy.exc.RemovedIn20Warning(dask#9801) Thomas Grainger对
pandas2.0 的datetime64Parquet 往返测试标记为xfail(dask#9786) James Bourbeau减小预期 DoK 稀疏矩阵的大小 (dask#9775) Elliott Sales de Andrade
从
dask/dataframe/io/orc/utils.py中移除可执行标志 (dask#9774) Elliott Sales de Andrade
2022.12.1¶
发布于 2022 年 12 月 16 日
改进¶
支持
dtype_backend="pandas|pyarrow"配置 (dask#9719) James Bourbeau在
dask.dataframe中支持cupy.ndarray到cudf.DataFrame的调度 (dask#9579) Richard (Rick) Zamora在
read_parquet中使文件系统后端可配置 (dask#9699) Richard (Rick) Zamora高效序列化所有
pyarrow扩展数组 (dask#9740) James Bourbeau
错误修复¶
修复使用
tz-aware datetime 索引进行 repartitioning 时的错误 (dask#9741) James Bourbeauaggs 中的部分函数可能包含参数 (dask#9724) Irina Truong
添加对
pyarrow-backed 扩展数据类型的简单操作支持 (dask#9717) James Bourbeau在
SeriesGroupby情况下正确重命名列 (dask#9716) Lawrence Mitchell
文档¶
更新 Prometheus 文档 (dask#9696) Hendrik Makait
维护¶
将
zarr添加到 Python 3.11 CI 环境 (dask#9771) James Bourbeau添加对 Python 3.11 的支持 (dask#9708) Thomas Grainger
将
actions/checkout从 3.1.0 升级到 3.2.0 (dask#9753)避免
np.bool8弃用警告 (dask#9737) James Bourbeau确保在
upstreamCI 构建中开发包不会被覆盖 (dask#9731) James Bourbeau在测试期间避免添加
data.h5和mydask.html文件 (dask#9726) Thomas Grainger
2022.12.0¶
发布于 2022 年 12 月 2 日
改进¶
从
read_parquet中移除基于统计的set_index逻辑 (dask#9661) Richard (Rick) Zamora向
dd.read_parquet添加对use_nullable_dtypes的支持 (dask#9617) Ian Rose修复
map_overlap以便接受 pandas 参数 (dask#9571) Fabien Aulaire修复 pandas 1.5+ 中
.str.split(..., expand=True)的FutureWarning(dask#9704) Jacob Hayes为
groupby切片启用列投影 (dask#9667) Richard (Rick) Zamora改进后端调度调用失败时的错误消息 (dask#9677) Richard (Rick) Zamora
错误修复¶
修改 arrow parquet 引擎中的 meta 创建 (dask#9672) Richard (Rick) Zamora
修复
da.fft.fft处理类数组输入的问题 (dask#9688) James Bourbeau修复按名称对索引进行分组时的
groupby聚合问题 (dask#9646) Richard (Rick) Zamora
维护¶
在
test_inheriting_class中避免PytestReturnNotNoneWarning(dask#9707) Thomas Grainger修复
test_dataframe_aggregations_multilevel中的不稳定性问题 (dask#9701) Richard (Rick) Zamora升级
mypy版本 (dask#9697) crusaderky在
test_map_partitions_df_input中禁用 dashboard (dask#9687) James Bourbeau在
upstream构建中使用最新的xarray-contrib/issue-from-pytest-log(dask#9682) James Bourbeau将
ttest_1samp对于上游scipy标记为xfail(dask#9670) James Bourbeau将 gpuCI 的
RAPIDS_VER更新到23.02(dask#9678)
2022.11.1¶
发布于 2022 年 11 月 18 日
改进¶
限制
bokeh=3的支持 (dask#9673) Gabe Josephfastparquet演进的更新 (dask#9650) Martin Durant
维护¶
更新 gpuCI 更新工作流中的
ga-yaml-parser步骤 (dask#9675) Charles Blackmon-Luca恢复
importlib.metadata临时解决方案 (dask#9658) James Bourbeau修复
mindeps-distributedCI 构建中处理numpy/`pandas` 未安装的问题 (dask#9668) James Bourbeau
2022.11.0¶
发布于 2022 年 11 月 15 日
改进¶
泛化
from_dict实现以允许从其他后端使用 (dask#9628) GALI PREM SAGAR
错误修复¶
在
dask.dataframe.core中避免使用pandas构造函数 (dask#9570) Richard (Rick) Zamora修复使用
Timestamp数据进行sort_values的问题 (dask#9642) James Bourbeau泛化数组检查并移除
_get_partitions中的pd.Index调用 (dask#9634) Benjamin Zaitlen修复
read_csv在header=0和names时的行为 (dask#9614) Richard (Rick) Zamora
文档¶
更新仪表盘关于队列的文档 (dask#9660) Gabe Joseph
从文档字符串中移除
import dask as d(dask#9644) Matthew Rocklin修复
read_parquet文档字符串中指向 partitions 文档的链接 (dask#9636) qheuristics向
array/bag/dataframe部分添加 API 文档链接 (dask#9630) Matthew Rocklin
维护¶
使用
conda-incubator/setup-miniconda@v2.2.0(dask#9662) John A Kirkham允许使用
bokeh=3(dask#9659) James Bourbeau使用 Python 3.10 运行
upstream构建 (dask#9655) James Bourbeau在 mindeps 测试中固定
pyyaml版本 (dask#9640) Charles Blackmon-Luca添加
pre-commit以捕获breakpoint()(dask#9638) James Bourbeau将
xarray-contrib/issue-from-pytest-log从 1.1 升级到 1.2 (dask#9635)移除
blosc引用 (dask#9625) Naty Clementi升级
mypy并移除未使用的注释 (dask#9616) Hendrik Makait加固
test_repartition_npartitions(dask#9585) Richard (Rick) Zamora
2022.10.1¶
发布于 2022 年 10 月 28 日
改进¶
向
set_index添加扩展数据类型支持 (dask#9566) James Bourbeau重新设计数组的 HTML repr 以提高清晰度 (dask#9519) Shingo OKAWA
文档¶
添加关于默认限制线程超额订阅的说明 (dask#9592) James Bourbeau
为
daskCLI 使用sphinx-click(dask#9589) James Bourbeau修复 Semaphore API 文档 (dask#9584) James Bourbeau
在
map_overlap文档字符串中渲染 meta 描述 (dask#9568) James Bourbeau
维护¶
Dask 中要求 Click 7.0+ (dask#9595) John A Kirkham
临时限制
bokeh<3(dask#9607) James Bourbeau解决
upstreamCI 中与importlib相关的失败 (dask#9604) Charles Blackmon-Luca改进
upstreamCI 报告 (dask#9603) James Bourbeau修复
upstreamCI 报告 (dask#9602) James Bourbeau移除
setuptoolshost dep,添加 CLI 入口点 (dask#9600) Charles Blackmon-Luca
2022.10.0¶
发布于 2022 年 10 月 14 日
新特性¶
Dask-Array 和 Dask-DataFrame 中 IO 的后端库调度 (dask#9475) Richard (Rick) Zamora
添加可扩展的新 CLI (dask#9283) Doug Davis
改进¶
修复数组复制不是无操作的问题 (dask#9555) David Hoese
在
map_overlap中添加对字符串 timedelta 的支持 (dask#9559) Nicolas Grandemange使
datetime.datetime幂等地标记化 (dask#9532) Martin Durant
错误修复¶
避免延迟调度注册中的竞态条件 (dask#9545) James Bourbeau
不允许对
int数据类型使用 setitem 设置np.nan(dask#9531) Doug Davis修复选择时 CSV 列投影问题 (dask#9534) Martin Durant
文档¶
更新 Parquet 最佳实践 (dask#9537) Matthew Rocklin
维护¶
限制
tiledb-py版本以避免 CI 失败 (dask#9569) James Bourbeau将
actions/github-script从 3 升级到 6 (dask#9564)将
actions/stale从 4 升级到 6 (dask#9551)将
peter-evans/create-pull-request从 3 升级到 4 (dask#9550)将
actions/checkout从 2 升级到 3.1.0 (dask#9552)将
codecov/codecov-action从 1 升级到 3 (dask#9549)将
the-coding-turtle/ga-yaml-parser从 0.1.1 升级到 0.1.2 (dask#9553)移动 dependabot 配置文件 (dask#9547) James Bourbeau
为 GitHub actions 添加 dependabot (dask#9542) James Bourbeau
在 Windows 和 Linux 上运行 mypy (dask#9530) crusaderky
将 gpuCI 的
RAPIDS_VER更新到22.12(dask#9524)
2022.9.2¶
发布于 2022 年 9 月 30 日
改进¶
从数组自动分块中移除因式分解逻辑 (dask#9507) James Bourbeau
文档¶
添加关于在独立 Python 脚本中运行 Dask 的文档 (dask#9513) James Bourbeau
2022.9.1¶
发布于 2022 年 9 月 16 日
新特性¶
添加
DataFrame和Series的median方法 (dask#9483) James Bourbeau
改进¶
按列表过滤 (dask#9419) Greg Hayes
将
distributed.utils.key_split功能添加到dask.utils.key_split(dask#9464) Luke Conibear
错误修复¶
修复 overlap,使得
set_index不会丢弃行 (dask#9423) Julia Signell修复当
ddf.columns.min()抛出异常时将 pandasSeries赋值给列的问题 (dask#9485) Erik Welch修复元数据比较
stack_partitions的问题 (dask#9481) James Bourbeau为
split_out提供默认值 (dask#9493) Lawrence Mitchell
文档¶
修正
enforce_metadata文档,不检查数据类型 (dask#9474) Nicolas Grandemange修复
it's–>its拼写错误 (dask#9484) Nat Tabris
维护¶
解决使用某些 datetime Series 写入 parquet 失败,但其他不失败的问题 (dask#9500) Ian Rose
过滤掉来自
pandas的numeric_only警告 (dask#9496) James Bourbeau在非必要情况下避免使用
set_index(..., inplace=True)(dask#9472) James Bourbeau避免传递长度为一的 groupby 键列表 (dask#9495) James Bourbeau
基于
cudf对group_keys的支持更新test_groupby_dropna_cudf(dask#9482) James Bourbeau移除
dd.from_bcolz(dask#9479) James Bourbeau将
flake8-bugbear添加到pre-commithook (dask#9457) Luke Conibear在函数定义中绑定循环变量 (
B023) (dask#9461) Luke Conibear添加比较断言 (
B015) (dask#9459) Luke Conibear在 CI 工作流中设置顶级默认 shell (dask#9469) James Bourbeau
移除未使用的循环控制变量 (
B007) (dask#9458) Luke Conibear将
getattr调用替换为常量属性 (B009) (dask#9460) Luke Conibear固定
libprotobuf以允许在上游 CI 构建中使用 nightlypyarrow(dask#9465) Joris Van den Bossche将可变数据结构替换为默认参数 (
B006) (dask#9462) Luke Conibear更改
flake8镜像并更新版本 (dask#9456) Luke Conibear
2022.9.0¶
发布于 2022 年 9 月 2 日
改进¶
为
groupby聚合启用自动列投影 (dask#9442) Richard (Rick) Zamora在 NEP-13/17 调度中接受超类 (dask#6710) Gabe Joseph
错误修复¶
在对相同
by列进行累积操作时,内部重命名by列 (dask#9430) Pavithra Eswaramoorthy修复使用 categoricals 进行
get_group的问题 (dask#9436) Pavithra Eswaramoorthy修复与缓存相关的
MaterializedLayer.cull性能回归 (dask#9413) Richard (Rick) Zamora
文档¶
添加维护者文档页面 (dask#9309) James Bourbeau
维护¶
恢复跳过的 fastparquet 测试 (dask#9439) Pavithra Eswaramoorthy
tmpfile在空扩展名时不会以点结束文件名 (dask#9429) Hendrik Makait跳过最新版本中失败的 fastparquet 测试 (dask#9432) James Bourbeau
2022.8.1¶
发布于 2022 年 8 月 19 日
新特性¶
实现
ma.*_like functions(dask#9378) Ruth Comer
改进¶
基于 shuffle 的高基数分组聚合 (dask#9302) Richard (Rick) Zamora
解包
namedtuple(dask#9361) Hendrik Makait
错误修复¶
修复
SeriesGroupBy在axis=1时的累积函数问题 (dask#9377) Pavithra Eswaramoorthy修复在使用带有索引的 categorical 列时
make_meta的问题 (dask#9348) Pavithra Eswaramoorthy不允许在
DataFrame.dropna中使用不兼容的关键词 (dask#9366) Naty Clementi使
set_index能够处理完全空的 dataframes (dask#8896) Julia Signell改进
unpack_collections中dataclass的处理 (dask#9345) Hendrik Makait
文档¶
澄清
bind()等会重新生成键 (dask#9385) crusaderky整合仪表盘诊断文档 (dask#9357) Sarah Charlotte Johnson
移除过时的
meta信息 Pavithra Eswaramoorthy
维护¶
在
sizeof中使用entry_points工具 (dask#9390) James Bourbeau添加
entry_points兼容性工具 (dask#9388) Jacob Tomlinson为每个 CI 构建上传环境文件 artifact (dask#9372) James Bourbeau
移除 CI 中的
werkzeugpin (dask#9371) James Bourbeau修复
dd.from_pandas和dd.from_delayed的类型注解 (dask#9362) Jordan Yap
2022.8.0¶
发布于 2022 年 8 月 5 日
改进¶
确保
make_meta不持有数据引用 (dask#9354) Jim Crist-Harif修改
from_pandas中的divisions逻辑 (dask#9221) Richard (Rick) Zamora如果用户使用现有索引设置索引,则发出警告 (dask#9341) Julia Signell
为
da.average添加keepdims关键词 (dask#9332) Ruth Comer更改
repr方法以避免Layer具体化 (dask#9289) Richard (Rick) Zamora
错误修复¶
确保
orderkwarg 不会使astype方法崩溃 (dask#9317) Genevieve Buckley修复在 cupy 分块 dask 数组上
cumsum的错误 (dask#9320) Genevieve Buckley在
_sample_reduce中匹配输入和输出结构 (dask#9272) Pavithra Eswaramoorthy在数组序列化中包含
meta(dask#9240) Frédéric BRIOL修复
Index.memory_usage(dask#9290) James Bourbeau修复
dask.dataframe.io.from_dask_array中的 division 计算问题 (dask#9282) Jordan Yap
文档¶
如何在自定义任务图中使用 kwargs (dask#9322) Genevieve Buckley
为
da.from_array添加关于顺序不保留的说明 (dask#9346) Julia Signell为异步函数添加 I/O 信息 (dask#9326) Logan Norman
整理 futures I/O 函数的文档代码片段 (dask#9340) Julia Signell
在
dataframe-groupby.rst中,对 pandasdf和 Daskddf使用一致的变量名 (dask#9304) ivojuroro在配置转换器中将
js-yaml替换为yaml.js(dask#9306) Jacob Tomlinson
维护¶
更新
da.linalg.solve以兼容 SciPy 1.9.0 (dask#9350) Pavithra Eswaramoorthy更新
test_getitem_avoids_large_chunks_missing(dask#9347) Pavithra Eswaramoorthy修复文档标题“扩展
sizeof”的格式 Doug Davis在测试中导入
loop_in_threadfixture (dask#9337) James Bourbeau暂时将
test_solve_sym_pos标记为预期失败 (dask#9336) Pavithra Eswaramoorthy修复 Dask 10 分钟教程页面中的小拼写错误 (dask#9329) Shaghayegh
在 CI 中暂时锁定
werkzeug版本以避免测试套件挂起 (dask#9325) James Bourbeau为
cupy.angle()添加测试 (dask#9312) Peter Andreas Entschev将 gpuCI
RAPIDS_VER更新到22.10(dask#9314)将
pandas[test]添加到testextra 中 (dask#9110) Ben Beasley将
bokeh和scipy添加到upstreamCI 构建中 (dask#9265) James Bourbeau
2022.7.1¶
发布于 2022 年 7 月 22 日
改进¶
如果所有轴都被 squeezed,则返回 Dask 数组 (dask#9250) Pavithra Eswaramoorthy
缩短 toposort 报告的循环 (dask#9068) Erik Welch
未知分块切片 - 抛出信息性错误 (dask#9285) Naty Clementi
Bug 修复¶
修复
HighLevelGraph.cull中的 bug (dask#9267) Richard (Rick) Zamora对类别进行排序 (dask#9264) Pavithra Eswaramoorthy
使用
max(而不是sum)计算warnsize(dask#9235) Pavithra Eswaramoorthy修复使用 pyarrow 对分区列进行过滤时的 bug (dask#9252) Richard (Rick) Zamora
文档¶
更新了 repartition 文档,添加关于
partition_size的说明 (dask#9288) Dylan Stewart不在
Array方法中包含文档,只引用模块文档 (dask#9244) Julia Signell删除对 scheduler 和 worker 控制面板的过时引用 (dask#9278) Pavithra Eswaramoorthy
维护¶
为
dd.from_pandas和dd.from_delayed添加类型注解 (dask#9237) Michael Milton更新
calculate_divisions的 docstring (dask#9275) Tom Augspurger更新
test_plot_multiple以适应即将发布的bokeh版本 (dask#9261) James Bourbeau
2022.7.0¶
发布于 2022 年 7 月 8 日
改进¶
在
normalize_token中支持pathlib.PurePath(dask#9229) Angus Hollands为属性添加
AttributeNotImplementedError,以便 IPython 的 glob 搜索能正常工作 (dask#9231) Erik Welchmap_overlap:处理多个 dataframe (dask#9145) Fabien Aulaire在
dask.sizeof中读取入口点 (dask#7688) Angus Hollands
Bug 修复¶
修复使用
Client(processes=False)写入 parquet 数据集时出现的TypeError: 'Serialize' object is not subscriptable错误 (dask#9015) Lucas Miguel Ponce使用空 dataframe 进行
concat时校正 dtypes (dask#9193) Pavithra Eswaramoorthy
文档¶
突出显示关于 persist 的说明 (dask#9234) Pavithra Eswaramoorthy
更新发布流程,包含更多细节和有用的命令 (dask#9215) Julia Signell
改进 Futures 和 Dask vs. Spark 页面的 SEO (dask#9217) Sarah Charlotte Johnson
维护¶
在列表、元组和迭代器上使用
math.prod而不是np.prod(dask#9232) crusaderky仅在进行类型检查时导入 IPython (dask#9230) Florian Jetter
更严格的 mypy 检查 (dask#9206) crusaderky
2022.6.1¶
发布于 2022 年 6 月 24 日
改进¶
创建
dask.utils.show_versions(dask#9144) Sultan Orazbayev为 dask.dataframe 对象上不支持的 numpy 操作提供更好的错误消息。 (dask#9201) Julia Signell
为
dask.array.overlap函数添加allow_rechunk关键字参数 (dask#7776) Genevieve Buckley为
dask.utils.format_time添加分钟和小时 (dask#9116) Matthew Rocklin
Bug 修复¶
Timedelta 确定性哈希 (dask#9213) Fabien Aulaire
Enum 确定性哈希 (dask#9212) Fabien Aulaire
shuffle_group():避免转换为数组 (dask#9157) Mads R. B. Kristensen
弃用¶
弃用额外的
format_time工具函数 (dask#9184) James Bourbeau
文档¶
改进 Dask 10 分钟教程页面的 SEO (dask#9182) Sarah Charlotte Johnson
改进 Delayed 和最佳实践页面的 SEO (dask#9194) Sarah Charlotte Johnson
在 DataFrame
str.splitaccessor 的 docstring 中包含已知不一致之处 (dask#9177) Richard Pelgrim为
derived_from添加inconsistencies关键字 (dask#9192) Richard Pelgrim修复最佳实践中的缩进 (dask#9196) Sarah Charlotte Johnson
添加链接到 Genevieve Buckley 关于分块大小的博客 (dask#9199) Pavithra Eswaramoorthy
更新
to_csv的 docstring (dask#9094) Sarah Charlotte Johnson
维护¶
更新 versioneer:从使用
SafeConfigParser更改为ConfigParser(dask#9205) Thomas A Caswell移除 CI 中的 ipython hack(dask#9200) crusaderky
2022.6.0¶
发布于 2022 年 6 月 10 日
改进¶
添加功能以在 HLG JupyterLab repr 中显示层依赖项的名称 (dask#9081) Angelos Omirolis
添加 arrow schema 提取 dispatch (dask#9169) GALI PREM SAGAR
为
assert_eq添加sort_results参数 (dask#9130) Pavithra Eswaramoorthy为
parse_timedelta添加周支持 (dask#9168) Matthew Rocklin警告 cloudpickle 并不总是确定性的 (dask#9148) Pavithra Eswaramoorthy
切换 parquet 默认引擎 (dask#9140) Jim Crist-Harif
使用
_iLocIndexer/_LocIndexer进行确定性哈希 (dask#9108) Fabien Aulaire在
to_parquetpyarrow 中强制执行一致的 schema (dask#9131) Jim Crist-Harif
Bug 修复¶
修复
pyarrow.StringArray的 pickle 问题 (dask#9170) Jim Crist-Harif修复 pyarrow 引擎中并行元数据收集的 bug (dask#9165) Richard (Rick) Zamora
改进
pyarrow分区逻辑 (dask#9147) James Bourbeaupyarrow8.0 分区修复 (dask#9143) James Bourbeau
文档¶
改进安装 Dask 和 Dask DataFrame 最佳实践页面的 SEO (dask#9178) Sarah Charlotte Johnson
更新文档中的徽标页面 (dask#9167) Sarah Charlotte Johnson
为
map_partition的 docstring 添加使用 pandas Series 的示例 (dask#9161) Alex-JG3更新文档主题以进行品牌重塑 (dask#9160) Sarah Charlotte Johnson
改进 Dask DataFrames 文档的 SEO (dask#9128) Sarah Charlotte Johnson
维护¶
从下游库的推荐实践中移除 ensure_file (dask#9171) Matthew Rocklin
测试包括 pyspark 在内的 DataFrame parquet I/O 往返 (dask#9156) Ian Rose
将最佳实践链接到 DataFrame-parquet (dask#9150) Tom Augspurger
修复
map_partitionsfunc参数描述中的拼写错误 (dask#9149) Christopher Akiki取消
xfailtest_groupby_grouper_dispatch的预期失败标记 (dask#9139) GALI PREM SAGAR暂时从 distributed 导入 cleanup fixture (dask#9138) James Bourbeau
简化 pyarrow parquet 引擎中的分区逻辑 (dask#9041) Richard (Rick) Zamora
2022.05.2¶
发布于 2022 年 5 月 26 日
改进¶
为非 pandas 的
Grouper对象添加 dispatch,并在GroupBy中使用它 (dask#9074) brandon-b-miller如果
read_parquet和to_parquet文件有交集,则抛出错误 (dask#9124) Jim Crist-Harif
文档¶
修复各种拼写错误 (dask#9126) Ryan Russell
维护¶
修复不稳定的
test_filter_nonpartition_columns(dask#9127) Pavithra Eswaramoorthy将 gpuCI
RAPIDS_VER更新到22.08(dask#9120)在 sdists 中包含
conftest.py`(dask#9115) Ben Beasley
2022.05.1¶
发布于 2022 年 5 月 24 日
新功能¶
添加
DataFrame.from_dict类方法 (dask#9017) Matthew Powers为 Dask DataFrame 添加
from_map函数 (dask#8911) Richard (Rick) Zamora
改进¶
改进
to_parquet关于追加分区重叠的错误提示 (dask#9102) Jim Crist-Harif启用用户定义的进程初始化函数 (dask#9087) ParticularMiner
在
map_partitions错误中提及align_dataframes=False选项 (dask#9075) Gabe Joseph为
dask.array.map_blocks()添加enforce_ndim关键字参数 (dask#8865) ParticularMiner实现
Series.GroupBy.fillna/DataFrame.GroupBy.fillna方法 (dask#8869) Pavithra Eswaramoorthy允许将
fillna用于 Dask DataFrame (dask#8950) Pavithra Eswaramoorthy更新一维 dask 数组赋值的错误消息 (dask#9036) Pavithra Eswaramoorthy
集合协议 (dask#8674) Doug Davis
修复
pandasArrowStringArraypickling 相关问题 (dask#9024) Jim Crist-Harif添加
p2pshuffle 选项 (dask#8836) Matthew Rocklin
Bug 修复¶
修复列投影没有指定列时的 bug (dask#9106) Jim Crist-Harif
修复
from_map中的列投影 bug (dask#9078) Richard (Rick) Zamora防止非数字 dtypes 索引中出现空值 (dask#8963) Jorge López
修复超过 8 个分区的
is_monotonic方法 (dask#9019) Julia Signell处理传递给
from_map的 enumerate 和 generator 输入 (dask#9066) Richard (Rick) Zamora恢复
is_dask_collection;回到之前的实现 (dask#9062) Doug Davis数组
setitem硬掩码 (dask#9027) David Hassell
弃用¶
为
read_parquet的关键字参数chunksize和aggregate_files添加预弃用警告 (dask#9052) Richard (Rick) Zamora
文档¶
文档说明
map_partitions如何处理args和kwargs,以及如何使用partition_info(dask#9084) Charles Blackmon-Luca更新自定义集合文档(利用新的集合协议)(dask#9097) Doug Davis
改进创建和存储 Dask DataFrames 文档的 SEO (dask#9098) Sarah Charlotte Johnson
澄清
imreaddocstring 中的分块说明 (dask#9082) Genevieve Buckley重新组织文档目录 (dask#9001) Matthew Rocklin
更正了
map_blocks()的 docstring 中关于关键字参数enforce_ndim的说明 (dask#9071) ParticularMiner更新 DataFrame SQL 文档中对其他库的引用 (dask#9077) Charles Blackmon-Luca
更新关于创建和存储 Dask DataFrames 的页面 (dask#9025) Sarah Charlotte Johnson
维护¶
在许可证文件中包含
NUMPY_LICENSE.txt(dask#9113) Ben Beasley安装夜间构建的
pandas时增加重试次数 (dask#9103) James Bourbeau在上游构建中强制使用夜间构建的
pyarrow(dask#9095) Joris Van den Bossche改进
ensure_unicode的对象处理和测试 (dask#9059) John A Kirkham在上游构建中强制使用夜间构建的
pyarrow(dask#8993) Joris Van den Bossche对
is_dask_collection进行额外检查 (dask#9054) Doug Davis更新
ensure_bytes(dask#9050) John A Kirkham添加文件末尾 pre-commit hook (dask#9045) James Bourbeau
添加
codespellpre-commit hook (dask#9040) James Bourbeau移除 HDFS 测试 (dask#9039) Jim Crist-Harif
修复不稳定的
test_reductions_2D(dask#9037) Jim Crist-Harif防止 codecov 过早报告失败 (dask#9031) Jim Crist-Harif
仅在 macos 上测试 Python 3.9 (dask#9029) Jim Crist-Harif
更新
to_timedelta的默认单位 (dask#9010) Pavithra Eswaramoorthy
2022.05.0¶
发布于 2022 年 5 月 2 日
亮点¶
这是针对 this issue 的一个 bug 修复版本。
文档¶
在 2022.04.2 版本说明中添加亮点部分 (dask#9012) James Bourbeau
2022.04.2¶
发布于 2022 年 4 月 29 日
亮点¶
此版本包含对 dask.dataframe.read_parquet 和 dask.dataframe.to_parquet 的一些弃用/破坏性 API 更改
to_parquet默认不再写入_metadata文件。如果您想写入_metadata文件,可以传入write_metadata_file=True。read_parquet现在默认为split_row_groups=False,这在读取 parquet 数据集时会导致每个 parquet 文件对应一个 Dask dataframe 分区。如果您处理的是大型 parquet 文件,可能需要将split_row_groups=True设置为 True 来减小分区大小。read_parquet默认不再计算 divisions。如果您需要read_parquet返回具有已知 divisions 的 dataframe,请设置calculate_divisions=True。read_parquet已弃用gather_statistics关键字参数。请改用calculate_divisions关键字参数。read_parquet已弃用require_extensions关键字参数。请改用parquet_file_extension关键字参数。
新功能¶
添加
removeprefix和removesuffix作为StringMethods(dask#8912) Jorge López
改进¶
在
to_parquet中调用fs.invalidate_cache(dask#8994) Jim Crist-Harif将
to_parquet的默认值更改为write_metadata_file=None(dask#8988) Jim Crist-Harif允许 arg reductions 传递
keepdims(dask#8926) Julia Signell在
read_parquet中将split_row_groups的默认值更改为False(dask#8981) Richard (Rick) Zamora改进
da.reshape的NotImplementedError错误消息 (dask#8987) Jim Crist-Harif简化
to_parquet的计算路径 (dask#8982) Jim Crist-Harif如果尝试将
vindex用于 Dask 对象,则抛出错误 (dask#8945) Julia Signell指定 precache 方法时避免使用
pre_buffer=True(dask#8957) Richard (Rick) Zamorafrom_dask_array使用blockwise而不是合并图 (dask#8889) Bryan Weber为 “pyarrow” Parquet 引擎使用
pre_buffer=True(dask#8952) Richard (Rick) Zamora
Bug 修复¶
修复由
blockwisefusion 引起的dask-sqlbug (dask#8989) Richard (Rick) Zamorato_parquet对非字符串列名抛出错误 (dask#8990) Jim Crist-Harif确保
da.roll即使形状为 0 也正常工作 (dask#8925) Julia Signell修复
set_index的递归错误问题 (dask#8967) Paul Hobson当
produces_keys=True时,将BlockwiseDepDict映射值转换为字符串 (dask#8972) Richard (Rick) Zamora在
DataFrame.from_delayed中使用 DataFram`eIOLayer (dask#8852) Richard (Rick) Zamora检查
read_parquet中inpredicate 的值是否正确 (dask#8846) Bryan Weber在
read_sql_query中使用np.linspace决定分区时指定dtype(dask#8940) Cheun Hong
弃用¶
弃用
read_parquet中的gather_statistics(dask#8992) Richard (Rick) Zamora将
require_extension更改为顶层parquet_file_extensionread_parquet关键字参数 (dask#8935) Richard (Rick) Zamora
文档¶
更新文档中关于
write_metadata_file的讨论 (dask#8995) Richard (Rick) Zamora更新
DataFrame.merge的 docstring (dask#8966) Pavithra Eswaramoorthy添加了
array.blockwise()中参数align_arrays的描述 (dask#8977) ParticularMiner建议不要在数组的分块轴上使用
map_block(drop_axis=...)(dask#8921) ParticularMiner在文档中的代码片段添加复制按钮 (dask#8956) James Bourbeau
维护¶
在 CI 的 distributed 环境中添加
pytest-timeout(dask#8986) Julia Signell改进
read_parquet的 docstring 格式 (dask#8971) Bryan Weber移除
pytest.warns(None)(dask#8924) Pavithra Eswaramoorthy将 Python 3.10 标记为支持版本 (dask#8976) Eray Aslan
parse_timedelta选项,用于强制指定单位 (dask#8969) crusaderky兼容
mypy(dask#8854) Paul Hobson添加一个关于 Dask 和 Parquet 的文档页面 (dask#8899) Jim Crist-Harif
添加配置以忽略 blame 中的修订 (dask#8933) Bryan Weber
2022.04.1¶
发布于 2022 年 4 月 15 日
改进¶
当
write_metadata_file=False时,避免在 pyarrow 中收集 parquet 元数据 (dask#8906) Richard (Rick) Zamora改进
dd.read_csv()中通配符路径失败的错误提示(修复 #8878)(dask#8908) Roger Filmyer对于
dd.Series上的非 ufunc 元素级函数,返回da.Array而不是dd.Series(dask#8558) Julia Signell允许
get_dummies在map_partitions中使用meta计算 (dask#8898) Julia Signell传递给
da.from_array的掩码标量输入 (dask#8895) David Hassell在
merge_asof中对重复的kwargs抛出ValueError错误 (dask#8861) Bryan Weber
Bug 修复¶
确保
is_monotonic在某些分区为空时也正常工作 (dask#8897) Julia Signell修复当
inline_array=False时da.from_array中的自定义 getter (dask#8903) Ian Rose修复
merge_asof:如果left_on == right_on则丢弃索引列 (dask#8874) Gil Forsyth
弃用¶
警告用户
engine='auto'在未来将发生变化 (dask#8907) Jim Crist-Harif从 parquet API 中移除
pyarrow-legacy引擎 (dask#8835) Richard (Rick) Zamora
文档¶
添加关于
dask.array.dot中缺失参数out的说明 (dask#8913) Francesco Andreuzzi更新
DataFrame.query的 docstring (dask#8890) Pavithra Eswaramoorthy
维护¶
不要在大整数数据上测试
da.prod(dask#8893) Jim Crist-Harif为断网时会失败的测试添加
network标记 (dask#8881) Paul Hobson修复 gpuCI GHA 版本 (dask#8891) Charles Blackmon-Luca
xfail/skip一些不稳定的distributed测试 (dask#8887) Jim Crist-Harif移除
ArrowDatasetEngine中未使用(已弃用)的代码 (dask#8885) Richard (Rick) Zamora为常用工具函数添加轻微类型提示,第二部分 (dask#8867) crusaderky
关于
sample()限制的文档 (dask#8858) Nadiem Sissouno
2022.04.0¶
发布于 2022 年 4 月 1 日
注意
这是首次支持 Python 3.10 的版本
新特性¶
添加 Python 3.10 支持 (dask#8566) James Bourbeau
改进¶
添加对
dtype.itemsize的检查以生成有用的错误信息 (dask#8860) Davide Gavio为通用工具函数添加轻度类型提示 (dask#8848) Matthew Rocklin
为
divisionssetter添加健全性检查 (dask#8806) Jim Crist-Harif在更多任务中使用
Blockwise和map_partitions(dask#8831) Bryan Weber
错误修复¶
修复
dataframe.merge_asof以保留right_on列 (dask#8857) Sarah Charlotte Johnson修复 32 位系统上 pandas >= 1.3 的“Buffer dtype mismatch”错误 (dask#8851) Ben Greiner
弃用¶
移除对 PyPy 的支持 (dask#8863) James Bourbeau
在运行时移除对
setuptools的依赖 (dask#8855) crusaderky移除
dataframe.tseries.resample.getnanos(dask#8834) Sarah Charlotte Johnson
文档¶
组织诊断和性能文档 (dask#8871) Naty Clementi
添加图片以解释
map_blocks的drop_axis选项 (dask#8868) ParticularMiner
维护¶
将 gpuCI
RAPIDS_VER更新至22.06(dask#8828)在 http 中恢复
test_parquet(dask#8850) Bryan Weber简化 gpuCI 更新工作流程 (dask#8849) Charles Blackmon-Luca
2022.03.0¶
发布于 2022 年 3 月 18 日
新特性¶
Bag:添加水塘抽样(reservoir sampling)实现 (dask#7636) Daniel Mesejo-León
将
ma.count添加到 Dask 数组 (dask#8785) David Hassell将
to_parquet的默认压缩方式更改为compression="snappy"(dask#8814) Jim Crist-Harif为
dask.array.reduction添加weights参数 (dask#8805) David Hassell添加
ddf.compute_current_divisions以获取排序索引或列的分区信息(divisions) (dask#8517) Julia Signell
改进¶
对未实现的 merge
how选项抛出异常 (dask#8818) Naty Clementi将
Bag.map_partitions移至Blockwise(dask#8646) Richard (Rick) Zamora改进配置格式错误时的错误消息 (dask#8801) Jim Crist-Harif
修订列投影优化以捕获常见的 dask-sql 模式 (dask#8692) Richard (Rick) Zamora
为空分区(divisions)提供有用的错误提示 (dask#8789) Pavithra Eswaramoorthy
Scipy 1.8.0 兼容性:将私有类复制到 dask/array/stats.py (dask#8694) Julia Signell
在使用多种类型调度器(其中之一是
distributed)时发出警告 (dask#8700) Pedro Silva
错误修复¶
修复在
read_parquet中应用 != 过滤器的 bug (dask#8824) Richard (Rick) Zamora修复直接传入 dask Index 时
set_index的问题 (dask#8680) Paul Hobson快速修复 tensordot 中无限内存使用的问题 (dask#7980) Genevieve Buckley
如果 hdf 文件为空,创建元数据(meta)时不再失败 (dask#8809) Julia Signell
更新
clone_key("x")以保留前缀 (dask#8792) crusaderky修复基于 pyarrow 的
read_parquet中的“物理”列 bug (dask#8775) Richard (Rick) Zamora修复序列化 bug (dask#8786) Richard (Rick) Zamora
弃用¶
将 diagnostics bokeh 依赖项版本提升至 2.4.2 (dask#8791) Charles Blackmon-Luca
弃用对
bcolz的支持 (dask#8754) Pavithra Eswaramoorthy完成将
map_overlap的默认 boundarykwarg设置为'none'的工作 (dask#8743) Genevieve Buckley
文档¶
修复自定义集合示例文档 (dask#8807) Doug Davis
将
Series.str,Series.dt, 和Series.cat访问器添加到文档中 (dask#8757) Sarah Charlotte Johnson修复
ddf.compute_current_divisions的 docstring (dask#8793) Julia Signell关于 /status 页面的 Dashboard 文档 (dask#8648) Naty Clementi
在 repartition docstring 中澄清 divisions
kwarg(dask#8781) Sarah Charlotte Johnson更新 Docker 镜像以使用 ghcr.io (dask#8774) Jacob Tomlinson
维护¶
减少 gpuci
pytest并行度 (dask#8826) GALI PREM SAGARabsolufy-imports- 无相对导入 - PEP8 (dask#8796) Julia Signell整理数组测试中的
assert_eq调用 (dask#8812) Julia Signell修复
test_describe_empty使其在没有全局-Werror的情况下也能工作 (dask#8291) Michał Górny暂时在 windows 上 xfail graphviz 测试 (dask#8794) Jim Crist-Harif
使用
packaging.parse实现md5兼容性 (dask#8763) James Bourbeau使
tokenize在 FIPS 140-2 环境中工作 (dask#8762) Jim Crist-Harif在 issue 和 PR 打开时添加“needs triage”标签 (dask#8761) Julia Signell
指定 action 版本并将
pull_request_target更改为pull_request(dask#8767) Julia Signell在
da.assert_eq中使 schedulerkwarg传递给子函数 (dask#8755) Julia Signell
2022.02.1¶
发布于 2022 年 2 月 25 日
新特性¶
为
dask.dataframe.pivot_table添加聚合函数first和last(dask#8649) Knut Nordanger为类 pandas 对象的
datetime64dtype添加std()支持 (dask#8523) Ben Glossner为
HighLevelGraph和Layer的 html reprs 添加具体化任务计数 (dask#8589) kori73
改进¶
不允许迭代
DataFrameGroupBy(dask#8696) Bryan Weber修复在空
DataFrame上调用info()后缺失换行符的问题 (dask#8727) Naty Clementi改进多 DataFrame join 的性能 (dask#8740) Holden Karau
为
Index包含bool类型 (dask#8732) Naty Clementi允许
ArrowDatasetEngine子类覆盖 pandas->arrow 转换,也适用于分区写入 (dask#8741) Joris Van den Bossche提高
da.diag()和da.diagonal()中 k 对角线提取的性能 (dask#8689) ParticularMiner对
dataclasses进行 Tokenize (dask#8557) Gabe Joseph更新
tokenize以区分处理dict和kwargs(dask#8655) James Bourbeau
错误修复¶
修复
dask.array.roll()中,当 roll-shifts 值与输入数组大小时一致时的 bug (dask#8723) ParticularMiner修复
normalize_functiondataclass方法的问题 (dask#8527) Sarah Charlotte Johnson修复使用零大小块进行 rechunking 的问题 (dask#8703) ParticularMiner
移动
sqlalchemy连接的创建位置以支持 pickle 序列化 (dask#8745) Julia Signell
弃用¶
停止支持 Python 3.7 (dask#8572) James Bourbeau
弃用
iteritems(dask#8660) James Bourbeau弃用
dataframe.tseries.resample.getnanos(dask#8752) Sarah Charlotte Johnson为 pyarrow-legacy 引擎添加弃用警告 (dask#8758) Richard (Rick) Zamora
文档¶
更新变更日志中的链接拼写错误 (dask#8717) James Bourbeau
更新 Docker 示例以使用当前最佳实践 (dask#8731) Jacob Tomlinson
更新文档以包含
distributed.Client.preload(dask#8679) Bryan Weber记录每月社交会议 (dask#8595) Thomas Grainger
添加关于使用 RBAC/ACL (即安全主体) 进行 Gen2 访问的文档 (dask#8748) Martin Thøgersen
使用
dask-sphinx-theme中的 Dask 配置扩展 (dask#8751) Benjamin Zaitlen
维护¶
在 CI 中解除
coverage的版本锁定 (dask#8690) James Bourbeau添加手动触发测试套件运行的机制 (dask#8716) James Bourbeau
Xfail
scheduler_HLG_unpack_import;不稳定测试 (dask#8724) Mike McCarty暂时移除
scipy上游 CI 构建 (dask#8725) James Bourbeau提升预发布版本号使其大于稳定版本号 (dask#8728) Charles Blackmon-Luca
将自定义排序函数逻辑移至内部
sort_values(dask#8571) Charles Blackmon-Luca在文档要求中固定
cloudpickle和scipy的版本 (dask#8737) Julia Signell使标签机器人不删除标签,并在正确位置查找文档 (dask#8746) Julia Signell
修复文档构建警告 (dask#8432) Kristopher Overholt
更新测试状态徽章 (dask#8747) James Bourbeau
修复 parquet
test_pandas_timestamp_overflow_pyarrow测试 (dask#8733) Joris Van den Bossche仅在相关文件更改时运行 PR 构建 (dask#8756) Charles Blackmon-Luca
2022.02.0¶
发布于 2022 年 2 月 11 日
注意
这是最后一个支持 Python 3.7 的版本
新特性¶
在使用现有数组时,为
to_zarr添加region参数 (dask#8590) Chris Roat为
dask.dataframe.to_sql添加engine_kwargs支持 (dask#8609) Amir Kadivar为
read_json添加include_path_column参数 (dask#8603) Bryan Weber
改进¶
为
assert_eq工具函数添加调度器选项 (dask#8610) Xinrong Meng修复
axis=None时 concatenate 与 NumPy 的不一致问题 (dask#8686) Tom White类型注解,第一部分 (dask#8295) crusaderky
确实允许将任何可迭代对象作为
meta传入 (dask#8629) Julia Signell在
to_parquet中使用map_partitions(Blockwise) (dask#8487) Richard (Rick) Zamora
错误修复¶
数组归约的结果不应依赖于其块结构 (dask#8637) ParticularMiner
在 ACA 代码路径中将占位符元数据传递给
map_partitions(dask#8643) Richard (Rick) Zamora
弃用¶
弃用
is_monotonic(dask#8653) James Bourbeau移除一些弃用项 (dask#8605) James Bourbeau
文档¶
修复内部链接并移除弃用函数 (dask#8715) Julia Signell
修复不平衡的反引号。 (dask#8693) Matthias Bussonnier
添加高层图可视化文档 (dask#8483) Genevieve Buckley
更新
ProgressBar的out参数文档 (dask#8604) Pedro Silva改进
dask.config.set的文档 (dask#8705) crusaderky撤回在类型检查器中提及
mypy的部分 (dask#8699) crusaderky
维护¶
更新
get_dummies测试中的警告处理 (dask#8651) James Bourbeau添加 GitHub 变更日志模板 (dask#8714) Julia Signell
更新 LICENSE.txt 中的年份 (https://github.com/dask/dask/pull/8665) David Hoese
更新
pre-commit版本 (dask#8691) James Bourbeau在上游 CI 构建中包含
scipy(dask#8681) James Bourbeau暂时在 CI 中固定
scipy < 1.8.0(dask#8683) James Bourbeau在 GPU CI 中固定
scipy版本低于 1.8.0 (dask#8698) Julia Signell在
test_multi.py中避免使用pytest.warns(None)(dask#8678) James Bourbeau更新 GHA 并发作业取消机制 (dask#8652) James Bourbeau
使
test__get_paths在设置了site.PREFIXES时也能健壮工作 (dask#8644) James Bourbeau将 gpuCI PYTHON_VER 提升至 3.9 (dask#8642) Charles Blackmon-Luca
2022.01.1¶
发布于 2022 年 1 月 28 日
新特性¶
添加
dask.dataframe.series.view()(dask#8533) Pavithra Eswaramoorthy
改进¶
更新
fastparquet+pandas1.4.0 的tz(dask#8626) Martin Durant清理杂项测试以兼容
pandas(dask#8623) Julia SignellPandas 兼容性:过滤稀疏警告 (dask#8621) Julia Signell
如果
meta不是pandas对象则失败 (dask#8563) Julia Signell使用
fsspec.parquet模块以提高远程存储read_parquet的性能 (dask#8339) Richard (Rick) Zamora将 DataFrame ACA 聚合移至 HLG (dask#8468) Richard (Rick) Zamora
在
DataFrameIOLayer中添加关于原始函数调用的可选信息 (dask#8453) Richard (Rick) Zamora重构配置默认搜索路径检索逻辑 (dask#8573) James Bourbeau
为
Bag.to_dataframe函数添加optimize_graph标志 (dask#8486) Maxim Lippeveld确保延迟输出操作仍然返回路径列表 (dask#8498) Julia Signell
Pandas 兼容性:修复
to_frame的name参数不传递None的问题 (dask#8554) Julia SignellPandas 兼容性:修复
axis=None警告 (dask#8555) Julia Signell
错误修复¶
修复按索引分组的序列(series)使用
groupby.cumsum的问题 (dask#8588) Julia Signell修复
pandas方法的derived_from问题 (dask#8612) Thomas J. Fan强制
sort_values的ascending为布尔值 (dask#8440) Charles Blackmon-Luca修复
__setitem__索引的解析问题 (dask#8601) David Hassell避免切片中的零除错误 (dask#8597) Doug Davis
弃用¶
将 (dask#8563) 中的
meta错误降级为警告 (dask#8628) Julia SignellPandas 兼容性:当
pandas >= 1.4.0时弃用append(dask#8617) Julia Signell
文档¶
在 DataFrame 构造函数中,用
meta替换过时的columns参数 (dask#8614) kori73重构部署文档 (dask#8602) Jacob Tomlinson
维护¶
在 CI 中固定
coverage版本 (dask#8631) James Bourbeau将
cached_cumsum导入移至来自dask.utils(dask#8606) James Bourbeau将 gpuCI
RAPIDS_VER更新至22.04(dask#8600)更新
from_delayed函数的 docstring (dask#8576) Kirito1397处理
plot_width/plot_height弃用问题 (dask#8544) Bryan Van de Ven移除不必要的
pyyamlimportorskip(dask#8562) James Bourbeau在 DataFrame
assert_eq中指定调度器 (dask#8559) Gabe Joseph
2022.01.0¶
发布于 2022 年 1 月 14 日
新特性¶
添加
DataFrame.nunique(dask#8479) Sarah Charlotte Johnson添加
da.ndim以匹配np.ndim(dask#8502) Julia Signell
改进¶
仅当 NumPy 版本 >= 1.22 时显示
percentileinterpolation=关键字警告 (dask#8564) Julia Signell当
limit和"array.slicing.split-large-chunks"为None时抛出PerformanceWarning(dask#8511) Julia Signell确保 divisions 始终是元组 (tuple) (dask#8393) Charles Blackmon-Luca
允许为
bag.groupby使用可调用调度器 (dask#8492) Julia Signell在
read_bytes中使字节块更均匀 (dask#8459) Martin Durant通过完全移除连接操作,提高了
matmul()的效率 (dask#8423) ParticularMiner重塑 dask 数组时限制最大块大小 (dask#8124) Genevieve Buckley
针对 fastparquet superthrift 的更改 (dask#8470) Martin Durant
错误修复¶
修复数组赋值中的布尔索引问题 (dask#8538) David Hassell
检测类数组对象的默认
dtype(dask#8501) aeisenbarth修复
optimize_blockwise中依赖项名称重复导致的 bug (dask#8542) Richard (Rick) Zamora更新
DataFrame.GroupBy.apply和 transform 的警告 (dask#8507) Sarah Charlotte Johnson在
Delayed中跟踪 HLG 层名称 (dask#8452) Gabe Joseph修复单项
nanmin和nanmax归约的问题 (dask#8484) Julia Signell使带
commentkwarg的read_csv即使在头部有注释也能工作 (dask#8433) Julia Signell
弃用¶
将
interpolation替换为method,并将method替换为internal_method(dask#8525) Julia Signell移除每日股票演示工具 (dask#8477) James Bourbeau
文档¶
修复变更日志章节超链接 (dask#8534) Aneesh Nema
为保持一致性,给“single-machine scheduler”加上连字符 (dask#8519) Deepyaman Datta
规范化
slicing.py中 doctests 的空白符 (dask#8512) Maren Westermann最佳实践存储行中的拼写错误 (dask#8529) Michael Delgado
更新图示 (dask#8401) Sarah Charlotte Johnson
从
read_parquetdocstring 中移除split_row_groups的pyarrow特有引用 (dask#8490) Naty Clementi
维护¶
移除对
fsspec>=2022.1.0失败的过时LocalFileSystem测试 (dask#8565) Richard (Rick) Zamora调整:“RuntimeWarning: invalid value encountered in reciprocal” (dask#8561) crusaderky
修复
DataFrame.sem中skipna=None的问题 (dask#8556) Julia Signell修复
PANDAS_GT_140(dask#8552) Julia Signell使用 HLG 的集合必须始终实现
__dask_layers__(dask#8548) crusaderky解决
import llvmlite中的竞态条件 (dask#8550) crusaderky设置
pyyaml的最低版本 (dask#8545) Gaurav Sheni向环境添加
nodefaults以修复tiledb+ mac 问题 (dask#8505) Julia Signell设置
setuptools的最高版本限制 (dask#8509) Julia Signell添加生成 Dask nightly 版本的工作流/配方 (dask#8469) Charles Blackmon-Luca
将 gpuCI
CUDA_VER提升至 11.5 (dask#8489) Charles Blackmon-Luca
2021.12.0¶
发布于 2021 年 12 月 10 日
新特性¶
添加
Series和Index的is_monotonic*方法 (dask#8304) Daniel Mesejo-León
改进¶
带有
partition_info的 Blockwisemap_partitions(dask#8310) Gabe Joseph改进未知块大小数组长度的错误消息 (dask#8436) Doug Davis
在 Groupby 类内部使用
by替换index(dask#8441) Julia Signell允许为
sort_values使用自定义排序函数 (dask#8345) Charles Blackmon-Luca当统计信息和分区不一致时,向
read_parquet添加警告 (dask#8416) Richard (Rick) Zamora
错误修复¶
修复
map_blocks在生成name时未使用自身参数的问题 (dask#8462) David Hoese修复读取空 parquet 文件时的索引错误 (dask#8410) Sarah Charlotte Johnson
修复写入分区 parquet 数据时可空 dtype 错误 (dask#8400) Richard (Rick) Zamora
修复 CSV 头部 bug (dask#8413) Richard (Rick) Zamora
修复空块导致
nanmin/nanmax抛出异常的问题 (dask#8375) Boaz Mohar
弃用¶
弃用
map_blocks的token关键字参数 (dask#8464) James Bourbeau针对
map_overlap中 boundary kwarg 默认值的弃用警告 (dask#8397) Genevieve Buckley
文档¶
澄清
block_info文档 (dask#8425) Genevieve Buckley来自 alt text sprint 的输出 (dask#8456) Sarah Charlotte Johnson
更新讲座和演示文稿 (dask#8370) Naty Clementi
更新文档“付费支持”部分中的 Anaconda 链接 (dask#8427) Martin Durant
修复 CuPy doctest 错误 (dask#8412) Genevieve Buckley
维护¶
将 Bokeh 最低版本提升至 2.1.1 (dask#8431) Bryan Van de Ven
修复
fsspec=2021.11.1发布后的问题 (dask#8428) Martin Durant将
dask/ml.py添加到 pytest 排除列表 (dask#8414) Genevieve Buckley将 gpuCI
RAPIDS_VER更新至22.02(dask#8394)解除
graphviz的版本锁定并改进 environment-3.7 中的包管理 (dask#8411) Julia Signell
2021.11.2¶
发布于 2021 年 11 月 19 日
仅每日运行 gpuCI bump 脚本 (dask#8404) Charles Blackmon-Luca
在
assert_eq中要求时实际忽略索引 (dask#8396) Gabe Joseph确保单分区 join 的
divisions是tuple(dask#8389) Charles Blackmon-Luca尝试使 divisions 的行为更清晰 (dask#8379) Julia Signell
修复
set_index的partition_size参数描述中的拼写错误 (dask#8384) FredericOdermatt在
single_partition_join中使用blockwise(dask#8341) Gabe Joseph使用更明确的关键字参数 (dask#8354) Boaz Mohar
修复带有可空布尔
dtype的 DataFrame 的.loc问题 (dask#8368) Marco Rossi移除一些文档构建警告 (dask#8369) Boaz Mohar
在数组 API 文档中包含 properties (dask#8356) Julia Signell
修复 Zarr 的上游问题 (dask#8367) Julia Signell
固定
graphviz版本以避免 windows 和 Python 3.7 的问题 (dask#8365) Julia Signell从模块顶部导入
graphviz.Diagraph,而不是从dot(dask#8363) Julia Signell
2021.11.0¶
发布于 2021 年 11 月 5 日
修复
read_parquet中required_extension的行为 (dask#8351) Richard (Rick) Zamora在
map_partitions中添加align_dataframes以广播作为参数传递的 dataframe (dask#6628) Julia Signell改进
dask.dataframe.loc中对键数组/系列的处理 (dask#8254) Julia Signell在
to_parquet中添加name_function选项 (dask#7682) Matthew Powers移除
environment-latest.yml并更新至 Python 3.9 (dask#8275) Julia Signell在 CI 中要求使用更新的
s3fs(dask#8336) James BourbeauGroupby Rolling (dask#8176) Julia Signell
向
dask.visualize添加更多排序诊断信息 (dask#7992) Erik Welchdemo_tuples生成了格式错误的HighLevelGraph(dask#8325) crusaderkyDask 日历应显示本地时间事件 (dask#8312) Genevieve Buckley
修复不稳定的
test_interrupt测试 (dask#8314) crusaderky废弃
AxisError(dask#8305) crusaderky修复扩展文档中 cuDF 的名称。 (dask#8311) Vyas Ramasubramani
向 parquet 过滤器添加单个等号运算符 (=) (dask#8300) Ayush Dattagupta
改进
read_parquet中对 Spark 输出的支持 (dask#8274) Richard (Rick) Zamora添加
dask.ml模块 (dask#6384) Matthew RocklinCI 修复 (dask#8298) James Bourbeau
使切片错误与 NumPy 匹配 (dask#8248) Julia Signell
修复使用新的 sphinx 主题时 API 文档渲染错误的问题 (dask#8296) Julia Signell
将
block属性替换为blockview用于块的类数组操作 (dask#8242) Davis Bennett废弃
file_path并使其可以在 notebook 中保存 (dask#8283) Julia Signell
2021.10.0¶
发布于 2021 年 10 月 22 日
da.store创建格式良好的HighLevelGraph(dask#8261) crusaderkyCI:在上游构建中强制使用每夜版
pyarrow(dask#8281) Joris Van den Bossche移除
chest(dask#8279) James Bourbeau如果未安装可选依赖项,则跳过 doctest (dask#8258) Genevieve Buckley
更新
tmpdir和tmpfile上下文管理器的 docstrings (dask#8270) Daniel Mesejo-León在 doctest 中注销回调 (dask#8276) James Bourbeau
陈旧标签 GitHub action (dask#8244) Genevieve Buckley
Client-shutdown 方法出现两次 (dask#8273) German Shiklov
将 pre-commit 添加到测试要求中 (dask#8257) Genevieve Buckley
重构
fastparquet引擎中的read_metadata(dask#8092) Richard (Rick) Zamora在
from_zarr中支持Path对象 (dask#8266) Samuel Gaist使嵌套重定向生效 (dask#8272) Julia Signell
如果在 info 中
verbose为True,则将memory_usage设置为True(dask#8222) Kinshuk Dua从 sphinx toctree 中移除单个 API 文档页面 (dask#8238) James Bourbeau
忽略 gufunc
signature中的空格 (dask#8267) James Bourbeau添加更新 gpuCI 的工作流程 (dask#8215) Charles Blackmon-Luca
DataFrame.head在只有一个分区时应该不发出警告 (dask#8091) Pankaj Patil如果未安装
pyarrow,则忽略 arrow doctest (dask#8256) Genevieve Buckley修复
debugging.html重定向 (dask#8251) James Bourbeau修复单个分区 dataframe 的 null 排序问题 (dask#8225) Charles Blackmon-Luca
修复
setup.html重定向 (dask#8249) Florian Jetter在 CI 中运行
pyupgrade(dask#8246) crusaderky修复上游 CI 构建中的标签拼写错误 (dask#8237) James Bourbeau
在 DataFrame.assign 中添加对“依赖”列的支持 (dask#8086) Suriya Senthilkumar
向
Array添加 Dask 键的 NumPy 数组 (dask#7922) Davis Bennett调整从
Executor中检索_max_workers的方式 (dask#8228) John A Kirkham更新
delayed最佳实践文档中的函数签名 (dask#8231) Vũ Trung Đức文档重组 (dask#7984) Julia Signell
修复
df.quantile在所有数据都缺失时的问题 (dask#8129) Julia Signell添加
tokenize.ensure-deterministic配置选项 (dask#7413) Hristo Georgiev在
pandas>=1.4.0和pd.date_range中使用inclusive而不是closed(dask#8213) Julia Signell将
dask-gateway、Coiled 和 Saturn-Cloud 添加到 Dask 设置工具列表中 (dask#7814) Kristopher Overholt确保在序列化
HighLevelGraph层时将现有 future 作为依赖项传递 (dask#8199) Jim Crist-Harif确保单个分区合并的 division 是左侧的 (dask#8162) Julia Signell
重构
pyarrowparquet 引擎中的read_metadata(dask#8072) Richard (Rick) Zamora在
map_blocks和map_overlap中支持负数drop_axis(dask#8192) Gregory R. Lee修复上游测试 (dask#8205) Julia Signell
添加对通过 Series 进行标量项赋值的支持 (dask#8195) Charles Blackmon-Luca
向
dask.bag的all、any、count方法的 doc string 添加一些基本示例 (dask#7630) Nathan Danielsen不要让上游报告依赖于提交消息 (dask#8202) James Bourbeau
确保上游 CI cron 作业运行 (dask#8200) James Bourbeau
使用
pytest.param正确标记特定参数的 GPU 测试 (dask#8197) Charles Blackmon-Luca将
test_set_index添加到 gpuCI 上运行的测试中 (dask#8198) Charles Blackmon-Luca抑制
tmpfile的 OSError 错误 (dask#8191) James Bourbeau在
set_partitions_pre中使用s.isna代替pd.isna(s)(修复 cudf CI) (dask#8193) Charles Blackmon-Luca为
test-upstream失败开一个 issue (dask#8067) Wallace Reis修复调用
pyarrow.parquet.read_metadata时to_parquet中的 bug (dask#8186) Richard (Rick) Zamora在
sort_values中添加对 null 值的处理 (dask#8167) Charles Blackmon-Luca提高 gpuCI 的
RAPIDS_VER版本 (dask#8184) Charles Blackmon-LucaDispatch 在惰性注册的处理器中遍历 MRO (dask#8185) Jim Crist-Harif
在
DataFrame.from_delayed中保留HighLevelGraphs(dask#8174) Gabe Joseph废弃用于 Dask series 重命名的
inplace参数 (dask#8136) Marcel Coetzee修复 rolling 以兼容
pandas > 1.3.0(dask#8150) Julia Signell在对未知块执行
setitem时抛出错误 (dask#8166) Julia Signell在执行
Index.to_series时包含 division (dask#8165) Julia Signell
2021.09.1¶
发布于 2021 年 9 月 21 日
修复面向未来 pandas 版本的
groupby(dask#8151) Julia Signell移除测试中不再需要的警告过滤器 (dask#8155) Julia Signell
在本地诊断文档中添加指向诊断可视化函数的链接 (dask#8157) David Hoese
向
dataframe.describe添加datetime_is_numeric(dask#7719) Julia Signell在
pd.Int64Index废弃之前移除对其的引用 (dask#8144) Julia Signell如果需要,对 series 的
__get_item__使用loc(dask#7953) Julia Signell对于空切片的 mean 专门忽略警告 (dask#8125) Julia Signell
对于 pandas >= 1.3.3 跳过
groupbynunique测试 (dask#8142) Julia Signell为
sort_values实现ascending参数 (dask#8130) Charles Blackmon-Luca替换
operator.getitem(dask#8015) Naty Clementi废弃
zero_broadcast_dimensions和homogeneous_deepmap(dask#8134) SnkSynthesis允许
scheduler是一个Executor(dask#8112) John A Kirkham处理
like是dask.Array的asarray/asanyarray情况 (dask#8128) Peter Andreas Entschev向
asarray和asanyarray定义添加dtype和order(dask#8106) Julia Signell废弃
dask.dataframe.Series.__contains__(dask#7914) Julia Signell修复
_wrapped_qr中like-数组的边缘情况问题 (dask#8122) Peter Andreas Entschev废弃
boundary_slice的 kwarg: 为了兼容 pandas 废弃kind(dask#8037) Julia Signell
2021.09.0¶
发布于 2021 年 9 月 3 日
减少打开的文件数 (dask#7303) Julia Signell
将
FileNotFound添加到预期的 http 错误中 (dask#8109) Martin Durant将
DataFrame.sort_values添加到 API 文档中 (dask#8107) Benjamin Zaitlen更改
dask.order: 有时更积极 (dask#7929) Erik Welch向 CI 添加 pytest 颜色 (dask#8090) James Bourbeau
向 Dataframe copy 方法添加
deep参数并将其限制为False(dask#8068) João Paulo Lacerda修复配置文档中的拼写错误 (dask#8104) Robert Hales
更新
DataFrame.querydocstring 中的格式 (dask#8100) James Bourbeau解除
sparse测试在 0.13.0 版本中的 xfail (dask#8102) James Bourbeau向 DataFrame 和 Series 添加 axes 属性 (dask#8069) Jordan Jensen
在
da.unique中添加 CuPy 支持 (仅限值) (dask#8021) Peter Andreas Entschevsparse.zeros_like的单元测试 (xfailed) (dask#8093) crusaderky向数组创建函数添加明确的
likekwarg 支持 (dask#8054) Peter Andreas Entschev分离 Array 和 DataFrame 的最小依赖构建 (dask#8079) James Bourbeau
将
percentile_dispatch分离到dask.array中 (dask#8083) GALI PREM SAGAR确保
to_parquet中的filepath存在 (dask#8057) James Bourbeau更新
test_scheduler_highlevel_graph_unpack_import中的调度器插件用法 (dask#8080) James Bourbeau向 API 文档添加
DataFrame.shuffle(dask#8076) Martin Fleischmann按字母顺序排序要求 (dask#8073) John A Kirkham
2021.08.1¶
发布于 2021 年 8 月 20 日
向
read_parquet添加ignore_metadata_file选项 (仅支持pyarrow-dataset和fastparquet) (dask#8034) Richard (Rick) Zamora在开发文档中添加对
pytest-xdist的引用 (dask#8066) Julia Signell在
to_datetime生成的 meta 中包含tz(dask#8000) Julia SignellCI 基础设施文档 (dask#7985) Benjamin Zaitlen
在
assert_eq检查中包含无效的 DataFrame 键 (dask#8061) James Bourbeau在创建 DataFrames 时使用
__class__(dask#8053) Mads R. B. Kristensen在 gpuCI 构建中使用开发版本
distributed(dask#7976) James Bourbeau忽略 gufunc
signature中的空格 (dask#8049) James Bourbeau移动 pandas 导入并重构 percentile dispatch (dask#8055) GALI PREM SAGAR
添加颜色表示高级层类型 (dask#7974) Freyam Mehta
上游实例修复 (dask#8060) Jacob Tomlinson
添加
dask.widgets并将 HTML reprs 迁移到jinja2(dask#8019) Jacob Tomlinson移除
wrap_func_like_safe,NumPy >= 1.17 后不再需要 (dask#8052) Peter Andreas Entschev修复线程调度器内存背压回退问题 (dask#8040) David Hoese
添加 percentile dispatch (dask#8029) GALI PREM SAGAR
在
groupby中使用公开文档记录的属性obj,而不是私有的_selected_obj(dask#8038) GALI PREM SAGAR在某些情况下使用
dict存储 {nan,}arg{min,max} 的数据 (dask#8014) Peter Andreas Entschev修复
read_pandas中blocksize描述的格式问题 (dask#8047) Louis Maddox修复文档中“point” -> “pointers” 的拼写错误 (dask#8043) David Chudzicki
2021.08.0¶
发布于 2021 年 8 月 13 日
修复
to_orc延迟计算行为 (dask#8035) Richard (Rick) Zamora在
compute_as_if_collection中不转换为低级任务图 (dask#7969) James Bourbeau修复 hdf 的多文件读取 (dask#8033) Julia Signell
解决
distributed测试中的警告 (dask#8025) James Bourbeau更新
to_orc集合名称 (dask#8024) James Bourbeau对传递给
to_datetime的不可索引参数抛出NotImplementedError(dask#7989) Doug Davis确保对来自
distributed的警告报告错误 (dask#8002) James Bourbeau为 graphviz 高级图添加工具提示 (dask#7973) Freyam Mehta
关闭 2021 用户调查 (dask#8007) Julia Signell
将 CuPy 测试重组到多个文件中 (dask#8013) Peter Andreas Entschev
重构和扩展 Dask-Dataframe ORC API (dask#7756) Richard (Rick) Zamora
如果
enforce=False则不强制执行列检查 (dask#7916) Julia Signell修复当
drop_axis不是None时map_overlap的修剪行为 (dask#7894) Gregory R. Lee将 gpuCI CuPy 测试标记为不稳定 (dask#7994) Peter Andreas Entschev
避免在
to_csv和to_parquet中使用Delayed(dask#7968) Matthew Rocklin使用
pytest.warns而不是 raises 检查 parquet 引擎废弃 (dask#7993) Joris Van den Bossche将 gpuCI 中的
RAPIDS_VER提高到 21.10 (dask#7991) Charles Blackmon-Luca为
pyarrow>=5重新添加pyarrow-legacy测试覆盖 (dask#7988) Richard (Rick) Zamora在
to_parquet和read_parquet中允许使用pyarrow>=5(dask#7967) Richard (Rick) Zamora当 NumPy < 1.20 可用时,跳过需要 NEP-35 的 CuPy 测试 (dask#7982) Peter Andreas Entschev
向
SeriesGroupby添加tail和head(dask#7935) Daniel Mesejo-León更新月度会议的 Zoom 链接 (dask#7979) James Bourbeau
添加 gpuCI 构建脚本 (dask#7966) Charles Blackmon-Luca
废弃
daily_stock工具 (dask#7949) James Bourbeau将
distributed.nanny添加到配置参考文档中 (dask#7955) James Bourbeau要求 NumPy 1.18+ 和 Pandas 1.0+ (dask#7939) John A Kirkham
2021.07.2¶
发布于 2021 年 7 月 30 日
注意
这是支持 NumPy 1.17 和 pandas 0.25 的最后一个版本。从下一版本开始,NumPy 1.18 和 pandas 1.0 将成为最低支持版本。
将
dask.arraySVG 添加到 HTML Repr 中 (dask#7886) Freyam Mehta避免在
to_parquet中使用Delayed(dask#7958) Matthew Rocklin在 CI 中暂时固定
pyarrow<5(dask#7960) James Bourbeau为顶层
ucx和rmm配置值添加废弃警告 (dask#7956) James Bourbeau移除 doctest 中的跳过 (4/6) (dask#7865) Zhengnan Zhao
移除 doctest 中的跳过 (5/6) (dask#7864) Zhengnan Zhao
向
da.diff添加缺失的前置/后置功能 (dask#7946) Peter Andreas Entschev将 graphviz 字体系列更改为 sans (dask#7931) Freyam Mehta
修复 read-csv 名称 - 当路径不同时,为任务使用不同的名称 (dask#7942) Julia Signell
更新
ucx和rmm更改的配置参考 (dask#7943) James Bourbeau向
__setitem__添加 meta 支持 (dask#7940) Peter Andreas Entschevslice_with_int_dask_array的 NEP-35 支持 (dask#7927) Peter Andreas Entschev解除 CI 中的 fastparquet 固定 (dask#7928) James Bourbeau
移除 doctest 中的跳过 (3/6) (dask#7872) Zhengnan Zhao
2021.07.1¶
发布于 2021 年 7 月 23 日
使 array
assert_eq检查 dtype (dask#7903) Julia Signell移除 doctest 中的跳过 (6/6) (dask#7863) Zhengnan Zhao
移除 actors 文档中的实验性功能警告 (dask#7925) Matthew Rocklin
移除 doctest 中的跳过 (2/6) (dask#7873) Zhengnan Zhao
分离 Array 和 Bag API (dask#7917) Julia Signell
实现 lazy
Array.__iter__(dask#7905) Julia Signell清理无意中迭代数组的地方 (dask#7913) Julia Signell
向 DataFrame reductions 添加
numeric_onlykwarg (dask#7831) Julia Signell为 GPU 测试添加 pytest 标记 (dask#7876) Charles Blackmon-Luca
在
dask.array中添加对histogram2d的支持 (dask#7827) Doug Davis移除 doctest 中的跳过 (1/6) (dask#7874) Zhengnan Zhao
为高级图的 Graphviz 输出添加节点大小缩放 (dask#7869) Freyam Mehta
更新旧的 Bokeh 链接 (dask#7915) Bryan Van de Ven
在 CI 中暂时固定
fastparquet(dask#7907) James Bourbeau向进度条文档添加
dask.array导入 (dask#7910) Fabian Gebhart为每个 DataFrame API 函数和方法使用单独的文件 (dask#7890) Julia Signell
修复
pyarrow-dataset排序 bug (dask#7902) Richard (Rick) Zamora泛化 unique aggregate (dask#7892) GALI PREM SAGAR
使用
pd.Grouper时抛出NotImplementedError(dask#7857) Ruben van de Geer添加
aggregate_files参数以在read_parquet中启用多文件分区 (dask#7557) Richard (Rick) Zamora解除
test_daily_stock的xfail标记 (dask#7895) James Bourbeau更新访问配置文档 (dask#7837) Naty Clementi
使用 packaging 进行版本比较 (dask#7820) Elliott Sales de Andrade
处理
merge_asof中的无限循环 (dask#7842) gerrymanoim
2021.07.0¶
发布于 2021 年 7 月 9 日
在上游 CI 构建中包含
fastparquet(dask#7884) James BourbeauBlockwise: 处理非字符串常量依赖项 (dask#7849) Mads R. B. Kristensen
fastparquet现在支持新的时间类型,包括纳秒精度 (dask#7880) Martin Durant在
ArrowDatasetEngine中进行追加时避免使用ParquetDatasetAPI (dask#7544) Richard (Rick) Zamora向
test_shuffle_priority添加重试逻辑 (dask#7879) Richard (Rick) Zamora在 CI 中使用严格的 channel 优先级 (dask#7878) James Bourbeau
支持嵌套的
dask.distributed导入 (dask#7866) Matthew Rocklin应该只检查模块名称,而不是整个目录的文件路径 (dask#7856) Genevieve Buckley
因 https://github.com/dask/fastparquet/pull/623 而进行的更新 (dask#7875) Martin Durant
da.eye对chunks=-1的修复 (dask#7854) Naty Clementi暂时将
test_daily_stock标记为 xfail (dask#7858) James Bourbeau在
SimpleShuffleLayer中设置优先级标注 (dask#7846) Richard (Rick) ZamoraBlockwise: 将常量键输入转换为字符串 (dask#7838) Mads R. B. Kristensen
允许在
@guvectorize中混合使用 dask 和 numpy 数组 (dask#6863) Julia Signell在计算 shuffle 组大小时不对其 dict 结果进行抽样 (dask#7834) Florian Jetter
修复 scipy 测试 (dask#7841) Julia Signell
确定性地对
datetime.date进行 tokenize (dask#7836) James Bourbeau向类
read_csv添加sample_rows(dask#7825) Martin Durant修复
config.deserializedocstring 中的拼写错误 (dask#7830) Geoffrey Lentner移除
test_dataframe_picklable中的警告过滤器 (dask#7822) James Bourbeau改进
histogramdd(用于处理输入为数组序列的情况)。(dask#7634) Doug Davis使
PY_VERSION成为私有 (dask#7824) James Bourbeau
2021.06.2¶
发布于 2021 年 6 月 22 日
layers.py比较parts_out与set(self.parts_out)(dask#7787) Genevieve Buckley使
check_meta更好地理解 pandas dtypes (dask#7813) Julia Signell移除“教育资源”文档页面 (dask#7818) James Bourbeau
2021.06.1¶
发布于 2021 年 6 月 18 日
将 funding 页面替换为 dask.org 上的“由…支持”部分 (dask#7817) James Bourbeau
添加初始的废弃工具 (dask#7810) James Bourbeau
在明确使用
dtype=的 ufuncs 中强制执行 dtype 保留 (dask#7808) Doug Davis将 Coiled 添加到付费支持组织列表中 (dask#7811) Kristopher Overholt
对
Layer和HighLevelGraph的 HTML repr 进行微调 (dask#7812) Genevieve Buckley向 HLG HTML repr 添加深色模式支持 (dask#7809) Jacob Tomlinson
移除对旧 distributed 的兼容性条目 (dask#7801) Elliott Sales de Andrade
实现
HighLevelGraph层的 HTML repr (dask#7763) Genevieve Buckley更新默认
blockwisetoken 以避免 DataFrame 列名冲突 (dask#6546) James Bourbeau对
merge_asof使用 dispatchconcat(dask#7806) Julia Signell修复上游 freq 测试 (dask#7795) Julia Signell
使用标准库中更多的上下文管理器 (dask#7796) James Bourbeau
简化 parquet 测试中的跳过 (dask#7802) Elliott Sales de Andrade
移除对过时 bokeh 的检查 (dask#7804) Elliott Sales de Andrade
更多测试覆盖率上传 (dask#7799) James Bourbeau
从
dask/__init__.py中移除ImportError捕获 (dask#7797) James Bourbeau允许
DataFrame.join()接受一个 DataFrame 列表进行合并 (dask#7578) Krishan Bhasin修复
dask.array.linspace中的最大递归深度异常 (dask#7667) Daniel Mesejo-León修复文档链接 (dask#7794) Julia Signell
初始的
da.select()实现和测试 (dask#7760) Gabriel Miretti层必须实现
get_output_keys方法 (dask#7790) Genevieve Buckley不要在 division 中包含或期望
freq(dask#7785) Julia Signellmap_overlap的HighLevelGraph抽象层 (dask#7595) Genevieve Buckley在
drop中始终包含 kwarg 名称 (dask#7784) Julia Signell仅在需要时对 median 进行 rechunk (dask#7782) Julia Signell
向 DataFrame 和 Series 添加
add_(prefix|suffix)(dask#7745) tsuga将
read_hdf移动到Blockwise(dask#7625) Richard (Rick) Zamora正式将
Layer.get_output_keys设为抽象方法 (dask#7775) Genevieve Buckleyravel_multi_index中的非 dask 数组和广播 (dask#7594) Gabe Joseph修复 parquet 覆盖中以“/”结尾的路径问题 (dask#7773) Martin Durant
修复使用
filename=None调用.visualize()的问题 (dask#7740) Freyam Mehta为
SubgraphCallable生成唯一的名称 (dask#7637) Bruce Merry在 CI 中将
fsspec固定到2021.5.0(dask#7771) James Bourbeau如果在
from_delayed中提供了 meta,则延迟评估图 (dask#7769) Florian Jetter为
DatetimeTZDtype添加meta支持 (dask#7627) gerrymanoim向自动 PR 标签器添加 dispatch 标签 (dask#7701) James Bourbeau
修复 HDFS 测试 (dask#7752) Julia Signell
2021.06.0¶
发布于 2021 年 6 月 4 日
在
rewrite_blockwise的图键中移除抽象令牌 (dask#7721) Richard (Rick) Zamora确保 csv
project_columns中的列顺序正确 (dask#7761) Richard (Rick) Zamora重命名内部循环变量以避免重复 (dask#7741) Boaz Mohar
不要从
to_zarr返回延迟对象 (dask#7738) Chris RoatArray: 在
apply_gufunc中输出数量正确 (dask#7669) Gabe Joseph使用
da.blockwise重写da.fromfunction(dask#7704) John A Kirkham将
make_meta_util重命名为make_meta(dask#7743) GALI PREM SAGAR如果请求的分区少于输入分区,则在 shuffle 前重新分区 (dask#7715) Vibhu Jawa
Blockwise: 处理常量键输入 (dask#7734) Mads R. B. Kristensen
在
apply_gufunc中添加了 raise (dask#7744) Boaz Mohar在 CI 中显示失败测试摘要 (dask#7735) Genevieve Buckley
Python 3.9 中集合的
sizeof(dask#7739) Mads R. B. Kristensen如果在
dataframe.__getitem__中使用 pandas 日期时间字符串则发出警告 (dask#7749) Julia Signell突出显示
client.dashboard_link(dask#7747) Genevieve Buckley订阅 Google 日历的更便捷链接 (dask#7733) Genevieve Buckley
在 Jupyter notebook 中自动显示图可视化 (dask#7716) Genevieve Buckley
在 API 文档中为
unify_chunks添加autofunction(dask#7730) James Bourbeau
2021.05.1¶
发布于 2021 年 5 月 28 日
Pandas 兼容性 (dask#7712) Julia Signell
修复
optimize_dataframe_getitem错误 (dask#7698) Richard (Rick) Zamora更新文档中的
make_meta导入 (dask#7713) Benjamin Zaitlen修复错误消息中的格式字符串 (dask#7706) Jiaming Yuan
在
support.rst中添加 slack 加入链接 (dask#7679) Naty Clementi移除未使用的 alphabet 变量 (dask#7700) James Bourbeau
修复
object情况下的 meta 创建问题 (dask#7586) GALI PREM SAGAR为
union_categoricals添加分派 (dask#7699) GALI PREM SAGAR整合 array
Dispatch对象 (dask#7505) James Bourbeau将 DataFrame
dispatch.registers移至独立文件 (dask#7503) Julia Signell修复
dataclasses中当init=False时 delayed 的问题 (dask#7656) Julia Signell允许列命名为
divisions(dask#7605) Julia Signell堆叠具有未知块的 nd 数组 (dask#7562) Chris Roat
宣传 2021 Dask 用户调查 (dask#7694) Genevieve Buckley
修复
DataFrame.set_index()中的拼写错误 (dask#7691) James Lamb清理 array API 参考链接 (dask#7684) David Hoese
接受
flip的axis元组,与 NumPy 保持一致 (dask#7675) Andrew Champion提升
pre-commithook 版本 (dask#7676) James Bourbeau清理
to_zarr的文档字符串 (dask#7683) David Hoese修复
read_orc的文档字符串 (dask#7678) Justus Magin文档
ipyparallel和mpi4pyconcurrent.futures(dask#7665) John A Kirkham更新测试以支持 CuPy 9 (dask#7671) Peter Andreas Entschev
修复
HighLevelGraph文档中的一些不准确之处 (dask#7662) Mads R. B. Kristensen修复 Series
getitem错误消息中的拼写错误 (dask#7659) Maisie Marshall
2021.05.0¶
发布于 2021 年 5 月 14 日
移除已废弃的
kind关键字参数以符合 pandas 1.3.0 (dask#7653) Julia Signell修复 DataFrame 列投影中的错误 (dask#7645) Richard (Rick) Zamora
打包时合并全局注解 (dask#7565) Mads R. B. Kristensen
避免在 pandas
set_categories中使用inplace=(dask#7633) James Bourbeau将 Dask-Dataframe 的 active-fusion 默认值更改为
False(dask#7620) Richard (Rick) ZamoraArray: 移除
RandomState中的无关代码 (dask#7487) Gabe Joseph实现
str.concat当others=None时 (dask#7623) Daniel Mesejo-León修复沙盒环境中的
dask.dataframe(dask#7601) Noah D. Brenowitz支持
cupyx.scipy.linalg(dask#7563) Benjamin Zaitlen将
timeseries和 daily-stock 移至Blockwise(dask#7615) Richard (Rick) Zamora修复广播连接中的错误 (dask#7617) Richard (Rick) Zamora
对 DataFrame IO (parquet, csv, 和 orc) 使用
Blockwise(dask#7415) Richard (Rick) Zamora将块和类型信息添加到 Dask
HighLevelGraphs (dask#7309) Genevieve Buckley移除对测试频率的跳过 (dask#7608) Julia Signell
移除
ignore_abc_warning(dask#7606) Julia Signell加强 DataFrame 列选择和索引之间的合并 (dask#7575) Richard (Rick) Zamora
移除
ignore_abc装饰器 (dask#7604) Julia Signell移除 bokeh 的关键字参数验证 (dask#7597) Julia Signell
添加
loky示例 (dask#7590) Naty ClementiDelayed: 参数变为任务时的
nout(dask#7593) Gabe Joseph在 mindep CI 构建中更新 distributed 版本 (dask#7602) James Bourbeau
支持分区列和实际列之间全部或无重叠 (dask#7541) Richard (Rick) Zamora
2021.04.1¶
发布于 2021 年 4 月 23 日
处理
BlockwiseHLG 的打包/解包,用于concatenate=True(dask#7455) Richard (Rick) Zamoramap_partitions: 使用标记化信息作为SubgraphCallable的名称 (dask#7524) Mads R. B. Kristensen使用
tmp_path和tmpdir避免临时文件和目录留在仓库中 (dask#7592) Naty Clementi贡献文档(开发指南) (dask#7591) Naty Clementi
为 Python 3.9 CI 构建添加更多软件包 (dask#7588) James Bourbeau
Array: 修复 finalize 中的 NEP-18 分派 (dask#7508) Gabe Joseph
对
numpydoc的杂项修复 (dask#7569) Matthias Bussonnier避免 pandas
level=关键字废弃 (dask#7577) James Bourbeau将例如
.repartition(freq="M")映射到.repartition(freq="MS")(dask#7504) Ruben van de Geer移除并行 CI 运行中的哈希种子设置 (dask#7128) Elliott Sales de Andrade
简化转置轴清理 (dask#7561) Julia Signell
明确说明
len(index_names) > 1的ValueError正在使用fastparquet(dask#7556) Ray Bell修复
pyarrowparquet 引擎的dict-列附加问题 (dask#7527) Richard (Rick) Zamora添加文档自动标签 (dask#7560) Doug Davis
将
dask.delayed.Delayed添加到文档中,以便其他 sphinx 文档可以引用它 (dask#7559) Doug Davis修复上游
idxmaxmin不均匀时的split_every(dask#7538) Julia Signell使 pandas
Series/DataFrame的normalize_token更具未来性(无直接块访问) (dask#7318) Joris Van den Bossche重新设计的
__setitem__实现 (dask#7393) David Hassellhistogram,histogramdd改进(文档;返回一致性) (dask#7520) Doug Davis在上游构建中强制使用每夜版
pyarrow(dask#7530) Joris Van den Bossche修复配置参考 (dask#7533) Benjamin Zaitlen
避免 HLGs 的双重
msgpack序列化 (dask#7525) Mads R. B. Kristensen鼓励在配置文档中使用
yaml.safe_load()(dask#7529) Hristo Georgiev支持
to_parquet中的custom_metadata=参数 (dask#7359) Richard (Rick) Zamora清理一些文档警告 (dask#7518) Daniel Mesejo-León
消除更多文档警告 (dask#7426) Julia Signell
添加了
product(别名prod) (dask#7517) Freyam Mehta修复上游
__array_ufunc__测试 (dask#7494) Julia Signell如果深度为零,则从
map_overlap逃逸到map_blocks(dask#7481) Genevieve Buckley将
check_type添加到数组assert_eq(dask#7491) Julia Signell
2021.04.0¶
发布于 2021 年 4 月 2 日
添加对多维直方图的支持,使用
dask.array.histogramdd(dask#7387) Doug Davis当 PR 中触及特定文件时自动添加标签 (dask#7506) Julia Signell
从
kwargs中提取ignore_order(dask#7500) GALI PREM SAGAR仅在缺少 distributed 时提供安装说明 (dask#7498) Matthew Rocklin
开始添加
isort(dask#7370) Julia Signell在
dd.concat中添加ignore_order参数 (dask#7473) Daniel Mesejo-León显示 RAM 时使用 2 的幂 (dask#7484) crusaderky
添加许可证分类器 (dask#7485) Tom Augspurger
将 conda 替换为 mamba (dask#7227) crusaderky
修复 array 文档中的拼写错误 (dask#7478) James Lamb
在本地调度器中使用
concurrent.futures(dask#6322) John A Kirkham
2021.03.1¶
发布于 2021 年 3 月 26 日
添加一个
is_categorical_dtype的分派以处理非 pandas 对象 (dask#7469) brandon-b-miller在
test_read_text中使用multiprocessing.Pool(dask#7472) John A Kirkham为 gufunc 类添加缺失的
meta关键字参数 (dask#7423) Peter Andreas Entschev内存映射 Dask 数组的示例 (dask#7380) Dieter Weber
修复 NumPy 上游故障,
xfailpandas 和 fastparquet 故障 (dask#7441) Julia Signell修复 repartition 中使用 freq 时的错误 (dask#7357) Ruben van de Geer
修复
tril/triu的__array_function__分派 (dask#7457) Peter Andreas Entschev在少量测试中使用
concurrent.futures.Executors(dask#7429) John A Kirkham要求 NumPy >=1.16 (dask#7383) crusaderky
微小的
sort_values整理 (dask#7462) Ryan Williams确保 parquet 部分路径中的自然排序顺序 (dask#7249) Ryan Williams
运行
test_config.py时移除全局环境变量修改 (dask#7464) Hristo Georgiev更新 NumPy intersphinx URL (dask#7460) Gabe Joseph
添加
rot90(dask#7440) Trevor Manz更新 endpoint 所需软件包的文档 (dask#7454) Nick Vazquez
slice_array文档字符串中的 Master -> main (dask#7453) Gabe Joseph扩展
dask.utils.is_arraylike文档字符串 (dask#7445) Doug Davis简化
BlockwiseIODeps导入 (dask#7420) Richard (Rick) Zamora更新层注解打包方法 (dask#7430) James Bourbeau
在
test_describe_empty中移除重复测试 (dask#7431) John A Kirkham添加了 df 的
kurtosis方法和测试 (dask#7273) Jan Borchmann避免 HLG 剔除的二次时间性能 (dask#7403) Bruce Merry
暂时跳过有问题的
sparse测试 (dask#7421) James Bourbeau更新一些 CI 工作流名称 (dask#7422) James Bourbeau
修复 HDFS 测试 (dask#7418) Julia Signell
使变更日志副标题与层级结构匹配 (dask#7419) Julia Signell
在
value_counts中添加对normalize的支持 (dask#7342) Julia Signell避免 HLG 层解包和实例化时的不必要导入 (dask#7381) Richard (Rick) Zamora
Bincount 切片修复 (dask#7391) Genevieve Buckley
添加
sliding_window_view(dask#7234) Deepak Cherian修复
docs/source/develop.rst中的拼写错误 (dask#7414) Hristo Georgiev将 PR 的文档构建切换到 readthedocs (dask#7397) James Bourbeau
将
sort_values添加到 dask.DataFrame (dask#7286) gerrymanoim在 CI 中锁定
sqlalchemy<1.4.0版本 (dask#7405) James Bourbeau注释修复 (dask#7215) Ryan Williams
死代码移除/修复 (dask#7388) Ryan Williams
对
pa.Table.from_pandas调用使用单线程 (dask#7347) Richard (Rick) Zamora将
'container'替换为'image'(dask#7389) James Lamb在
bag.read_text中将分隔符传递给fsspec(dask#7349) Martin Durant打包时将字面值嵌入到
SubgraphCallable中 (dask#7353) Mads R. B. Kristensen要求额外依赖项:cloudpickle, partd, fsspec, toolz (dask#7345) Julia Signell
准备
Blockwise+ IO 基础设施 (dask#7281) Richard (Rick) Zamora移除
test_slicing.py中的重复导入 (dask#7365) Hristo Georgiev为 pip 开发添加测试依赖项 (dask#7360) Julia Signell
支持对非 NumPy 数组进行整数切片 (dask#7364) Peter Andreas Entschev
自动取消之前的 CI 构建 (dask#7348) James Bourbeau
dask.array.asarray应处理xarray类在顶级命名空间中的情况 (dask#7335) Tom WhiteHighLevelGraph的长度,无需实例化层 (dask#7274) Gabe Joseph停止支持 Python 3.6 (dask#7006) James Bourbeau
修复
create_metadata_file中fsspec的使用 (dask#7295) Richard (Rick) Zamora将默认分支从 master 更改为 main (dask#7198) Julia Signell
将 Xarray 添加到 CI 软件环境 (dask#7338) James Bourbeau
更新错误文本中的 repartition 参数名称 (dask#7336) Eoin Shanaghy
根据 commit 消息运行上游测试 (dask#7329) James Bourbeau
在 util 模块上使用
pytest.register_assert_rewrite(dask#7278) Bruce Merry添加在
from_array()中使用特定块大小的示例 (dask#7330) James Lamb将 NumPy 跳过移至测试中 (dask#7247) Julia Signell
2021.03.0¶
发布于 2021 年 3 月 5 日
注意
这是第一个支持 Python 3.9 的版本,也是最后一个支持 Python 3.6 的版本
提升
distributed的最低版本 (dask#7328) James Bourbeau修复
percentiles_summary与dask_cudf的问题 (dask#7325) Peter Andreas Entschev暂时恢复最近的
Array.__setitem__更新 (dask#7326) James BourbeauBlockwise.clone(dask#7312) crusaderkyNEP-35 duck array 更新 (dask#7321) James Bourbeau
不允许为数组设置
.name(dask#7222) Julia Signell使用最近邻插值创建整数输入的百分位数 (dask#7305) Kyle Barron
测试
exp使用 CuPy 数组 (dask#7322) John A Kirkham检查计算出的块是否具有正确的尺寸和 dtype (dask#7277) Bruce Merry
pytest.mark.flaky(dask#7319) crusaderky贡献文档:添加说明,在 pip 安装 Dask 之前拉取最新的 git 标签 (dask#7308) Genevieve Buckley
支持 Python 3.9 (dask#7289) crusaderky
添加基于广播的合并实现 (dask#7143) Richard (Rick) Zamora
将
split_every添加到graph_manipulation(dask#7282) crusaderkyoptimize 文档中的拼写错误 (dask#7306) Julius Busecke
dask.graph_manipulation支持xarray.Dataset(dask#7276) crusaderky添加对 Bokeh 2.3.0 图形宽度和高度的支持 (dask#7297) James Bourbeau
添加 NumPy 函数
tri,triu_indices,triu_indices_from,tril_indices,tril_indices_from(dask#6997) Illviljan移除 DataFrame 磁盘 shuffle 中的“清理”任务 (dask#7260) Sinclair Target
在 CI 中使用开发版本的
distributed(dask#7279) James Bourbeau移动 Dask 高层图打包/解包 (dask#7179) Mads R. B. Kristensen
提升
merge_percentiles的性能 (dask#7172) Ashwin Srinath为
bincount添加树状归约 (dask#7183) Thomas J. Fan改进
from_array中name的文档 (dask#7264) Bruce Merry修复空分区的
cumsum(dask#7230) Julia Signell为 dask array 创建文档添加
map_blocks示例 (dask#7221) Julia Signell修复
dask.graph_manipulation.wait_on()中的性能问题 (dask#7258) crusaderky将 coveralls 替换为 codecov.io (dask#7246) crusaderky
在 pre-commit 中锁定特定
black版本 (dask#7256) Julia Signell文档中的小错误:
array-chunks.rst(dask#7254) Magnus Nord修复
Blockwise和ShuffleLayer中的错误 (dask#7213) Richard (Rick) Zamora修复
"pyarrow-dataset"的 parquet 过滤错误,使用 pyarrow-3.0.0 (dask#7200) Richard (Rick) Zamoragraph_manipulation不使用 NumPy (dask#7243) crusaderky支持 NEP-35 (dask#6738) Peter Andreas Entschev
在 doctest CI 构建期间避免运行单元测试 (dask#7240) James Bourbeau
在 CI 上运行 doctest (dask#7238) Julia Signell
清理集合运算的代码质量 (dask#7196) crusaderky
添加
dask.array.delete(dask#7125) Julia Signell新的 conda-forge recipe 构建完成后取消锁定 graphviz (dask#7235) Julia Signell
在 Mac 上不使用来自 conda-forge 的 NumPy 1.20 (dask#7211) crusaderky
map_overlap: 不要重新分块没有重叠的轴 (dask#7233) Deepak Cherian锁定 graphviz 版本以避免最新的 conda-forge 构建问题 (dask#7232) Julia Signell
在文档中使用
html_css_files用于自定义 CSS (dask#7220) James Bourbeau图操作:
clone,bind,checkpoint,wait_on(dask#7109) crusaderky修复 parquet
pyarrow-dataset引擎中过滤表达式的处理 (dask#7186) Joris Van den Bossche扩展
__setitem__使其更接近 numpy (dask#7033) David Hassell清理 Python 2 语法 (dask#7195) crusaderky
修复
Delayed._length中的回归问题 (dask#7194) crusaderky__dask_layers__()测试和调整 (dask#7177) crusaderky在多进程调度器中正确转换
HighLevelGraph(dask#7191) Jim Crist-Harif在 CI 中不快速失败 (dask#7188) James Bourbeau
2021.02.0¶
发布于 2021 年 2 月 5 日
添加对 NEP-35 的
percentile支持 (dask#7162) Peter Andreas Entschev在列赋值中添加了对
Float64的支持 (dask#7173) Nils BraunCoarsen rechunking 错误 (dask#7127) Davis Bennett
修复上游 CI 测试 (dask#6896) Julia Signell
修订
HighLevelGraphMapping API (dask#7160) crusaderky更新低层图规范以使用任何可哈希对象作为键 (dask#7163) James Bourbeau
使用不同的键通用地重建集合 (dask#7142) crusaderky
修复数组设计文档中的链接 (dask#7152) Thomas J. Fan
修复使用
blockwise进行外积的示例 (dask#7119) Bruce Merry弃用
HighlevelGraph.dicts转而使用.layers(dask#7145) Amit Kumar使
FastParquetEngine与 pyarrow 引擎对齐 (dask#7091) Richard (Rick) Zamora简化
read_parquet中 parts 列表的内容 (dask#7066) Richard (Rick) Zamoracheck_meta(): 检查 DataFrame 类型时使用__class__(dask#7099) Mads R. B. Kristensen修复 parquet
getitem优化 (dask#7106) Richard (Rick) Zamora将 cytoolz 重新添加到 CI 环境 (dask#7103) James Bourbeau
2021.01.1¶
发布于 2021 年 1 月 22 日
部分修复
cumprod(dask#7089) Julia Signell测试 pandas 1.1.x / 1.2.0 版本和 pandas nightly (dask#6996) Joris Van den Bossche
使用 assign 避免
SettingWithCopyWarning(dask#7092) Julia Signell'mode'参数传递给bokeh.output_file()(dask#7034) (dask#7075) patquem在执行
groupby.value_counts时跳过空分区 (dask#7073) Julia Signell向
assert_eq()添加错误消息 (dask#7083) James Lamb
2021.01.0¶
发布于 2021 年 1 月 15 日
map_partitions带有评审意见 (dask#6776) Kumar Bharath Prabhu确保
population是一个真实的列表 (dask#7027) Julia Signell在
read_csv中传播storage_options(dask#7074) Richard (Rick) Zamora移除所有
BlockwiseIO代码 (dask#7067) Richard (Rick) Zamora修复 CI (dask#7069) James Bourbeau
在
reshape中添加控制 rechunking 的选项 (dask#6753) Tom Augspurger修复复杂输入的
linalg.lstsq问题 (dask#7056) Johnnie Gray添加
read_csv的compression='infer'默认值 (dask#6960) Richard (Rick) Zamora恢复
svd_compressed的参数更改 #7003 (dask#7004) Eric Czech跳过失败的 s3 测试 (dask#7064) Martin Durant
恢复
BlockwiseIO(dask#7048) Richard (Rick) Zamora添加一些交叉引用到
DataFrame.to_bag()和Series.to_bag()(dask#7049) Rob Malouf将
matmul重写为不带收缩/拼接的blockwise(dask#7000) Rafal Wojdyla在
da.shape中使用functools.cached_property(dask#7023) Illviljan在 series
non_empty中使用 meta 值 (dask#6976) Julia Signell恢复“临时锁定 sphinx 版本到 3.3.1 (dask#7002)” (dask#7014) Rafal Wojdyla
恢复
python-graphviz锁定版本 (dask#7037) Julia Signell意外提交的 print 语句 (dask#7038) Julia Signell
在
agg中传递dropna和observed(dask#6992) Julia Signell在使用 expand 的
.str.split后将 index 添加到meta(dask#7026) Ruben van de GeerCI: 测试 pyarrow 2.0 和 nightly (dask#7030) Joris Van den Bossche
临时锁定
python-graphviz版本在 CI 中 (dask#7031) James Bourbeau在
numpydoc中给章节加下划线 (dask#7013) Matthias Bussonnier添加自定义优化时保留正常优化 (dask#7016) Matthew Rocklin
临时锁定 sphinx 版本到 3.3.1 (dask#7002) Rafal Wojdyla
文档:杂项格式化 (dask#6998) Matthias Bussonnier
在
from_array中添加inline_array选项 (dask#6773) Tom Augspurger恢复“blockwise 数组创建例程的首次尝试 (dask#6931)” (dask#6995) James Bourbeau
在
set_index中设置npartitions(dask#6978) Julia Signell上游
config序列化和继承 (dask#6987) Jacob Tomlinson在
test_minimum_time中提升最小时间 (dask#6988) Martin Durant修复
read_parquet的 pandasdtype推断 (dask#6985) Richard (Rick) Zamora避免在
set_index中使用sorted=True时的数据丢失 (dask#6980) Richard (Rick) Zamoraread_parquet中的错误修复,用于处理使用index=False的无名索引 (dask#6969) Richard (Rick) Zamora比较元数据时使用
__class__(dask#6981) Mads R. B. Kristensen比较字符串版本不总是有效 (dask#6979) Rafal Wojdyla
简化
has_parallel_type()(dask#6927) Mads R. B. Kristensen处理
BlockwiseIO中的注解解包 (dask#6934) Simon Perkins避免在
test_sql.py中使用废弃的yield_fixture(dask#6968) Richard (Rick) Zamora移除
BlockwiseIO中的不良图逻辑 (dask#6933) Richard (Rick) Zamora如果变量是
None则获取配置项 (dask#6862) Jacob Tomlinson更新
from_pandas的文档字符串 (dask#6957) Richard (Rick) Zamora防止
fuse_roots覆盖注解 (dask#6955) Simon Perkins
2020.12.0¶
发布于 2020 年 12 月 10 日
重点¶
版本控制方案切换到 CalVer。
引入新的
HighLevelGraphAPI,以支持将任务图的高层表示发送到分布式调度器。引入新的
HighLevelGraph层对象,包括BasicLayer,Blockwise,BlockwiseIO,ShuffleLayer, 等等。添加了对使用
dask.annotations上下文管理器应用自定义Layer级别注解(如priority,retries等)的支持。将 pandas 的最低支持版本更新到 0.25.0,NumPy 更新到 1.15.1。
支持将
pyarrow.datasetAPI 应用到read_parquet。修复了 Dask Array SVD 的多个问题。
所有更改¶
observed关键字参数可选 (dask#6952) Julia Signell最低支持 pandas 0.25.0 numpy 1.15.1 (dask#6895) Julia Signell
使分类变量的顺序明确 (dask#6949) Julia Signell
改进
read_parquet的 “pyarrow-dataset” 统计性能 (dask#6918) Richard (Rick) Zamora向
groupby添加observed关键字 (dask#6854) Julia Signell确保
include_path_column在每个文件有多个分区时工作 (dask#6911) Julia Signell修复:当深度为无符号位类型时,
array.overlap和array.map_overlap的块大小错误 (dask#6909) GFleishman从
sample返回一个Bag(dask#6941) Shang Wang并行启用 parquet 元数据收集 (dask#6921) Richard (Rick) Zamora
如果
_file为None则避免在progressbar中使用它 (dask#6938) Mark Harfouche将 Zarr 添加到上游 CI 构建 (dask#6932) James Bourbeau
引入
BlockwiseIO层 (dask#6878) Richard (Rick) Zamora将
Layer注解传输到调度器 (dask#6889) Simon Perkins允许
pyarrow >2.0.0(dask#6772) Richard (Rick) Zamora支持
read_parquet的pyarrow.datasetAPI (dask#6534) Richard (Rick) Zamora当缩减因子不能整除形状时,为
da.coarsen添加更具描述性的错误消息 (dask#6908) Davis Bennett仅在
dask/dask上运行定时 CI,而非 fork (dask#6905) Jacob Tomlinson向
ShuffleLayers添加annotations(dask#6913) Matthew Rocklin临时预期
test_from_s3失败 (dask#6915) James Bourbeau添加了 dataframe
skew方法 (dask#6881) Jan Borchmann修复数组
meta中的dtype(dask#6893) Julia Signellhelm install ...中缺少name参数 (dask#6903) Ruben van de Geer修复:读取带过滤器的项时出现异常 (dask#6901) Martin Durant
添加对
cupyx稀疏矩阵的支持到dask.array.dot(dask#6846) Akira Naruse稍微提高 array mindeps 以使测试通过 [test-mindeps] (dask#6894) Julia Signell
更新/移除 mindeps 中的 pandas 和 numpy (dask#6888) Julia Signell
修复使用
clear_known_categories时的ArrowEngine错误 (dask#6887) Richard (Rick) Zamora修复关于任务调度器的文档 (dask#6879) Zhengnan Zhao
添加人类可读的相对时间格式化工具 (dask#6883) Jacob Tomlinson
6864
set_index问题的可能修复 (dask#6866) Richard (Rick) ZamoraBasicLayer:移除依赖参数 (dask#6859) Mads R. B. KristensenBlockwise的序列化 (dask#6848) Mads R. B. Kristensen解决
columns=[]错误 (dask#6871) Richard (Rick) Zamora避免重复的 parquet schema 通信 (dask#6841) Richard (Rick) Zamora
为现有 parquet 数据集添加
create_metadata_file工具 (dask#6851) Richard (Rick) Zamora改进具有共同终点的工作负载的排序 (dask#6779) Tom Augspurger
将工具函数转换为字符串 (dask#6852) Mads R. B. Kristensen
向
to_parquet添加关键字overwrite=True,以便在覆盖 pyarrowDataset时移除悬空文件。 (dask#6825) Greg Hayes移除
map_tasks()和map_basic_layers()(dask#6853) Mads R. B. Kristensen向
svd_compressed引入 QR 迭代 (dask#6813) RogerMoens__dask_distributed_pack__()现在接受client参数 (dask#6850) Mads R. B. Kristensen在
set_index中使用map_partitions代替delayed(dask#6837) Mads R. B. Kristensen提高 GHA
setup-miniconda版本 (dask#6847) Jacob Tomlinson设置排序索引时移除 NaN 值 (dask#6829) Rockwell Weiner
修复 SVD 中 u 的转置 (dask#6799) RogerMoens
迁移到 GitHub Actions (dask#6794) Jacob Tomlinson
修复 sphinx
currentmodule用法 (dask#6839) James Bourbeau修复最小依赖 CI 构建 (dask#6838) James Bourbeau
在
Blockwise剪枝期间避免图具象化 (dask#6815) Richard (Rick) Zamora修复了拼写错误 (dask#6834) Devanshu Desai
在
collections_to_dsk中使用HighLevelGraph.merge(dask#6836) Mads R. B. Kristensen在 svd
compression_matrix#2849 中遵守dtype(dask#6802) RogerMoens向任务名称添加块大小 (dask#6818) Julia Signell
检查全 NaN 分区 (dask#6821) Rockwell Weiner
将“机构”SQL 文档部分更改为指向主要 SQL 文档 (dask#6823) Martin Durant
修复:
DataFrame.join不接受 Series 作为 other 参数 (dask#6809) David Katz从
to_parquet移除to_delayed操作 (dask#6801) Richard (Rick) ZamoraLayer 注解 docstring 改进 (dask#6806) Simon Perkins
Avro 读取器 (dask#6780) Martin Durant
如果最小块大小小于深度,则对数组进行 rechunk (dask#6708) Julia Signell
添加 Layer 注解 (dask#6767) Simon Perkins
向
Blockwise层添加可选的 IO 子图 (dask#6715) Richard (Rick) Zamora添加分布式的高级图 pack/unpack (dask#6786) Mads R. B. Kristensen
添加 DataFrame API 中缺失的方法 (dask#6789) Stephannie Jimenez Gacha
添加关于环境管理的文档 (dask#6778) Martin Durant
HLG:
get_all_external_keys()(dask#6774) Mads R. B. Kristensen在
chunksize=1的 reshape 中避免 rechunk (dask#6748) Tom Augspurger尝试使分类变量在 join 中工作 (dask#6205) Julia Signell
修复
array-slice.rst中的一些小错误和尾随空格 (dask#6771) Magnus Nord修复 parquet 元数据写入空 dataframe 分区时的 bug (pyarrow) (dask#6741) Callum Noble
在
map_blocks和map_overlap中记录meta关键字参数。 (dask#6763) Peter Andreas Entschev开始试验针对
cumsum和cumprod的并行前缀扫描 (dask#6675) Erik WelchShuffle 层的高效序列化 (dask#6760) James Bourbeau
配置 array 优化以跳过融合并返回 HLG (dask#6751) Mads R. B. Kristensen
在 CI 中临时使用
pyarrow<2(dask#6759) James Bourbeau修复
min/max归约的 meta (dask#6736) Peter Andreas Entschev向
da.linalg.lstsq添加 2D 可能性 - 模仿 numpy (dask#6749) Pascal BourgaultCI: 修复导致 pivot 测试偶尔失败的 bug (dask#6752) Tom Augspurger
层的序列化 (dask#6693) Mads R. B. Kristensen
移除了可变默认参数 (dask#6747) Mads R. B. Kristensen
调整 parquet
ArrowEngine以便更容易派生用于写入的子类 (dask#6505) Joris Van den Bossche添加
ShuffleStageHLG 层 (dask#6650) Richard (Rick) Zamora在
meta_from_array中处理 literal (dask#6731) Peter Andreas Entschev即使 chunk 相同也进行均衡 rechunk (dask#6735) Chris Roat
修复
DataFrame.set_index的 docstring (dask#6739) Gil Forsyth确保
HighLevelGraph层总是包含Layer实例 (dask#6716) James Bourbeau在
HighLevelGraph层上进行 Map 操作 (dask#6689) Mads R. B. Kristensen更新 overlap
*_like函数调用和 CuPy 测试 (dask#6728) Peter Andreas Entschev修复带
__array_function__的svd问题 (dask#6727) Peter Andreas Entschev为文档添加 doctest 扩展 (dask#6397) Jim Circadian
使用 @pentschev 的建议对 #5628 进行小幅修复 (dask#6724) John A Kirkham
在 meta 类型更改时更改 Dask 数组的类型 (dask#5628) Matthew Rocklin
HLG: 获取单个 key 的
get_dependencies()(dask#6699) Mads R. B. Kristensen撤销“撤销‘在所有集合中都使用 HighLevelGraph 层 (dask#6510)’ (dask#6697)” (dask#6707) Tom Augspurger
允许
*_like数组创建函数尊重输入数组类型 (dask#6680) Genevieve Buckley更新
dask-sphinx-theme版本 (dask#6700) Gil Forsyth
2.30.0 / 2020-10-06¶
Array¶
允许
rechunk平均分成 N 个块 (dask#6420) Scott Sievert
2.29.0 / 2020-10-02¶
Array¶
_repr_html_: 颜色侧面更深,而不是绘制所有线 (dask#6683) Julia Signell移除
nanstd和nanvar的警告 (dask#6667) Thomas J. Fan从原始数组获取输出形状 -
map_overlap(dask#6682) Julia Signell在索引中将
np.searchsorted替换为bisect(dask#6669) Joachim B Haga
Bag¶
确保子进程对于 bag
groupby有一致的哈希值 (dask#6660) Itamar Turner-Trauring
Core¶
撤销“在所有集合中都使用
HighLevelGraph层 (dask#6510)” (dask#6697) Tom Augspurger使用
pandas.testing(dask#6687) John A Kirkham改进测试中的 128 位浮点跳过 (dask#6676) Elliott Sales de Andrade
DataFrame¶
允许使用布尔 dataframe 设置 dataframe 项 (dask#6608) Julia Signell
2.28.0 / 2020-09-25¶
Array¶
部分撤销了导致大更改的
Array索引更改。这将恢复 Dask 2.25.0 及更早版本的行为,并在生成大块时发出警告。提供了配置选项以避免创建大块,请参阅 Efficiency。 (dask#6665) Tom Augspurger向
to_dask_array添加meta(dask#6651) Kyle Nicholson修复 dask#6631 和 dask#6611 (dask#6632) Rafal Wojdyla
在数组归约中推断对象类型 (dask#6629) Daniel Saxton
向
svd_flip添加v_based标志 (dask#6658) Eric Czech修复不稳定的数组
mean(dask#6656) Sam Grayson
Core¶
从
SubgraphCallable.__eq__移除了dsk相等性检查 (dask#6666) Mads R. B. Kristensen在所有集合中都使用
HighLevelGraph层 (dask#6510) Mads R. B. Kristensen为缓存目的向
SubgraphCallable添加哈希双下划线方法 (dask#6424) Andrew Fulton默认情况下停止写入注释掉的配置文件 (dask#6647) Matthew Rocklin
DataFrame¶
通过
aggAPI 添加对 collect list 聚合的支持 (dask#6655) Madhur Tandon稍好一些的错误消息 (dask#6657) Julia Signell
2.27.0 / 2020-09-18¶
Array¶
在
svd中保留dtype(dask#6643) Eric Czech
Core¶
store(): 创建单个 HLG 层 (dask#6601) Mads R. B. Kristensen添加 pre-commit CI 构建 (dask#6645) James Bourbeau
将
.pre-commit-config更新到最新的 black。 (dask#6641) Julia Signell更新 super 用法以移除 Python 2 兼容性 (dask#6630) Poruri Sai Rahul
移除 u 字符串前缀 (dask#6633) Poruri Sai Rahul
DataFrame¶
改进
to_sql的错误消息 (dask#6638) Julia Signell使用空列表作为 categories (dask#6626) Julia Signell
Documentation¶
为 array api 文档添加
autofunction以支持更多 ufuncs (dask#6644) James Bourbeau向
dask.array文档添加一些缺失的 ufuncs (dask#6642) Ralf Gommers添加
HelmCluster文档 (dask#6290) Jacob Tomlinson
2.26.0 / 2020-09-11¶
Array¶
单块 svd 的后端感知 dtype 推断 (dask#6623) Eric Czech
使
array.reductiondocstring 与 dtype 匹配 (dask#6624) Martin Durant使用行和列为
svd_compressed设置压缩级别的下限 (dask#6622) Eric Czech改进 SVD 一致性和小数组处理 (dask#6616) Eric Czech
添加
svd_flip#6599 (dask#6613) Eric Czech处理包含 dask 数组的序列 (dask#6595) Gabe Joseph
避免使用列表从
getitem生成大块 (dask#6514) Tom Augspurger在
from_array中急切地切片 numpy 数组 (dask#6605) Deepak Cherian恢复 pickle dask 数组的能力 (dask#6594) Noah D. Brenowitz
添加对短胖数组的 SVD 支持 (dask#6591) Eric Czech
添加简单的 chunk 类型注册表并酌情推迟到向上转型 (dask#6393) Jon Thielen
默认对齐 coarsen chunks (dask#6580) Deepak Cherian
修复未知维度上的 reshape 和其他测试修复 (dask#6578) Ryan Williams
Core¶
添加
HighLevelGraph依赖项的验证和修复 (dask#6588) Mads R. B. Kristensen修复 linting 问题 (dask#6598) Tom Augspurger
跳过
bokeh版本 2.0.0 (dask#6572) John A Kirkham
DataFrame¶
处理
Series.sum/prod中的min_count(dask#6618) Daniel Saxton在分位数计算期间始终计算 0 和 1 分位数 (dask#6564) Erik Welch
修复读取空 csv 文件时的错误路径 (dask#6573) Abdulelah Bin Mahfoodh
Documentation¶
文档:排查 dashboard 404 问题 (dask#6215) Kilian Lieret
修复
extraConfig示例 (dask#6625) Tom Augspurger更新支持的 Python 版本 (dask#6609) Julia Signell
记录 dask/daskhub helm chart (dask#6560) Tom Augspurger
2.25.0 / 2020-08-28¶
Core¶
在
subs()中比较 key 哈希值 (dask#6559) Mads R. B. Kristensen使用最新的
black发布版本重新运行 (dask#6568) James Bourbeau许可证更新 (dask#6554) Tom Augspurger
Documentation¶
从文档页面名称中移除版本号 (dask#6558) James Bourbeau
更新
kubernetes-helm.rst(dask#6523) David Sheldon停止 2020 年调查 (dask#6547) Tom Augspurger
2.24.0 / 2020-08-22¶
Array¶
修复测试中设置随机种子的问题。 (dask#6518) Elliott Sales de Andrade
支持 apply gufunc 中的 meta (dask#6521) joshreback
将 cupy.sparse 替换为 cupyx.scipy.sparse (dask#6530) John A Kirkham
Dataframe¶
提高 rolling tests 的容忍度 (dask#6502) Julia Signell
实现 DataFrame.__len__ (dask#6515) Tom Augspurger
在 to_parquet 中推断 arrow schema (针对 ArrowEngine`) (dask#6490) Richard (Rick) Zamora
修复没有 pyarrow 时的 parquet 测试 (dask#6524) Martin Durant
移除 ArrowEngine 中有问题的
filter参数 (dask#6527) Richard (Rick) Zamora默认情况下避免在 ArrowEngine 中进行 schema 验证 (dask#6536) Richard (Rick) Zamora
Core¶
在 make_blockwise_graph 中使用 unpack_collections (dask#6517) Thomas J. Fan
将 key_split() 从 optimization.py 移动到 utils.py (dask#6529) Mads R. B. Kristensen
使测试在 moto server 上运行 (dask#6528) Martin Durant
2.23.0 / 2020-08-14¶
Array¶
通过广播减少
np.zeros,ones和full的数组大小 (dask#6491) Matthias Bussonnier在
map_overlap中为trim添加缺失的meta=参数 (dask#6494) Peter Andreas Entschev
Bag¶
Bag repartition 分区大小 (dask#6371) joshreback
Core¶
Scalar.__dask_layers__()返回self._name而不是self.key(dask#6507) Mads R. B. Kristensen在
fuse_root优化中正确更新依赖项 (dask#6508) Mads R. B. Kristensen
DataFrame¶
向 dataframe 添加
items(dask#6503) Thomas J. Fan在
write_table调用中包含压缩设置 (dask#6499) Julia Signell修复
nonempty_series中的警告 (dask#6485) Tom Augspurger根据第一个参数的类型智能确定分区 (dask#6479) Matthew Rocklin
修复 pyarrow
mkdirs(dask#6475) Julia Signell修复
to_parquet中的重复 parquet 输出 (dask#6451) michaelnarodovitch
Documentation¶
修复文档
da.histogram(dask#6439) Roberto Panai修复 SQL 文档中的一些拼写错误 (dask#6489) Mike McCarty
SQLing 文档 (dask#6453) Martin Durant
2.22.0 / 2020-07-31¶
Array¶
与 NumPy dtype 弃用兼容 (dask#6430) Tom Augspurger
Core¶
为某些类似
bytes的对象实现sizeof(dask#6457) John A Kirkham新
fsspec的 HTTP 错误 (dask#6446) Martin Durant当引发
RecursionError时,从tokenize函数返回 uuid (dask#6437) Julia Signell安装 upstream-dev 包的依赖项 (dask#6431) Tom Augspurger
在
setup.cfg中使用更新的链接 (dask#6426) Zhengnan Zhao
DataFrame¶
如果列名是字符串,则在周围添加单引号 (dask#6471) Gil Forsyth
重构
ArrowEngine以提高read_parquet性能 (dask#6346) Richard (Rick) Zamora添加
tolistdispatch (dask#6444) GALI PREM SAGAR与 pandas 1.1.0rc0 兼容 (dask#6429) Tom Augspurger
多值 pivot table (dask#6428) joshreback
在
to_csvdocstring 中重复参数定义 (dask#6411) Jun Han (Johnson) Ooi
Documentation¶
向文档添加实用工具,用于将 YAML 配置转换为环境变量并转换回来 (dask#6472) Jacob Tomlinson
修复参数服务器渲染 (dask#6466) Scott Sievert
修复损坏的链接 (dask#6403) Jim Circadian
完成文档中的参数服务器实现 (dask#6449) Scott Sievert
修复拼写错误 (dask#6436) Jack Xiaosong Xu
2.21.0 / 2020-07-17¶
Array¶
纠正
array.routines.gradient()中的错误消息 (dask#6417) johnomotani修复带有某些
dimension=1的数组的 blockwise concatenate (dask#6342) Matthias Bussonnier
Bag¶
修复
bag.take示例 (dask#6418) Roberto Panai
Core¶
优化阶段中的分组值应仅为 graph 和 keys -- 而非 optimization + keys (dask#6409) Benjamin Zaitlen
使用提供的
kwargs调用自定义优化一次 (dask#6382) Clark Zinzow包含
pickle5用于在 Python 3.7 上测试 (dask#6379) John A Kirkham
DataFrame¶
纠正错误消息中的拼写错误 (dask#6422) Tom McTiernan
使用
pytest.warns检查UserWarning(dask#6378) Richard (Rick) Zamora从字符串解析
bytes_per_chunk keyword(dask#6370) Matthew Rocklin
Documentation¶
Numpydoc 格式化 (dask#6421) Matthias Bussonnier
在 1.1 发布后取消固定
numpydoc(dask#6407) Gil ForsythNumpydoc 格式化 (dask#6402) Matthias Bussonnier
更新
visualizedocstrings (dask#6383) Zhengnan Zhao
2.20.0 / 2020-07-02¶
Array¶
注册 numpy 零步长数组的
sizeof(dask#6343) Matthias Bussonnier在
concatenate中使用concatenate_lookup(dask#6339) John A Kirkham修复具有某些零长度维度的数组的 rechunking 问题 (dask#6335) Matthias Bussonnier
DataFrame¶
将
iloc`调用分派给getitem(dask#6355) Gil Forsyth在 fastparquet 引擎中处理未命名的 pandas
RangeIndex(dask#6350) Richard (Rick) Zamora使用 pyarrow 写入分区 parquet 数据集时保留索引 (dask#6282) Richard (Rick) Zamora
为 pandas 的
group_split_dispatch使用ignore_index(dask#6251) Richard (Rick) Zamora
2.19.0 / 2020-06-19¶
Array¶
将块大小转换为 python int
dtype(dask#6326) Gil Forsyth向
*_like()数组创建函数添加shape=None(dask#6064) Anderson Banihirwe
Core¶
更新 fsspec 中协议差异的预期错误消息 (dask#6331) Gil Forsyth
修复
parse_bytes中小于 1 的浮点数问题 (dask#6311) Gil Forsyth修复整个代码库中的异常原因链 (dask#6308) Ram Rachum
修复重复的测试 (dask#6303) James Lamb
移除未使用的测试函数 (dask#6304) James Lamb
DataFrame¶
添加高级 CSV 子图 (dask#6262) Gil Forsyth
修复合并仅包含索引的 1 分区 dataframe 时的
ValueError(dask#6309) Krishan Bhasin使
index.map清除 divisions。 (dask#6285) Julia Signell
Documentation¶
添加 2020 年调查链接 (dask#6328) Tom Augspurger
更新
bag.rst(dask#6317) Ben Shaver
2.18.1 / 2020-06-09¶
Array¶
不要尝试在
full上设置名称 (dask#6299) Julia SignellHistogram: 支持范围/bin 的延迟值 (另一种方式) (dask#6252) Gabe Joseph
Core¶
修复
utils.py中的异常原因链 (dask#6302) Ram Rachum提高
HighLevelGraph构建性能 (dask#6293) Julia Signell
Documentation¶
readthedocs 现在构建未发布功能的 docstring (dask#6295) Antonio Ercole De Luca
添加
asyncsshintersphinx 映射 (dask#6298) Jacob Tomlinson
2.18.0 / 2020-06-05¶
Array¶
如果切片索引与原始数组形状相同,则将其转换为 dask 数组 (dask#6273) Julia Signell
修复
stack错误消息 (dask#6268) Stephanie Gott支持在
map_overlap中使用多个数组 (dask#6165) Eric Czech填充重采样(resample)的分区(divisions),以便计算边缘值 (dask#6255) Julia Signell
Bag¶
从 dask bag 中随机采样 k 个元素 #4799 (dask#6239) Antonio Ercole De Luca
DataFrame¶
在
sort_values中添加dropna、sort和ascending参数 (dask#5880) Julia Signell泛化
from_dask_array(dask#6263) GALI PREM SAGAR为
SeriesGroupby.nunique添加派生文档字符串 (dask#6284) Julia Signell移除带规则(rule)的重采样(resample)中的
NotImplementedError(dask#6274) Abdulelah Bin Mahfoodh添加
dd.to_sql(dask#6038) Ryan Williams
2.17.2 / 2020-05-28¶
核心¶
重新添加
completeextra (dask#6257) Jim Crist-Harif
DataFrame¶
如果
resample无法给出正确结果,则引发错误 (dask#6244) Julia Signell
2.17.1 / 2020-05-28¶
Array¶
空数组重新分块 (rechunk) (dask#6233) Andrew Fulton
核心¶
使
pyyaml成为必需依赖 (dask#6250) Jim Crist-Harif修复
ImportError提示的安装命令 (dask#6238) Gaurav Sheni移除 issue 模板 (dask#6249) Jacob Tomlinson
DataFrame¶
将
ignore_index从DataFrame.shuffle传递给dd_shuffle(dask#6247) Richard (Rick) Zamora处理丢失的 HDF 键 (dask#6204) Martin Durant
泛化
describe&quantileapi (dask#5137) GALI PREM SAGAR
2.17.0 / 2020-05-26¶
Array¶
Bag¶
Bags 的随机选择 (Random Choice) (dask#6208) Antonio Ercole De Luca
核心¶
为
delayed.visualise()发出警告 (dask#6216) Amol Umbarkar确保其他 pickle 参数有效 (dask#6229) John A Kirkham
彻底修改
fuse()配置 (dask#6198) crusaderky更新
dask.order.order以同时使用 FIFO 和 LIFO 考虑“下一个”节点 (dask#5872) Erik Welch
DataFrame¶
为更多 agg 方法使用 0 作为
fill_value(dask#6245) Julia Signell泛化
rearrange_by_column_tasks并添加DataFrame.shuffle(dask#6066) Richard (Rick) Zamora对于较新版本的 numba 和较旧版本的 pandas,将
test_rolling_numba_engine标记为 xfail (dask#6236) James Bourbeau泛化
fix_overlap(dask#6240) GALI PREM SAGAR设置具有重叠分区的预排序索引时避免 shuffle (dask#6226) Krishan Bhasin
调整 Parquet 引擎类以便更轻松地进行子类化 (dask#6211) Marius van Niekerk
修复
dd.merge_asof与left_on='col'&right_index=True一起使用时的问题 (dask#6192) noreentry将
AUTO_BLOCKSIZE移出read_csv签名 (dask#6214) Jim Crist-Harif使用可调用对象进行
.loc索引 (dask#6185) Endre Mark Borza对于 groupby std agg,在
_compute_sum_of_squares中避免使用 apply (dask#6186) Richard (Rick) Zamora对
test_parquet进行小修正 (dask#6190) Brian Larsen遵守传递的 pat 进行 delimeter join 并修复错误消息 (dask#6194) GALI PREM SAGAR
如果没有可用的 parquet 库,则跳过
test_to_parquet_with_get(dask#6188) Scott Sanderson
文档¶
添加了
distributed.Event类的文档 (dask#6231) Nils Braun
2.16.0 / 2020-05-08¶
Array¶
修复数组通用 reduce 名称 (dask#6176) Nick Evans
在
unravel_index中将dim替换为shape(dask#6155) Julia SignellMoment: 处理所有元素都被掩码的情况 (dask#5339) Gabe Joseph
核心¶
删除 dask 代码库中多余的字符串连接 (dask#6137) GALI PREM SAGAR
上游兼容性 (Upstream compat) (dask#6159) Tom Augspurger
确保 dict 和序列的
sizeof返回整数 (dask#6179) James Bourbeau通过随机采样估算 python 集合大小 (dask#6154) Florian Jetter
更新测试上游 (dask#6146) Tom Augspurger
跳过 mindeps 构建的测试 (dask#6144) Tom Augspurger
将默认的多进程上下文切换为“spawn” (dask#4003) Itamar Turner-Trauring
更新清单以包含 dask-schema (dask#6140) Benjamin Zaitlen
DataFrame¶
在基于 pyarrow 的
read_parquet中增强不一致模式的处理 (dask#6160) Richard (Rick) Zamora将 compute
kwargs添加到将数据写入磁盘的方法中 (dask#6056) Krishan Bhasin修复
unique从后端返回类似索引结果的问题 (dask#6153) GALI PREM SAGAR修复
map_partitions与集合一起使用时的内部错误 (dask#6103) Tom Augspurger
文档¶
向索引 TOC 添加计算阶段 (dask#6157) Benjamin Zaitlen
删除调度脚本中未使用的导入 (dask#6138) James Lamb
修复缩进 (dask#6147) Martin Durant
添加 Tom 的日志配置示例 (dask#6143) Martin Durant
2.15.0 / 2020-04-24¶
Array¶
更新
dask.array.from_array,在传入 Dask 集合时发出警告 (dask#6122) James Bourbeau在
da.repeat中添加对repeats=0的支持 (dask#6080) James Bourbeau
核心¶
修复 schema 的 yaml 布局 (dask#6132) Benjamin Zaitlen
配置参考 (Configuration Reference) (dask#6069) Benjamin Zaitlen
添加配置选项以关闭任务融合 (task fusion) (dask#6087) Matthew Rocklin
在 windows 上跳过 pyarrow (dask#6094) Tom Augspurger
设置融合键最大长度的限制 (dask#6057) Lucas Rademaker
添加针对 #6062 的测试 (dask#6072) Martin Durant
将 checkout action 升级到 v2 (dask#6065) James Bourbeau
DataFrame¶
泛化分类调用以支持 cudf
Categorical(dask#6113) GALI PREM SAGAR避免在每个 worker 上读取
_metadata(dask#6017) Richard (Rick) Zamora在
apply_concat_apply中使用group_split_dispatch和ignore_index(dask#6119) Richard (Rick) Zamora处理 pyarrow 的新 (dtype) pandas metadata (dask#6090) Richard (Rick) Zamora
如果 pyarrow 未安装,则跳过
test_partition_on_cats_pyarrow(dask#6112) James Bourbeau更新 DataFrame len 以处理同名列 (dask#6111) James Bourbeau
ArrowEnginebug 修复和测试覆盖 (dask#6047) Richard (Rick) Zamora添加了 mode (dask#5958) Adam Lewis
文档¶
扩展 preload 文档 (dask#6077) Matthew Rocklin
修复 DataFrame
map_partitions()文档字符串中的小 typo (dask#6115) Eugene Huang修复 typo:“double”应为 times,而不是 plus (dask#6091) David Chudzicki
修复
array.random.*文档的第一行 (dask#6063) Martin Durant在 distributed 中添加
Semaphore的部分文档 (dask#6053) Florian Jetter
2.14.0 / 2020-04-03¶
Array¶
添加
np.iscomplexobj实现 (dask#6045) Tom Augspurger
核心¶
更新
test_rearrange_disk_cleanup_with_exception,使其在未安装 cloudpickle 时也能通过 (dask#6052) James Bourbeau修复不稳定的
test-rearrange(dask#5977) Tom Augspurger
DataFrame¶
在
stack_partitions中使用_meta_nonempty进行 dtype 转换 (dask#6061) mlondschien修复 parquet
ArrowEngine中_metadata创建和过滤的 bug (dask#6023) Richard (Rick) Zamora
文档¶
DOC: 添加命名注意事项 (name caveats) (dask#6040) Tom Augspurger
2.13.0 / 2020-03-25¶
Array¶
支持
da.random中的dtype和其他关键字参数 (dask#6030) Matthew Rocklin注册支持
cupy稀疏hstack/vstack(dask#5735) Corey J. Nolet在
dask.array中强制将self.name转换为str(dask#6002) Chuanzhu Xu
Bag¶
在
bag.optimize中默认将rename_fused_keys设置为None(dask#6000) Lucas Rademaker
核心¶
更严格的 pandas
xfail(dask#6024) Tom Augspurger修复 CI 失败 (dask#6013) James Bourbeau
更新
toolz到 0.8.2 并使用tlz(dask#5997) Ryan Grout将 Windows CI 构建移至 GitHub Actions (dask#5862) James Bourbeau
DataFrame¶
修复
dd.concat中的dtype处理问题 (dask#6006) mlondschien处理 cudf 的 leftsemi 和 leftanti join (dask#6025) Richard J Zamora
删除
dd.from_pandas中未使用的npartitions变量 (dask#6019) Daniel Saxton
文档¶
修复 scheduler-overview 文档中的缩进问题 (dask#6022) Matthew Rocklin
更新 optimize 文档中的任务图 (dask#5928) Julia Signell
可选地去除 visualize 中的中间框,并添加更多标签 (dask#5976) Julia Signell
2.12.0 / 2020-03-06¶
Array¶
改进 numpy 临时变量的重用 (dask#5933) Bruce Merry
使带有
block_info的map_blocks生成Blockwise(dask#5896) Bruce Merry优化
make_blockwise_graph(dask#5940) Bruce Merry修复
da.tensordot中的轴顺序 (dask#5975) Gil Forsyth为
array.pad添加 empty mode (dask#5931) Thomas J. Fan
核心¶
移除
dask.utils中对toolz.memoize的依赖 (dask#5978) Ryan Grout关闭泄漏子进程的 pool (dask#5979) Tom Augspurger
锁定
numpydoc版本到0.8.0(修复 double autoescape) (dask#5961) Gil Forsyth注册
range对象的确定性 tokenization (dask#5947) James Bourbeau在 CI 中解除
msgpack的版本锁定 (dask#5930) JAmes Bourbeau确保 dot 结果存放在唯一的文件中 (dask#5937) Elliott Sales de Andrade
将剩余的可选依赖项添加到 Travis 3.8 CI 构建环境 (dask#5920) James Bourbeau
DataFrame¶
跳过某些键的 parquet
getitem优化 (dask#5917) Tom Augspurger为
rearrange_by_column代码路径添加ignore_index参数 (dask#5973) Richard J Zamora添加 DataFrame 和 Series 的
memory_usage_per_partition方法 (dask#5971) James Bourbeau在使用 Pandas 0.24.2 时将 test_describe 标记为
xfail(dask#5948) James Bourbeau实现
dask.dataframe.to_numeric(dask#5929) Julia Signell当列顺序不同时添加新的错误消息内容 (dask#5927) Julia Signell
尽可能为 assign 操作使用浅拷贝 (dask#5740) Richard J Zamora
文档¶
在
dask.array.triu文档中将 above 改为 below (dask#5984) Henrik Andersson数组切片 (Array slicing): 修复
slice_with_int_dask_array错误消息中的 typo (dask#5981) Gabe Joseph文档字符串的语法和格式更新 (dask#5963) James Lamb
更新 DataFrame extension 文档的标题 (dask#5954) James Bourbeau
修复文档中的 typo (dask#5962) James Lamb
在
_bind_*方法上添加原始类或模块作为kwarg(dask#5946) Julia Signell更新 python 3 的 optimization 文档 (dask#5926) Julia Signell
2.11.0 / 2020-02-19¶
Array¶
缓存
Array.shape的结果 (dask#5916) Bruce Merry提高
rechunk的estimate_graph_size精度 (dask#5907) Bruce Merry跳过不改变分块的 rechunk 步骤 (dask#5909) Bruce Merry
支持
coarsen中的dtype和其他kwargs(dask#5903) Matthew Rocklin将
map_blocks的 chunk 覆盖推送进 blockwise (dask#5895) Bruce Merry对于单例避免使用
rewrite_blockwise(dask#5890) Bruce Merry优化
slices_from_chunks(dask#5891) Bruce Merry当 chunks 具有正确维度时,在
block()中避免不必要的__getitem__(dask#5884) Thomas Robitaille
Bag¶
为
dask.bag.read_text添加include_path选项 (dask#5836) Yifan Gu修复延迟执行 bagged NumPy 数组时的
ValueError(dask#5828) Surya Avala
核心¶
CI: 锁定
msgpack版本 (dask#5923) Tom Augspurger将
test_inner重命名为test_outer(dask#5922) Shiva Raisinghaniquote也应该引用 dicts (dask#5905) Bruce Merry注册 literal 的 normalizer (dask#5898) Bruce Merry
改进非 HLG 的层名称合成 (dask#5888) Bruce Merry
将 flake8 pre-commit-hook 替换为上游版本 (dask#5892) Julia Signell
以模块方式调用 pip 以避免警告 (dask#5861) Cyril Shcherbin
退出时关闭
ThreadPool(dask#5852) Tom Augspurger移除 tokenization 代码中对
dask.dataframe的导入 (dask#5855) James Bourbeau
DataFrame¶
要求
pandas>=0.23(dask#5883) Tom Augspurger移除 dataframe aggregation 中的 lambda (dask#5901) Matthew Rocklin
修复
dataframe/__init__.py中的异常链问题 (dask#5882) Ram Rachum添加对空 dataframes 上 reductions 的支持 (dask#5804) Shiva Raisinghani
为 groupby 暴露
sort=参数 (dask#5801) Richard J Zamora使用
fastparquet.api.paths_to_cats的 parquet 读取加速功能 (dask#5821) Igor Gotlibovych
文档¶
弃用
doc_wraps(dask#5912) Tom Augspurger更新 HighLevelGraph 时代的 array 内部设计文档 (dask#5889) Bruce Merry
迁移 dashboard 连接文档 (dask#5877) Matthew Rocklin
从 distributed.dask.org 迁移 prometheus 文档 (dask#5876) Matthew Rocklin
删除末尾重复的 DO 块 (dask#5878) K.-Michael Aye
map_blocks参见部分 (see also) (dask#5874) Tom Augspurger更多派生自 (derived from) (dask#5871) Julia Signell
修复 typo (dask#5866) Yetunde Dada
修复
cloud.rst中的 typo (dask#5860) Andrew Thomas添加指向行为准则和多样性声明的注释 (dask#5844) Matthew Rocklin
2.10.1 / 2020-01-30¶
修复 Pandas 1.0 版本比较问题 (dask#5851) Tom Augspurger
修复 distributed diagnostics 文档中的 typo (dask#5841) Gerrit Holl
2.10.0 / 2020-01-28¶
支持 pandas 1.0 新的
BooleanDtype和StringDtype(dask#5815) Tom Augspurger兼容 pandas 1.0 的 API 破坏性更改和弃用项 (dask#5792) Tom Augspurger
修复某些扩展数组支持的 pandas 对象的非确定性 tokenization 问题 (dask#5813) Tom Augspurger
修复 collections 中 dataclass 类对象的处理问题 (dask#5812) Matteo De Wint
将初始 Zarr 数据集的创建延迟到计算发生时 (dask#5797) Chris Roat
在基于
pyarrow引擎的情况下,更多地使用 parquet 数据集统计信息 (dask#5799) Richard J Zamora修复
groupby.std()在某些键为大整数时引发的异常问题 (dask#5737) H. Thomson Comer
2.9.2 / 2020-01-16¶
Array¶
在
broadcast_arrays中统一 chunks (dask#5765) Matthew Rocklin
核心¶
将 CSV encoding 测试标记为
xfail(dask#5791) Tom Augspurger更新 order 以处理空的 dask graph (dask#5789) James Bourbeau
重做
dask.order.order(dask#5646) Erik Welch
DataFrame¶
为使用
partd的磁盘 shuffle 添加透明压缩 (dask#5786) Christian Wesp修复空 dataframes 的
repr(dask#5781) Shiva RaisinghaniPandas 1.0.0RC0 兼容性 (dask#5784) Tom Augspurger
移除有 bug 的断言 (dask#5783) Tom Augspurger
Pandas 1.0 兼容性 (dask#5782) Tom Augspurger
修复基于 pyarrow 的
read_parquet在分区数据集上的 bug (dask#5777) Richard J ZamoraPandas 1.0 兼容性 (dask#5779) Tom Augspurger
修复带有分类索引的 groupby/mean 错误 (dask#5776) Richard J Zamora
支持在执行累积 aggregation 时使用空分区 (dask#5730) Matthew Rocklin
修复有序
Categorical在 set index 中的分区问题 (dask#5715) Tom Augspurger
文档¶
注意
normalize_token.register的额外使用案例 (dask#5766) Thomas A Caswell小 typos (dask#5771) Maarten Breddels
修复 Task Expectations 文档中的 typo (dask#5767) James Bourbeau
在 graph 页面添加 task expectations 的文档部分 (dask#5764) Devin Petersohn
2.9.1 / 2019-12-27¶
Array¶
使用 assert_eq util 方法重用代码 (dask#5736) Anderson Banihirwe
添加 dask.array.nanmedian (dask#5684) Deepak Cherian
核心¶
在 Python 3.8 上将 test_temporary_directory 标记为 xfail (dask#5734) James Bourbeau
添加对 Python 3.8 的支持 (dask#5603) James Bourbeau
DataFrame¶
将 dask dataframe scalar 转换为 boolean 时引发错误 (dask#5743) James Bourbeau
确保 dataframe groupby-variance 大于零 (dask#5728) Matthew Rocklin
修复 DataFrame.__iter__ (dask#5719) Tom Augspurger
支持 PyArrow 中 disjunctive normal form 的 Parquet 过滤器 (dask#5656) Matteo De Wint
在基于 ArrowEngine 的 read_parquet 中自动检测分类列 (dask#5690) Richard J Zamora
如果没有找到 engine,则跳过 parquet getitem 优化测试 (dask#5697) James Bourbeau
修复 parquet-getitem 的独立优化问题 (dask#5613) Tom Augspurger
文档¶
在多个地方链接到 examples.dask.org (dask#5733) Tom Augspurger
添加 performance report 示例中缺失的“ (dask#5724) James Bourbeau
解决几个文档构建警告 (dask#5685) James Bourbeau
添加关于 performance_report 的信息 (dask#5713) Benjamin Zaitlen
添加更多文档免责声明 (dask#5710) Julia Signell
更新 numpydoc 依赖项 (dask#5694) James Bourbeau
2.9.0 / 2019-12-06¶
Array¶
修复
da.std以与 NumPy 数组一起使用 (dask#5681) James Bourbeau
核心¶
注册 Numba 和 RMM 的
sizeof函数 (dask#5668) John A Kirkham更新会议时间 (dask#5682) Tom Augspurger
DataFrame¶
修改
dd.DataFrame.drop以使用浅拷贝 (dask#5675) Richard J Zamora修复
_get_md_row_groups中的 bug (dask#5673) Richard J Zamora查询数据库后关闭 sqlalchemy engine (dask#5629) Krishan Bhasin
允许
dd.map_partitions不强制使用 meta (dask#5660) Matthew Rocklin泛化
concat_unindexed_dataframes以支持 cudf-backend (dask#5659) Richard J Zamora添加 dataframe 重采样方法 (dask#5636) Benjamin Zaitlen
计算 dataframe 的长度作为第一列的长度 (dask#5635) Matthew Rocklin
文档¶
文档修复 (dask#5665) James Bourbeau
更新文档构建说明 (dask#5640) James Bourbeau
添加文档构建 (dask#5617) James Bourbeau
2.8.1 / 2019-11-22¶
Array¶
如果在
da.rechunk中未给定值,则使用自动 rechunking (dask#5605) Matthew Rocklin
核心¶
添加简单的 action 以激活 GH actions (dask#5619) James Bourbeau
DataFrame¶
修复
aggregate_row_groups中的“file_path_0” bug (dask#5627) Richard J Zamora为
read_parquet添加chunksize参数 (dask#5607) Richard J Zamora更改
test_repartition_npartitions以支持 arch64 架构 (dask#5620) ossdev07groupby + agg 后丢失 Categories (dask#5423) Oliver Hofkens
修复 parquet metadata 文件相关的相对路径问题 (dask#5608) Nuno Gomes Silva
在 dataframes 中启用 gpu 支持的协方差/相关性计算 (dask#5597) Richard J Zamora
文档¶
修复机构 FAQ 和未知文档警告 (dask#5616) James Bourbeau
添加某些 utils 的文档 (dask#5609) Tom Augspurger
移除
html_extra_path(dask#5614) James Bourbeau修复 See Also 参考 (dask#5612) Tom Augspurger
2.8.0 / 2019-11-14¶
Array¶
实现完整的 dask.array.tile 函数 (dask#5574) Bouwe Andela
添加带自动 rechunking 的轴向中位数计算 (dask#5575) Matthew Rocklin
允许 da.asarray 对输入进行分块 (dask#5586) Matthew Rocklin
Bag¶
在 Bag 名称中使用 key_split (dask#5571) Matthew Rocklin
核心¶
将 Doctests 切换到 Py3.7 (dask#5573) Ryan Nazareth
放宽 get_colors 测试,以适应新的 Bokeh 发布版本 (dask#5576) Matthew Rocklin
添加 dask.blockwise.fuse_roots 优化 (dask#5451) Matthew Rocklin
添加小 dicts 的 sizeof 实现 (dask#5578) Matthew Rocklin
更新 fsspec, gcsfs, s3fs (dask#5588) Tom Augspurger
DataFrame¶
为 groupby 添加 dropna 参数 (dask#5579) Richard J Zamora
恢复“移除对 dask_cudf 的导入,dask_cudf 现在是 cudf 的一部分 (#5568)” (dask#5590) Matthew Rocklin
文档¶
添加 dask.compute 函数的最佳实践 (dask#5583) Matthew Rocklin
创建 FUNDING.yml (dask#5587) Gina Helfrich
添加 coordination primitives 的截屏 (dask#5593) Matthew Rocklin
将 funding 移至 .github 仓库 (dask#5589) Tom Augspurger
更新 calendar 链接 (dask#5569) Tom Augspurger
2.7.0 / 2019-11-08¶
此版本不再支持 Python 3.5
Array¶
更新 da.array 以始终返回一个 dask array (dask#5510) James Bourbeau
跳过对 trivial 输入的 transpose (dask#5523) Ryan Abernathey
在 tokenize 中避免使用 NumPy scalar 字符串表示 (dask#5527) James Bourbeau
移除不必要的 tiledb shape 约束 (dask#5545) Norman Barker
移除 sparse array HTML repr 中的 bytes (dask#5556) James Bourbeau
核心¶
放弃对 Python 3.5 的支持 (dask#5528) James Bourbeau
更新 distributed 测试中 fixtures 的使用方式 (dask#5497) Matthew Rocklin
在 ensure_dict 中避免使用相同的 dicts 进行更新 (dask#5501) James Bourbeau
测试上游 (Test Upstream) (dask#5516) Tom Augspurger
加速 reverse_dict (dask#5479) Ryan Grout
更新 test_imports.sh (dask#5534) James Bourbeau
在 multiprocess 和 threaded schedulers 中支持 cgroups 对 cpu count 的限制 (dask#5499) Albert DeFusco
更新 CI 上 pyarrow 的最低版本要求 (dask#5562) James Bourbeau
将 cloudpickle 设为可选依赖 (dask#5511) crusaderky
DataFrame¶
添加 index_col 用法的示例 (dask#3072) Bruno Bonfils
显式使用 iloc 进行行索引 (dask#5500) Krishan Bhasin
接受 dask 数组进行列赋值 (dask#5224) Henrique Ribeiro-
实现 SeriesGroupBy 的 unique 和 value_counts (dask#5358) Scott Sievert
添加 pyarrow tables 和 columns 的 sizeof 定义 (dask#5522) Richard J Zamora
在基于 pyarrow 的 read_parquet 中启用行组任务分区 (dask#5508) Richard J Zamora
移除 dd.merge 文档字符串中的 npartitions='auto' (dask#5531) James Bourbeau
应用 enforce 错误消息显示非重叠列 (dask#5530) Tom Augspurger
为重复的 dtypes 优化 meta_nonempty (dask#5553) Petio Petrov
移除对 dask_cudf 的导入,dask_cudf 现在是 cudf 的一部分 (dask#5568) Mads R. B. Kristensen
文档¶
使 FAQ 文档中的大写更加一致 (dask#5512) Matthew Rocklin
添加 CONTRIBUTING.md (dask#5513) Jacob Tomlinson
文档可选依赖项 (dask#5456) Prithvi MK
更新 helm chart 文档以反映新的 chart 仓库 (dask#5539) Jacob Tomlinson
将 Resampler 添加到 API 文档 (dask#5551) James Bourbeau
添加自适应部署截屏 [skip ci] (dask#5566) Matthew Rocklin
2.6.0 / 2019-10-15¶
核心¶
在进入
toolz.merge之前对 graphs 调用ensure_dict(dask#5486) Matthew Rocklin整合哈希分发函数 (dask#5476) Richard J Zamora
DataFrame¶
在 Parquet 代码中支持 Python 3.5 (dask#5491) Benjamin Zaitlen
在
warn_dtype_mismatch中避免身份检查 (dask#5489) Tom Augspurger启用未使用的 groupby 测试 (dask#3480) Jörg Dietrich
移除旧的 parquet 和 bcolz dataframe 优化 (dask#5484) Matthew Rocklin
为
read_parquet添加 getitem 优化 (dask#5453) Tom Augspurger使用
_constructor_sliced方法确定 Series 类型 (dask#5480) Richard J Zamora修复未排序基础 series 索引的 map(series) (dask#5459) Justin Waugh
修复 Groupby 标签导致的
KeyError(dask#5467) Ryan Nazareth
文档¶
使用 Zoom 会议代替 appear.in (dask#5494) Matthew Rocklin
更新 SSH 文档以包含
SSHCluster(dask#5482) Matthew Rocklin更新“为什么选择 Dask?”页面 (dask#5473) Matthew Rocklin
2.5.2 / 2019-10-04¶
数组¶
修正非对称重叠的块大小逻辑 (dask#5449) Ben Jeffery
将 da.unify_chunks 设为公共 API (dask#5443) Matthew Rocklin
DataFrame¶
修复 dask.dataframe.fillna 对 Scalar 对象的处理 (dask#5463) Zhenqing Li
文档¶
移除 Spark 比较页面中的框 (dask#5445) Matthew Rocklin
更新云文档 (dask#5444) Matthew Rocklin
2.5.0 / 2019-09-27¶
核心¶
为 get_dependencies 任务添加 sentinel no_default (dask#5420) James Bourbeau
更新 fsspec 版本 (dask#5415) Matthew Rocklin
DataFrame¶
添加选项以不在 dd.from_delayed 中检查 meta (dask#5436) Christopher J. Wright
修复 pyarrow master 导致的 test_timeseries_nulls_in_schema 失败 (dask#5421) Richard J Zamora
减小 pyarrow/parquet 中 read_metadata 的输出大小 (dask#5391) Richard J Zamora
测试使用 npartitions 进行 repartition 的数值边界情况。 (dask#5433) amerkel2
取消 pandas-datareader 测试的 xfail 标记 (dask#5430) Tom Augspurger
添加 DataFrame.pop 实现 (dask#5422) Matthew Rocklin
为基于 cudf 的 dataframes 启用使用 cupy
values的 merge/set_index (dask#5322) Richard J Zamoradrop_duplicates 支持 positional subset 参数 (dask#5410) Wes Roach
文档¶
为 array、bag、dataframe、delayed、futures 和 setup 添加截屏视频 (dask#5429) (dask#5424) Matthew Rocklin
修复分隔符解析文档 (dask#5428) Mahmut Bulut
更新概览图片 (dask#5404) James Bourbeau
2.4.0 / 2019-09-13¶
数组¶
添加显式的
h5py.File模式 (dask#5390) James Bourbeau提供计算未知 array chunks 大小的方法 (dask#5312) Scott Sievert
向
Array.__dask_postpersist__添加_meta(dask#5353) Benoit Bovy修正
da.asarray和da.asanyarray对 datetime64 dtype 和 xarray 对象的处理 (dask#5334) Stephan Hoyer添加 shape 实现 (dask#5293) Tom Augspurger
向 array 文本表示添加 chunktype (dask#5289) James Bourbeau
Array.random.choice: 处理类数组非数组对象 (dask#5283) Gabe Joseph
核心¶
修复向量化函数没有
__name__属性时的funcname(dask#5399) James Bourbeau截断
funcname以避免过长的键名 (dask#5383) Matthew Rocklin在
funcname中添加对numpy.vectorize的支持 (dask#5396) James Bourbeau修复 HDFS 上游测试 (dask#5395) Tom Augspurger
支持在
parse_bytes/timedelta中使用数字和 None (dask#5384) Matthew Rocklin修复内存映射 numpy 数组上子索引的 tokenization (dask#5351) Henry Pinkard
上游修正 (dask#5300) Tom Augspurger
DataFrame¶
允许 pandas 转换统计信息的类型 (dask#5402) Richard J Zamora
为 Series 和 DataFrame 实现 explode (dask#5381) Arpit Solanki
set_index 在分类数据上失败,如果类别数少于分区数 (dask#5354) Oliver Hofkens
支持输出到单个 CSV 文件 (dask#5304) Hongjiu Zhang
添加
groupby().transform()(dask#5327) Oliver Hofkens为 pyarrow dataset 调用添加 filter kwarg (dask#5348) Richard J Zamora
实现并检查 parquet 的默认压缩设置 (dask#5335) Sarah Bird
将 sqlalchemy 参数传递给 delayed 对象 (dask#5332) Arpit Solanki
修复 arrow-parquet 中的 schema 处理 (dask#5307) Richard J Zamora
为 DF 和 Series
groupby().idxmin/max()添加支持 (dask#5273) Oliver Hofkens添加相关性计算并添加测试 (dask#5296) Benjamin Zaitlen
文档¶
对 Array chunk 文档进行少量编辑 (dask#5372) Scott Sievert
向 API 文档添加方法 (dask#5387) Tom Augspurger
为配置示例添加命名空间 (dask#5374) Matthew Rocklin
向诊断页面添加 get_task_stream 和 profile (dask#5375) Matthew Rocklin
添加使用 Dask 加载数据的最佳实践 (dask#5369) Matthew Rocklin
在最佳实践中添加关于 threads 和 processes 的说明 (dask#5340) Matthew Rocklin
更新 cuDF 链接 (dask#5328) James Bourbeau
修复了括号放置的小拼写错误 (dask#5311) Eugene Huang
更新 reshape docstring 中的链接 (dask#5297) James Bourbeau
2.3.0 / 2019-08-16¶
数组¶
当
from_array被给予 dask 数组时抛出异常 (dask#5280) David Hoese避免两次调整 gufunc 的 meta dtype (dask#5274) Peter Andreas Entschev
向 map_blocks 添加
meta=关键字,并添加稀疏测试 (dask#5269) Matthew Rocklin添加 rollaxis 和 moveaxis (dask#4822) Tobias de Jong
始终递增旧的 chunk 索引 (dask#5256) James Bourbeau
洗牌 dask 数组 (dask#3901) Tom Augspurger
修复使用 bool dask 数组索引 dask 数组时的顺序问题 (dask#5151) James Bourbeau
Bag¶
为 bag 生成器中的内存泄漏添加临时解决方案 (dask#5208) Marco Neumann
核心¶
设置严格的 xfail 选项 (dask#5220) James Bourbeau
test-upstream (dask#5267) Tom Augspurger
修复 HDFS CI 失败 (dask#5234) Tom Augspurger
确保如果未安装 fastparquet 和 pyarrow 则跳过 parquet 测试 (dask#5217) James Bourbeau
将 fsspec 添加到 readthedocs (dask#5207) Matthew Rocklin
在 CI 测试中将 NumPy 和 Pandas 升级到 1.17 和 0.25 (dask#5179) John A Kirkham
DataFrame¶
修复
DataFrame.querydocstring (不正确的 numexpr API) (dask#5271) Doug DavisParquet 元数据处理改进 (dask#5218) Richard J Zamora
改进关于索引的已排序 parquet 列的消息提示 (dask#5265) Martin Durant
为 cudf 添加
rearrange_by_divisions和set_index支持 (dask#5205) Richard J Zamora修复使用整数列名时的
groupby.std()(dask#5096) Nicolas Hug将
hash_pandas_object通用化以支持非 pandas 后端 (dask#5184) GALI PREM SAGAR添加 rolling cov (dask#5154) Ivars Geidans
在 drop 函数中添加 columns 参数 (dask#5223) Henrique Ribeiro
文档¶
更新机构常见问题解答文档 (dask#5277) Matthew Rocklin
添加机构常见问题解答草稿 (dask#5214) Matthew Rocklin
为 dask-spark 页面制作框 (dask#5249) Martin Durant
添加 shuffle 文档的动机 (dask#5213) Matthew Rocklin
修复最佳实践的链接和 API 条目 (dask#5246) Martin Durant
移除“字节”(内部数据摄取)文档页面 (dask#5242) Martin Durant
将本地分布式页面重定向到 distributed.dask.org (dask#5248) Matthew Rocklin
清理 API 页面 (dask#5247) Matthew Rocklin
移除安装文档中多余的换行符 (dask#5243) Matthew Rocklin
移除计算阶段文档中的项目列表 (dask#5245) Martin Durant
从目录侧边栏移除自定义图 (dask#5241) Matthew Rocklin
移除自定义集合的实验状态标记 (dask#5236) James Bourbeau
向 Why Dask? 添加目录 (dask#5244) James Bourbeau
将 bag 概览移至顶层 bag 页面 (dask#5240) James Bourbeau
移除 use-cases,推荐 stories.dask.org (dask#5238) Matthew Rocklin
移除 index.rst 中冗余的目录信息 (dask#5235) James Bourbeau
提升分布式诊断文档中 dashboard 的重要性 (dask#5239) Martin Durant
更新 HLG 文档示例中的“add”层 (dask#5237) James Bourbeau
更新 GUFunc 文档 (dask#5232) Matthew Rocklin
2.2.0 / 2019-08-01¶
数组¶
如果输入遵循 NEP-18,则使用 da.from_array(…, asarray=False) (dask#5074) Matthew Rocklin
为 from_array 文档添加缺失的属性 (dask#5108) Peter Andreas Entschev
修复某些 reduction 函数的 meta 计算 (dask#5035) Peter Andreas Entschev
如果在 to_zarr 中发现未知 chunks 则抛出有用的错误 (dask#5148) James Bourbeau
移除无效的 pad 测试 (dask#5122) Tom Augspurger
忽略 compute_meta 中的 NumPy 警告 (dask#5103) Peter Andreas Entschev
修复单维度输入数组的峰度计算 (dask#5177) @andrethrill
在测试中支持 Numpy 1.17 (dask#5192) Matthew Rocklin
Bag¶
为 bag 测试提供 pool 以解决间歇性失败 (dask#5172) Tom Augspurger
核心¶
将 dask 基于 fsspec (dask#5064) (dask#5121) Martin Durant
各种上游兼容性修复 (dask#5056) Tom Augspurger
再次将分布式测试设为可选。 (dask#5128) Elliott Sales de Andrade
修复 dask 中的 HDFS (dask#5130) Martin Durant
忽略更多无效值警告。 (dask#5140) Elliott Sales de Andrade
DataFrame¶
修复 pd.MultiIndex 大小估计 (dask#5066) Brett Naul
通用化 has_known_categories (dask#5090) GALI PREM SAGAR
重构 Parquet 引擎 (dask#4995) Richard J Zamora
修复不稳定的 partd 测试 (dask#5111) Tom Augspurger
调整 is_dataframe_like 以适应 value_counts 的变化 (dask#5143) Tom Augspurger
通用化滚动窗口以支持非 Pandas dataframes (dask#5149) Nick Becker
避免在 pivot_table 中进行不必要的聚合 (dask#5173) Daniel Saxton
向 apply_and_enforce 错误消息添加列名 (dask#5180) Matthew Rocklin
向 to_parquet 添加 schema 关键字参数 (dask#5150) Sarah Bird
允许 fastparquet 处理文件列表的 gather_statistics=False (dask#5157) Richard J Zamora
文档¶
向 README 添加 NumFOCUS 徽章 (dask#5086) James Bourbeau
记录 DataFrame.set_index 计算行为 Natalya Rapstine
使用 pip install . 代替调用 setup.py (dask#5139) Matthias Bussonier
关闭用户调查 (dask#5147) Tom Augspurger
修复 Google Calendar 会议链接 (dask#5155) Loïc Estève
添加 docker 镜像自定义示例 (dask#5171) James Bourbeau
在 fsspec 之后更新 remote-data-services (dask#5170) Martin Durant
修复 spark.rst 中的拼写错误 (dask#5164) Xavier Holt
更新 setup/python 文档以支持 async/await API (dask#5163) Matthew Rocklin
更新本地存储 HPC 文档 (dask#5165) Matthew Rocklin
2.1.0 / 2019-07-08¶
数组¶
为
svd_compressed添加recompute=关键字,以减少内存使用 (dask#5041) Matthew Rocklin更改
__array_function__实现以兼容旧版本 (dask#5043) Ralf Gommers向
apply_along_axis添加dtype和shapekwargs (dask#3742) Davis Bennett修复空元组轴的 reduction (dask#5025) Peter Andreas Entschev
在
stack中丢弃大小为 0 的数组 (dask#4978) John A Kirkham
核心¶
从 pandas
to_parquet调用中移除 index 关键字 (dask#5075) James Bourbeau修复上游开发 CI 构建安装问题 (dask#5072) James Bourbeau
确保标量数组不渲染为 SVG (dask#5058) Willi Rath
环境创建大修 (dask#5038) Tom Augspurger
s3fs, moto 兼容性 (dask#5033) Tom Augspurger
pytest 5.0 兼容 (dask#5027) Tom Augspurger
DataFrame¶
修复 blockwise 中的
compute_meta递归 (dask#5048) Peter Andreas Entschev移除
get_dummies对 pandas 的硬依赖 (dask#5057) GALI PREM SAGAR处理 repartition 中不可整除的大小 (dask#5013) George Sakkis
处理 pyarrow 中 timestamp 和
preserve_index的变化 (dask#5018) Richard J Zamora修复
str.split(expand=False)的未定义meta(dask#5022) Brett Naul移除用于调试
merge_asof的检查 (dask#5011) Cody Johnson在获取 dataframes 中的 accessor 时不要使用 type (dask#4992) Matthew Rocklin
将
melt添加为 Dask DataFrame 的方法 (dask#4984) Dustin Tindall向
to_hdf添加类路径支持 (dask#5003) James Bourbeau
文档¶
在 JupyterHub 文档中指向最新的 K8s setup 文章 (dask#5065) Sean McKenna
将 vizualize 改为 visualize (dask#5061) David Brochart
修复 delayed best practices 中
from_sequence的拼写错误 (dask#5045) James Bourbeau在文档中添加用户调查链接 (dask#5026) James Bourbeau
修复优化文档中的拼写错误 (dask#5015) James Bourbeau
更新社区会议信息 (dask#5006) Tom Augspurger
2.0.0 / 2019-06-25¶
数组¶
在 da.indices 中支持自动 chunking (dask#4981) James Bourbeau
如果没有要堆叠的数组则报错 (dask#4975) John A Kirkham
非对称数组重叠 (dask#4863) Michael Eaton
在 dask 数组中尽可能分派 concatenate (dask#4669) Hameer Abbasi
修复内存映射 numpy 数组在同一文件的不同部分的 tokenization 问题 (dask#4931) Henry Pinkard
在 da.asarray 中保留 NumPy 条件以保留输出形状 (dask#4945) Alistair Miles
扩展 foo_like_safe 的用法 (dask#4946) Peter Andreas Entschev
将 einsum 的 order/casting 参数延迟到 NumPy 实现 (dask#4914) Peter Andreas Entschev
移除矩计算中的 numpy 警告 (dask#4921) Matthew Rocklin
修复 meta_from_array 以支持 Xarray 测试套件 (dask#4938) Matthew Rocklin
缓存整数切片的 chunk 边界 (dask#4923) Bruce Merry
在 concatenate 中丢弃大小为 0 的数组 (dask#4167) John A Kirkham
如果 concatenate 没有给定数组则抛出 ValueError (dask#4927) John A Kirkham
在
concatenate中使用_meta提升类型 (dask#4925) John A Kirkham在 Dask 数组的 html repr 中添加 chunk 类型 (dask#4895) Matthew Rocklin
- 添加 Dask Array._meta 属性 (dask#4543) Peter Andreas Entschev
修复灵活类型的 _meta 切片 (dask#4912) Peter Andreas Entschev
在 concatenate 中进行少量 meta 构建清理 (dask#4937) Peter Andreas Entschev
进一步放宽 Array meta 对 Xarray 的检查 (dask#4944) Matthew Rocklin
在 da.from_delayed 中支持 meta= 关键字 (dask#4972) Matthew Rocklin
沿轴 concatenate meta (dask#4977) John A Kirkham
在 stack 中使用 meta (dask#4976) John A Kirkham
将 blockwise_meta 移至更通用的 compute_meta 函数 (dask#4954) Matthew Rocklin
将 dask 数组的 .partitions 别名为 .blocks 属性 (dask#4853) Genevieve Buckley
丢弃过时的
numpy_compat函数 (dask#4850) John A Kirkham允许 da.eye 支持使用 chunks=’auto’ 的任意 chunking 大小 (dask#4834) Anderson Banihirwe
修复 dask.array 测试中的 CI 警告 (dask#4805) Tom Augspurger
使 map_blocks 支持 drop_axis + block_info (dask#4831) Bruce Merry
在 Array._repr_html_ 中添加 SVG 图像和表格 (dask#4794) Matthew Rocklin
ufunc: 避免使用 __array_wrap__,倾向于使用 __array_function__ (dask#4708) Peter Andreas Entschev
确保简单的 padding 返回原始数组 (dask#4990) John A Kirkham
使用 0 大小数组测试
da.block(dask#4991) John A Kirkham
核心¶
静默 CI 中的依赖安装 (dask#4960) Tom Augspurger
在测试中对警告引发异常 (dask#4916) Tom Augspurger
向 setup.py 添加一个 diagnostics extra (包含 bokeh) (dask#4924) John A Kirkham
重载 HighLevelGraphs 的 values 方法 (dask#4918) James Bourbeau
向 Dask collections 添加 __await__ 方法 (dask#4901) Matthew Rocklin
如果安装了 snappy (而非 python-snappy),也忽略可能发生的 AttributeErrors (dask#4908) Mark Bell
在 config.rename 中规范化键名 (dask#4903) Ian Bolliger
将 partd 的最低版本提升到 0.3.10 (dask#4890) Tom Augspurger
捕获 async def SyntaxError (dask#4836) James Bourbeau
在 ensure_file 中捕获 IOError (dask#4806) Justin Poehnelt
清理 CI 警告 (dask#4798) Tom Augspurger
将 distributed 的 parse 和 format 函数移至 dask.utils (dask#4793) Matthew Rocklin
应用 black 格式化 (dask#4983) James Bourbeau
在 wheels 中打包 license 文件 (dask#4988) John A Kirkham
DataFrame¶
向 repartition 添加一个可选的 partition_size 参数 (dask#4416) George Sakkis
merge_asof 和 prefix_reduction (dask#4877) Cody Johnson
允许 dataframes 通过 dask 数组进行索引 (dask#4882) Endre Mark Borza
避免在 pytest.raises 中使用废弃的 message 参数 (dask#4962) James Bourbeau
移除 Dataframe accessors 中的 pandas pinning (dask#4955) Matthew Rocklin
修复同名 series 的相关性计算 (dask#4934) Philipp S. Sommer
将 Dask Series 映射到 Dask Series (dask#4872) Justin Waugh
添加 groupby 协方差/相关性 (dask#4889) Benjamin Zaitlen
使用 to_datetime 时保留索引名 (dask#4905) Ian Bolliger
添加 dataframes 的并行方差计算 (dask#4865) Ksenia Bobrova
为 arrays 和 dataframes 添加 divmod 实现 (dask#4884) Henrique Ribeiro
避免使用 pandas.compat (dask#4881) Tom Augspurger
添加了 Series, DataFrame 和 Index 的 accessor 注册 (dask#4829) Tom Augspurger
向 read_json 添加 read_function 关键字 (dask#4810) Richard J Zamora
在 check_meta 中提供完整的类型名称 (dask#4819) Matthew Rocklin
向 describe() 添加对非数值数据的支持 (dask#4791) Ksenia Bobrova
扩展 dtypes 的标量。 (dask#4459) Tom Augspurger
在 dd.from_delayed 中在 compute 之前调用 head (dask#4802) Matthew Rocklin
添加对基于时间索引的 DataFrames 中窗口大于分区大小的滚动操作的支持 (dask#4796) Jorge Pessoa
更新 groupby-apply 文档并添加警告 (dask#4800) Tom Augspurger
更改
_maybe_slice中的 groupby 相关测试 (dask#4786) Benjamin Zaitlen添加主最佳实践文档 (dask#4745) Matthew Rocklin
添加关于 Dask 如何与 GPU 协同工作的文档 (dask#4792) Matthew Rocklin
添加 cli API 文档 (dask#4788) James Bourbeau
确保 concat 输出具有一致的 dtypes (dask#4692) Guillaume Lemaitre
修复 pandas_datareader 依赖项安装问题 (dask#4989) James Bourbeau
在 read_hdf 中接受 pathlib.Path 作为 pattern (dask#3335) Jörg Dietrich
文档¶
将 CLI API 文档移至相关页面 (dask#4980) James Bourbeau
将 to_datetime 函数添加到 dataframe API 文档 Matthew Rocklin
为 dask.array.ma.average 添加文档条目 (dask#4970) Bouwe Andela
将 bag.read_avro 添加到 bag API 文档 (dask#4969) James Bourbeau
移除修改 changelog 的要求 (dask#4915) Matthew Rocklin
添加关于 meta 列顺序的文档 (dask#4887) Tom Augspurger
在 DataFrame.shift 中添加文档说明 (dask#4886) Tom Augspurger
文档:修复拼写错误 (dask#4868) Paweł Kordek
将 do/don’t 放入延迟最佳实践文档的框中 (dask#3821) Martin Durant
文档修正 (dask#2528) Tom Augspurger
向付费支持文档部分添加 quansight (dask#4838) Martin Durant
添加自定义启动文档 (dask#4833) Matthew Rocklin
允许
utils.derive_from接受函数,并应用于整个数组 (dask#4804) Martin Durant向最佳实践添加“避免大分区”部分 (dask#4808) Matthew Rocklin
更新 joblib 的 URL 指向托管其文档的新网站 (dask#4816) Christian Hudon
1.2.2 / 2019-05-08¶
数组¶
澄清 array.store 的 regions kwarg (dask#4759) Martin Durant
向 da.random.randint 添加 dtype= 参数 (dask#4753) Matthew Rocklin
将 Xarray 数据集规范化为 Dask 数组 (dask#4756) Matthew Rocklin
移除 da.histogram 中的 normed 关键字 (dask#4755) Matthew Rocklin
Bag¶
向 Bag.distinct 添加 key 参数 (dask#4423) Daniel Severo
核心¶
添加核心 dask 配置文件 (dask#4774) Matthew Rocklin
向 MANIFEST.in 添加核心 dask 配置文件 (dask#4780) James Bourbeau
启用 HTTP 文件系统的 glob 功能 (dask#3926) Martin Durant
HTTPFile.seek with whence=1 (dask#4751) Martin Durant
DataFrame¶
移除 dask.dataframe.groupby 中对 Pandas 的显式引用 (dask#4778) Matthew Rocklin
为 DataFrame.groupby() 添加对 group_keys kwarg 的支持 (dask#4771) Brian Chu
描述文档 (dask#4762) Martin Durant
移除累积聚合中的显式 pandas 检查 (dask#4765) Nick Becker
为 read_json 添加 meta 并添加测试 (dask#4588) Abhinav Ralhan
添加 dtype casting 的测试 (dask#4760) Martin Durant
实现 Series.str.split(expand=True) (dask#4744) Matthew Rocklin
文档¶
根据尝试运行测试对 develop.rst 进行调整 (dask#4772) Christian Hudon
添加描述计算阶段的文档 (dask#4766) Matthew Rocklin
从 spark 文档中引导用户至 Dask-Yarn (dask#4770) Matthew Rocklin
更新 delayed 文档中的图片以移除标签 (dask#4768) Martin Durant
解释 dask 数组的中间存储 (dask#4025) John A Kirkham
在 array 最佳实践中指定 bash 代码块 (dask#4764) James Bourbeau
添加 array 最佳实践文档 (dask#4705) Matthew Rocklin
更新优化文档,说明 cull 不再是自动的 (dask#4752) Matthew Rocklin
1.2.1 / 2019-04-29¶
数组¶
修复 map_blocks 与 block_info 和 broadcasting 的问题 (dask#4737) Bruce Merry
将 da.bincount 中的 ‘minlength’ 关键字参数设为可选 (dask#4684) Genevieve Buckley
添加对没有数组参数的 map_blocks 的支持 (dask#4713) Bruce Merry
添加 dask.array.trace (dask#4717) Danilo Horta
添加对 cupy.ndarray 的 sizeof 支持 (dask#4715) Peter Andreas Entschev
向 from_array 添加 chunks=’auto’ (dask#4704) Matthew Rocklin
向 from_zarr 添加 name kwarg (dask#4663) Michael Eaton
如果将 dask 数组作为 da.ones, zeros, empty 或 full 的形状,则抛出 TypeError (dask#4707) Genevieve Buckley
添加 TileDB 后端 (dask#4679) Isaiah Norton
核心¶
延迟长列表参数 (dask#4735) Matthew Rocklin
将 numpy 升级到 >= 1.13,pandas 升级到 >= 0.21.0 (dask#4720) Jim Crist
移除文件“test” (dask#4710) James Bourbeau
重新启用开发构建,使用上游库 (dask#4696) Peter Andreas Entschev
移除 HighLevelGraph 构造函数中的断言 (dask#4699) Matthew Rocklin
DataFrame¶
更改累积聚合的 last-nonnull-value 算法 (dask#4736) Nick Becker
重构 array.percentile 和 dataframe.quantile 以使用 t-digest (dask#4677) Janne Vuorela
允许对已排序的 dataframes 进行朴素连接 (dask#4725) Matthew Rocklin
通过使用 methodcaller 移除 melt 对 pandas 的硬依赖 (dask#4719) Nick Becker
添加 Dataframe.replace (dask#4714) Matthew Rocklin
向 pd.DataFrame.dropna 添加 ‘threshold’ 参数 (dask#4625) Nathan Matare
文档¶
在 docstring 早期添加关于派生 docstring 的警告 (dask#4716) Matthew Rocklin
创建 dataframe 最佳实践文档 (dask#4703) Matthew Rocklin
取消注释 dask_sphinx_theme (dask#4728) James Bourbeau
修复 Queue/fire_and_forget 示例中的小拼写错误 (dask#4709) Matthew Rocklin
更新 from_pandas 文档字符串以匹配签名 (dask#4698) James Bourbeau
1.2.0 / 2019-04-12¶
Array¶
修复稀疏数组上的 mean() 和 moment() 方法 (dask#4525) Peter Andreas Entschev
添加 NEP-18 测试。 (dask#4675) Hameer Abbasi
允许在 normalize_chunks 中使用 None 表示“不分块” (dask#4656) Matthew Rocklin
修复 auto_chunks 中的限制值 (dask#4645) Matthew Rocklin
Core¶
更新诊断 bokeh 测试以兼容 bokeh>=1.1.0 (dask#4680) Philipp Rudiger
调整 codecov 的 target/threshold,禁用 patch (dask#4671) Peter Andreas Entschev
始终以空 http buffer 开始,而不是 None (dask#4673) Martin Durant
DataFrame¶
从 array 创建 dask dataframe 时传播索引 dtype 和 name (dask#4686) Henrique Ribeiro
清理并记录 rearrange_column_by_tasks (dask#4674) Matthew Rocklin
将一些 parquet 测试标记为 xfail (dask#4667) Peter Andreas Entschev
修复 arrow 0.13.0 导致的 parquet 故障 (dask#4668) Martin Durant
修复 parquet 加载时的时区元数据推断 (dask#4655) Martin Durant
在 dd.utils 中使用 is_dataframe/index_like (dask#4657) Matthew Rocklin
为 groupby sum 方法添加 min_count 参数 (dask#4648) Henrique Ribeiro
Documentation¶
将 delayed 的额外依赖项添加到安装文档中 (dask#4660) James Bourbeau
1.1.5 / 2019-03-29¶
Array¶
确保在 normalize_chunks 中使用 dtype 关键字参数 (dask#4646) Matthew Rocklin
Core¶
在 LocalFileSystem 中使用递归 glob (dask#4186) Brett Naul
避免 YAML 弃用 (dask#4603)
修复 CI 并添加 set -e (dask#4605) James Bourbeau
支持 dask.visualize 中的内置序列类型 (dask#4602)
解包/打包 orderedDict (dask#4623) Justin Poehnelt
将 da.random.randint 添加到 API 文档 (dask#4628) James Bourbeau
将 zarr 添加到 CI 环境中 (dask#4604) James Bourbeau
启用 codecov (dask#4631) Peter Andreas Entschev
DataFrame¶
支持设置索引 (dask#4565)
DataFrame.itertuples 接受 index, name 关键字参数 (dask#4593) Dan O’Donovan
在 dd.Series.unique 中支持非 Pandas Series (dask#4599) Benjamin Zaitlen
使用 ._is_partition_type 谓词替换显式类型检查的使用 (dask#4533)
移除测试中额外的 pandas 警告 (dask#4576)
检查对象是否具有 name/dtype 属性,而不是检查类型 (dask#4606)
修复设置分类代码为 float 时的警告 (dask#4624) Julia Signell
修复索引 to_frame 方法上的重命名问题 (dask#4498) Henrique Ribeiro
修复连接两个单分区 dataframe 时的 divisions (dask#4636) Justin Waugh
提供信息丰富的 meta= 警告 (dask#4637) Matthew Rocklin
为 Series.__getitem__ 添加信息丰富的错误消息 (dask#4638) Matthew Rocklin
在使用 read_csv 的 index 或 index_col 时添加清晰的异常消息 (dask#4651) Álvaro Abella Bascarán
Documentation¶
添加自定义 groupby 聚合的文档 (dask#4571)
文档 dataframe joins (dask#4569)
指定基于 fork 的贡献 (dask#4619) James Bourbeau
更正 to_parquet 文档示例 (dask#4641) Aaron Fowles
更新并保护一些引用 (dask#4649) Søren Fuglede Jørgensen
1.1.4 / 2019-03-08¶
Array¶
在 compress 中使用 mask selection (dask#4548) John A Kirkham
在 extract 中使用 asarray (dask#4549) John A Kirkham
测试 concatenation 时使用正确的 dtype。 (dask#4539) Elliott Sales de Andrade
修复 CuPy 测试或正确标记为 xfail (dask#4564) Peter Andreas Entschev
Core¶
在 read_bytes(sample=…) 中使用 parse_bytes (dask#4554) Matthew Rocklin
DataFrame¶
再次修复 object dtype keys 上的 groupby-standard deviation (dask#4541) Matthew Rocklin
TST/CI:更新以兼容 pandas 0.24.1 (dask#4551) Tom Augspurger
添加控制 timeseries 中 unique elements 数量的能力 (dask#4557) Matthew Rocklin
在 read_csv 中为其他可迭代对象添加对参数 skiprows 的支持 (dask#4560) @JulianWgs
Documentation¶
DataFrame 到 Array 的转换和未知分块 (dask#4516) Scott Sievert
添加随机 array 创建的文档 (dask#4566) Matthew Rocklin
修复文档字符串中的拼写错误 (dask#4572) Shyam Saladi
1.1.3 / 2019-03-01¶
Array¶
修改 mean chunk 函数以返回 dicts 而不是 arrays (dask#4513) Matthew Rocklin
更改 CI 中的稀疏安装以兼容 NumPy/Python2 (dask#4537) Matthew Rocklin
DataFrame¶
使 merge 可以在 pandas/其他 dataframe 类型上调度 (dask#4522) Matthew Rocklin
read_sql_table - datetime 索引修复和索引类型检查 (dask#4474) Joe Corbett
使用广义形式的索引检查 (is_index_like) (dask#4531) Benjamin Zaitlen
添加带有 object dtypes 的 groupby reductions 的测试 (dask#4535) Matthew Rocklin
Documentation¶
添加文档索引中缺失的方法 (dask#4528) Bart Broere
1.1.2 / 2019-02-25¶
Array¶
修复 normalize_array 中另一个 unicode/mixed-type 边缘情况 (dask#4489) Marco Neumann
添加 dask.array.diagonal (dask#4431) Danilo Horta
修改 moment chunk 函数以返回 dicts (dask#4519) Peter Andreas Entschev
Bag¶
确保 bag.from_sequence 总是至少包含一个分区 (dask#4475) Anderson Banihirwe
实现 bag.fold 的 out_type (dask#4502) Matthew Rocklin
从 bag keynames 中移除 map (dask#4500) Matthew Rocklin
避免在 map_partitions 中使用 itertools.repeat (dask#4507) Matthew Rocklin
DataFrame¶
修复使用 fastparquet 时 Windows 上相对路径解析问题 (dask#4445) Janne Vuorela
修复 pyarrow 和 hdfs 中的 bug (dask#4453) (dask#4455) Michał Jastrzębski
将 cudf 特定的代码替换为 dask-cudf 导入 (dask#4470) Matthew Rocklin
避免在 groupby-var 中使用 groupby.agg(callable) (dask#4482) Matthew Rocklin
在 check_meta 中将 uint 类型视为数值类型 (dask#4485) Marco Neumann
修复 groupby 注释中的一些拼写错误 (dask#4494) Daniel Saxton
添加 set_index(inplace=True) 周围的错误消息 (dask#4501) Matthew Rocklin
向预期的 meta 错误消息添加模块名称 (dask#4499) Matthew Rocklin
Documentation¶
更新文档以使用
from_zarr(dask#4472) John A KirkhamDOC:为 remote-data-services 添加 Using Other S3-Compatible Services 部分 (dask#4405) Aploium
修复 changelog 中 section 的 header 级别 (dask#4483) Bruce Merry
为 pip install [skip-ci] 添加引号 (dask#4508) James Bourbeau
Core¶
在状态初始化后扩展 started_cbs (dask#4460) Marco Neumann
修复 HTTPFile._fetch_range 处理 headers 的 bug (dask#4479) (dask#4480) Ross Petchler
为 diamond fusion 重复 optimize_blockwise (dask#4492) Matthew Rocklin
1.1.1 / 2019-01-31¶
Array¶
添加对 cupy.einsum 的支持 (dask#4402) Johnnie Gray
在 chunks 关键字中提供字节大小 (dask#4434) Adam Beberg
为 histogram 的 bins 和 range 抛出更信息丰富的错误 (dask#4430) James Bourbeau
DataFrame¶
延迟注册更多 cudf 函数并移动到 backends 文件 (dask#4396) Matthew Rocklin
rearrange_by_column: 确保如果在 dask.config 中 shuffle arg 为 None,则默认为 'disk' (dask#4414) George Sakkis
实现 _read_pyarrow 的 filters (dask#4415) George Sakkis
避免在 is_dataframe_like 中检查类型 (dask#4418) Matthew Rocklin
使用 pyarrow 时将 username 作为 'user' 传递 (dask#4438) Roma Sokolov
Delayed¶
修复 DelayedAttr 返回值 (dask#4440) Matthew Rocklin
Documentation¶
使用 SVG 作为 pipeline 图形 (dask#4406) John A Kirkham
将 doctest-modules 添加到 py.test 文档中 (dask#4427) Daniel Severo
Core¶
解决 psutil 5.5.0 不允许 pickle Process 对象的限制 Janne Vuorela
1.1.0 / 2019-01-18¶
Array¶
修复存在 masked array 时的 average 函数 (dask#4236) Damien Garaud
为 hstack 和 vstack 添加 allow_unknown_chunksizes (dask#4287) Paul Vecchio
修复 27+ 维度的 tensordot (dask#4304) Johnnie Gray
修复带有 axes 的 block_info。 (dask#4301) Tom Augspurger
为 matmul 使用 safe_wraps (dask#4346) Mark Harfouche
在 array creation routines 中使用 chunks=”auto” (dask#4354) Matthew Rocklin
修复 dask.array.Array.__array_ufunc__ 中的 np.matmul (dask#4363) Stephan Hoyer
COMPAT:重新启用 multifield copy->view 更改 (dask#4357) Diane Trout
重写 normalize_array 以处理 numpy 数据 (dask#4312) Marco Neumann
DataFrame¶
为 series comparisons 添加 fill_value 支持 (dask#4250) James Bourbeau
在 read_sql_table 中为 empty tables 添加 schema name (dask#4268) Mina Farid
调整 map_blocks 中对 bad chunks 的检查 (dask#4308) Tom Augspurger
在 dask dataframe 中使用 atop fusion (dask#4229) Matthew Rocklin
在 from_pandas 中使用 parallel_types() (dask#4331) Matthew Rocklin
将 DataFrame._repr_data 更改为方法 (dask#4330) Matthew Rocklin
为 Appveyor 安装 pyarrow fastparquet (dask#4338) Gábor Lipták
移除显式的 pandas 检查并提供 cudf 延迟注册 (dask#4359) Matthew Rocklin
将 isinstance(…, pandas) 替换为 is_dataframe_like (dask#4375) Matthew Rocklin
ENH: 支持第三方 ExtensionArrays (dask#4379) Tom Augspurger
Pandas 0.24.0 兼容性 (dask#4374) Tom Augspurger
Documentation¶
修复 array api docs 中到 'map_blocks' 函数的链接 (dask#4258) David Hoese
校对文档 (dask#4267), (dask#4263), (dask#4262), (dask#4277), (dask#4271), (dask#4279), (dask#4265), (dask#4295), (dask#4293), (dask#4296), (dask#4302), (dask#4306), (dask#4318), (dask#4314), (dask#4309), (dask#4317), (dask#4326), (dask#4325), (dask#4322), (dask#4332), (dask#4333), Miguel Farrajota
文档:更新 array-api.rst (dask#4259) (dask#4282) Prabakaran Kumaresshan
更新 hpc 文档 (dask#4266) Guillaume Eynard-Bontemps
文档:在文档中将 from_avro 替换为 read_avro (dask#4313) Prabakaran Kumaresshan
移除文档中对 “get” scheduler 函数的引用 (dask#4350) Matthew Rocklin
修复文档字符串中的拼写错误 (dask#4376) Daniel Saxton
添加 dask.dataframe.merge 的文档 (dask#4382) Jendrik Jördening
Core¶
避免 dask.core.get 中的递归 (dask#4219) Matthew Rocklin
移除 pytest setup.cfg 中的 verbose flag (dask#4281) Matthew Rocklin
通过显式指定 marks 支持 Pytest 4.0 (dask#4280) Takahiro Kojima
添加 High Level Graphs (dask#4092) Matthew Rocklin
修复 SerializableLock 的 locked 和 acquire 方法 (dask#4294) Stephan Hoyer
在测试中将 boto3 锁定到早期版本以避免 moto 冲突 (dask#4276) Martin Durant
更新 config 时将 None 视为缺失值 (dask#4324) Matthew Rocklin
将 Appveyor 更新到 Python 3.6 (dask#4337) Gábor Lipták
在 dask.dataframe/bytes/bag 中更宽松地使用 parse_bytes (dask#4339) Matthew Rocklin
当缺少 cloudpickle 时添加更好的错误消息 (dask#4342) Mark Harfouche
在 threaded/multiprocessing get 函数中支持 pool= 关键字参数 (dask#4351) Matthew Rocklin
允许从 config.update 中的任意 Mappings 更新,而不仅仅是 dicts。 (dask#4356) Stuart Berg
将 dask/array/top.py 代码移动到 dask/blockwise.py (dask#4348) Matthew Rocklin
添加 has_parallel_type (dask#4395) Matthew Rocklin
CI: 更新 Appveyor (dask#4381) Tom Augspurger
1.0.0 / 2018-11-28¶
Array¶
添加 nancumsum/nancumprod 单元测试 (dask#4215) crusaderky
DataFrame¶
将 index 添加到 to_dask_dataframe 文档字符串 (dask#4232) James Bourbeau
使用 fastparquet 时处理和修复追加 categoricals 的问题 (dask#4245) Martin Durant
将 ParquetFile 传递给 read_parquet 时,不要重新读取元数据 (dask#4247) Martin Durant
Documentation¶
Core¶
避免一些警告 (dask#4223) Matthew Rocklin
移除 dask.store 模块 (dask#4221) Matthew Rocklin
移除 AUTHORS.md Jim Crist
0.20.2 / 2018-11-15¶
Array¶
避免 atop reductions 的 fusing 依赖项 (dask#4207) Matthew Rocklin
Dataframe¶
改进 dataframe 相关性的内存占用 (dask#4193) Damien Garaud
为 boundary_slice 添加空的 DataFrame 检查 (dask#4212) James Bourbeau
Documentation¶
校对文档 (dask#4197) (dask#4204) (dask#4198) (dask#4199) (dask#4200) (dask#4202) (dask#4209) Miguel Farrajota
添加 stats 模块命名空间 (dask#4206) James Bourbeau
修复 dataframe 文档中的链接 (dask#4208) James Bourbeau
0.20.1 / 2018-11-09¶
Array¶
仅在 wrapped_pad_func 中分配结果空间 (dask#4153) John A Kirkham
将 expand_pad_width 泛化为 expand_pad_value (dask#4150) John A Kirkham
使用 2D linear_ramp case 测试 da.pad (dask#4162) John A Kirkham
重写 Dask Array 的 pad 以仅添加新块 (dask#4152) John A Kirkham
验证 atop 的索引输入 (dask#4182) Matthew Rocklin
Core¶
Dask.config set 和 get 规范化下划线和连字符 (dask#4143) James Bourbeau
只在核心集合上进行 subs,而不是子类 (dask#4159) Matthew Rocklin
为 HTTPFileSystem 添加 block_size=0 选项。 (dask#4171) Martin Durant
为 dataclasses 添加 traverse 支持 (dask#4165) Armin Berres
避免在没有依赖项的 sharedicts 上进行优化 (dask#4181) Matthew Rocklin
更新 TravisCI 的 pytest 版本 (dask#4189) Damien Garaud
在 visualize names 中使用 key_split 而不是 funcname (dask#4160) Matthew Rocklin
Dataframe¶
为 DataFrame.__setitem__ 添加 index 修复 (dask#4151) Anderson Banihirwe
修复将文件列表传递给 fastparquet 时 column choice 问题 (dask#4174) Martin Durant
将 engine_kwargs 从 read_sql_table 传递给 sqlalchemy (dask#4187) Damien Garaud
Documentation¶
修复 Delayed 最佳实践示例中返回空列表的文档 (dask#4147) Jonathan Fraine
校对文档 (dask#4164) (dask#4175) (dask#4185) (dask#4192) (dask#4191) (dask#4190) (dask#4180) Miguel Farrajota
修复文档字符串中的拼写错误 (dask#4183) Carlos Valiente
0.20.0 / 2018-10-26¶
Array¶
Fuse Atop 操作 (dask#3998), (dask#4081) Matthew Rocklin
支持 dask dataframes 上的 da.asanyarray (dask#4080) Matthew Rocklin
移除 datetime 测试中不必要的 endianness 检查 (dask#4113) Elliott Sales de Andrade
在 array foo_like 函数中设置 name=False (dask#4116) Matthew Rocklin
移除 dask.array.ghost 模块 (dask#4121) Matthew Rocklin
修复 dask array 中 getargspec 的使用 (dask#4125) Stephan Hoyer
添加 dask.array.invert (dask#4127), (dask#4131) Anderson Banihirwe
在未知 chunksize 上进行 arg-reduction 时抛出信息丰富的错误 (dask#4128), (dask#4135) Matthew Rocklin
在 dask array 中规范化 reversed slices (dask#4126) Matthew Rocklin
Bag¶
添加 bag.to_avro (dask#4076) Martin Durant
Core¶
从 config.get 获取 num_workers (dask#4086), (dask#4093) James Bourbeau
修复带有 raw strings 的无效 escape sequences (dask#4112) Elliott Sales de Andrade
对使用 get= 关键字和 set_options 的情况抛出错误 (dask#4077) Matthew Rocklin
为 Azure DataLake storage 添加导入,并添加文档 (dask#4132) Martin Durant
避免 collections.Mapping/Sequence (dask#4138) Matthew Rocklin
Dataframe¶
在 to_dask_dataframe 中包含 index 关键字 (dask#4071) Matthew Rocklin
为 DataFrame 方法 sum 和 prod 实现 min_count (dask#4090) Bart Broere
移除 concat 中的 pandas 警告 (dask#4095) Matthew Rocklin
DataFrame.to_csv header 选项仅在第一个 chunk 输出 headers (dask#3909) Rahul Vaidya
移除 Series.to_parquet (dask#4104) Justin Dennison
避免 warnings 和 deprecated pandas methods (dask#4115) Matthew Rocklin
报告 append error 时交换 'old' 和 'previous' (dask#4130) Martin Durant
Documentation¶
校对文档 (dask#4073), (dask#4074), (dask#4094), (dask#4097), (dask#4107), (dask#4124), (dask#4133), (dask#4139) Miguel Farrajota
修复代码示例中的拼写错误 (dask#4089) Antonino Ingargiola
简要描述 gcsfs (dask#4109) Martin Durant
修复 read_sql_table 方法文档字符串中的拼写错误 (dask#4114) TakaakiFuruse
如果目标目录不存在,则在 redirects 中创建它们 (dask#4136) Matthew Rocklin
0.19.4 / 2018-10-09¶
Array¶
实现
apply_gufunc(..., axes=..., keepdims=...)(dask#3985) Markus Gonser
Bag¶
修复 datasets.make_people 中的拼写错误 (dask#4069) Matthew Rocklin
Dataframe¶
为 dask.dataframe.describe 方法添加了 percentiles 选项 (dask#4067) Zhenqing Li
添加与 Array.blocks 类似的 DataFrame.partitions accessor (dask#4066) Matthew Rocklin
Core¶
通过 scheduler 关键字传递 get functions 和 Clients (dask#4062) Matthew Rocklin
Documentation¶
修复 hpc 示例中的拼写错误 (kwarg 中缺少 =)。 (dask#4068) Matthias Bussonier
大量校对:(dask#4065), (dask#4064), (dask#4063) Miguel Farrajota
0.19.3 / 2018-10-05¶
Array¶
使 da.RandomState 可扩展到其他模块 (dask#4041) Matthew Rocklin
为 cupy 添加基本基础设施 (dask#4019) Matthew Rocklin
避免在 from_array(getitem) 中使用 asarray 和 lock 参数 (dask#4044) Matthew Rocklin
将 corrcoef 中的局部导入移动到全局导入 (dask#4030) John A Kirkham
将局部 indices 导入移动到全局导入 (dask#4029) John A Kirkham
修复 Dask Array 的 fromfunction 在 dtype 和 kwargs 方面的问题 (dask#4028) John A Kirkham
在 overlapped 中不要对 trim_internal 使用 dummy expansion (dask#3964) Mark Harfouche
添加 unravel_index (dask#3958) John A Kirkham
Bag¶
在 Bag.frequencies 中对结果进行排序 (dask#4033) Matthew Rocklin
在 groupby 中添加对 npartitions=1 边缘情况的支持 (dask#4050) James Bourbeau
添加新的随机 people 数据集 (dask#4018) Matthew Rocklin
提高 bag.read_text 在小文件上的性能 (dask#4013) Eric Wolak
添加 bag.read_avro (dask#4000) (dask#4007) Martin Durant
Dataframe¶
为
dask.dataframe.from_dask_array()添加了index参数,用于从给定的 index 创建 dask DataFrame。 (dask#3991) Tom Augspurger改进 dask dataframe 的子类化能力 (dask#4015) Matthew Rocklin
创建无需 prescan 即可读取多个 parquet 文件的路径 (dask#3978) Martin Durant
dd.from_dask_array 中的 Index (dask#3991) Tom Augspurger
使 skiprows 接受列表 (dask#3975) Julia Signell
fastparquet read 在不存在的 column 时尽早失败 (dask#3989) Martin Durant
Core¶
在 groupby 中添加对 npartitions=1 边缘情况的支持 (dask#4050) James Bourbeau
自动将 map_blocks/partitions 中的大参数用 dask.delayed 包裹 (dask#4002) Matthew Rocklin
使 multiprocessing context 可配置 (dask#3763) Itamar Turner-Trauring
Documentation¶
大量校对 (dask#4049), (dask#4034), (dask#4031), (dask#4020), (dask#4021), (dask#4022), (dask#4023), (dask#4016), (dask#4017), (dask#4010), (dask#3997), (dask#3996), Miguel Farrajota
更新 shuffle method selection 文档 (dask#4048) James Bourbeau
移除 docs/source/examples,指向 examples.dask.org (dask#4014) Matthew Rocklin
将 readthedocs 链接替换为 dask.org (dask#4008) Matthew Rocklin
更新 DataFrame.to_hdf 文档字符串以说明返回值 (dask#3992) James Bourbeau
0.19.2 / 2018-09-17¶
Array¶
apply_gufunc实现自动推断 functions 输出 dtypes (dask#3936) Markus Gonser修复当 array 包含 nans 时 array histogram range 错误 (dask#3980) James Bourbeau
from_array:添加 @martindurant 关于如何对 array 进行 hashing 的解释。 (dask#3965) Mark Harfouche
支持带 coordinate 的 gradient (dask#3949) Keisuke Fujii
Core¶
修复 Python 2.7 中使用 partial 的 has_keyword 问题 (dask#3966) Mark Harfouche
将 pyarrow 设置为 HDFS 的默认引擎 (dask#3957) Matthew Rocklin
Documentation¶
使用 dask_sphinx_theme (dask#3963) Matthew Rocklin
主页 Binder 链接使用 JupyterLab Matthew Rocklin
DOC: 修复 sphinx 语法 (dask#3960) Tom Augspurger
0.19.1 / 2018-09-06¶
Array¶
如果结果没有 dtype,则不强制 dtype (dask#3928) Matthew Rocklin
修复 NumPy issubtype 弃用警告 (dask#3939) Bruce Merry
修复 arg reduction tokens 以便在不同参数下保持唯一 (dask#3955) Tobias de Jong
Linalg.norm ndim along axis 部分修复 (dask#3933) Tobias de Jong
Dataframe¶
Deterministic DataFrame.set_index (dask#3867) George Sakkis
修复处理 filters 时 read_parquet 中的 divisions #3831 #3930 (dask#3923) (dask#3931) @andrethrill
修复 categorical.as_known 中的返回类型 (dask#3888) Sriharsha Hatwar
修复 DataFrame.assign 处理 callables 的问题 (dask#3919) Tom Augspurger
repartition 中包含没有宽度的 partitions (dask#3941) Matthew Rocklin
不要在 dataframe shuffle 中限制 stage/k dtype (dask#3942) Matthew Rocklin
Documentation¶
在主登陆页添加 try-now 按钮 (dask#3924) Matthew Rocklin
0.19.0 / 2018-08-29¶
Array¶
支持 gradient 中的 coordinate (dask#3949) Keisuke Fujii
修复 argtopk split_every bug (dask#3810) crusaderky
确保计算 dask.array.isnull() 的结果始终返回 numpy array (dask#3825) Stephan Hoyer
在 dask array 中支持 scipy.sparse 的 concatenate (dask#3836) Matthew Rocklin
修复 32 位系统上的 argtopk。 (dask#3823) Elliott Sales de Andrade
规范化 rechunk 中的 keys (dask#3820) Matthew Rocklin
允许 dask.array 的 shape 为 numpy array (dask#3844) Mark Harfouche
修复 tuple indexing 上的 numpy 弃用警告 (dask#3851) Tobias de Jong
将 ghost 模块重命名为 overlap (dask#3830) Robert Sare
确保 copy 保留 masked arrays (dask#3852) Tobias de Jong
DataFrame¶
为
dask.dataframe.get_dummies()添加了dtype和sparse关键字参数 (dask#3792) Tom Augspurger为
dask.array.asarray()更改了针对 dask dataframe 和 series 输入的行为。之前,series 会被急切地转换为内存中的 NumPy array,然后创建已知块大小的 dask array。这导致意外的高内存使用。现在,不再创建中间 NumPy array,而是返回未知块大小的 Dask array (dask#3884) Tom Augspurger改变了
dask.array.asarray()对于 dask 数据帧和 series 输入的行为。之前,series 会被急切地转换为内存中的 NumPy 数组,然后才创建块大小已知的 dask 数组。这导致了意外的高内存使用。现在,不创建中间 NumPy 数组,并返回块大小未知的 Dask 数组(dask#3884) Tom AugspurgerDataFrame.iloc (dask#3805) Tom Augspurger
读取多个路径时,扩展 globs。 (dask#3828) Irina Truong
resample 后添加 index column name (dask#3833) Eric Bonfadini
为 dataframe 和 series 添加 (lazy) shape 属性 (dask#3212) Henrique Ribeiro
为 diagnostics 重命名 to_csv keys (dask#3890) Matthew Rocklin
匹配 concat sort 的 pandas warnings (dask#3897) Tom Augspurger
read_csv 中包含 filename (dask#3908) Julia Signell
Core¶
缺少常见依赖项时提供更好的导入错误消息 (dask#3771) Danilo Horta
添加 DASK_ROOT_CONFIG 环境变量 (dask#3849) Joe Hamman
不在 local scheduler 中进行 cull,在 delayed 中进行 cull (dask#3856) Jim Crist
修复 Python 3.7.0 中 collections.abc 的 deprecation warnings (dask#3876) Jan Margeta
允许 visualize 测试中的 dot jpeg xfail (dask#3896) Matthew Rocklin
将 Python 3.7 添加到 travis.yml (dask#3894) Matthew Rocklin
将 expand_environment_variables 添加到 dask.config (dask#3893) Joe Hamman
Docs¶
修复 diagnostics 导入语句中的拼写错误 (dask#3826) John Mrziglod
修复登陆页 index.html 中小的拼写错误 (dask#3746) Christoph Moehl
更新 delayed-custom.rst (dask#3850) Anderson Banihirwe
DOC: 澄清 delayed 文档字符串 (dask#3709) Scott Sievert
将 dask array normalize_chunks 添加到文档 (dask#3878) Daniel Rothenberg
Docs: 修复到 snakeviz 的链接 (dask#3900) Hans Moritz Günther
0.18.2 / 2018-07-23¶
Array¶
重新实现了
argtopk以使其释放 GIL (dask#3610) crusaderky在
map_overlap中不要在非重叠维度上进行 overlap (dask#3653) Matthew Rocklin修复
linalg.tsqr处理长度不确定的维度的问题 (dask#3662) Jeremy Chen将 uneven array-of-int slicing 分解为单独的 chunks (dask#3648) Matthew Rocklin
将 auto chunks 对齐到 provided chunks,而不是 shape (dask#3679) Matthew Rocklin
添加 linspace 的 endpoint 和 retstep 支持 (dask#3675) James Bourbeau
实现
.blocksaccessor (dask#3689) Matthew Rocklin为
map_blocksfunctions 添加block_info关键字参数 (dask#3686) Matthew Rocklin通过 dask array of ints 进行切片 (dask#3407) crusaderky
支持
arange中的dtype(dask#3722) crusaderky修复 uneven chunks 的
argtopk问题 (dask#3720) crusaderky当
replace=False在da.choice中时引发错误(dask#3765) James Bourbeau更新
Array.__setitem__中的块(dask#3767) Itamar Turner-Trauring添加一个
chunksize便利属性(dask#3777) Jacob Tomlinson确保
to_zarr在使用return_storedTrue时返回一个 Dask 数组(dask#3786) John A Kirkham
Bag¶
在
to_textfiles中添加可选参数last_endline(dask#3745) George Sakkis
数据帧¶
为滚动对象添加聚合函数(dask#3772) Gerome Pistre
正确标记累积 groupby 聚合(dask#3799) Cloves Almeida
延迟对象¶
为延迟对象添加
@运算符(dask#3691) Mark Harfouche在文档中添加延迟对象最佳实践(dask#3737) Matthew Rocklin
核心¶
修复额外的进度条(dask#3669) Mike Neish
如果任务只有一个依赖项,则允许其返回排序堆栈(dask#3652) Matthew Rocklin
排序时优先处理依赖项数量较少的末端任务(dask#3588) Tom Augspurger
将
assert_eq添加到顶层模块(dask#3726) Matthew Rocklin测试 dask 集合可以容纳
scipy.sparse数组(dask#3738) Matthew Rocklin修复 lz4 解压函数的设置(dask#3782) Elliott Sales de Andrade
添加 datasets 模块(dask#3780) Matthew Rocklin
0.18.1 / 2018-06-22¶
数组¶
from_array现在支持输入中的标量类型和嵌套列表/元组,就像所有 numpy 函数一样;当输入是纯 ndarray 时,它还生成更简单的图(dask#3568) crusaderky修复由于 cumsum dtype 错误导致的大数组切片问题(dask#3620) Marco Rossi
添加 Dask 数组的 pad 实现(dask#3578) John A Kirkham
修复数组随机 API 示例(dask#3625) James Bourbeau
为 dask 数组添加平均函数(dask#3640) James Bourbeau
使用轴标记 ghost_internal(dask#3643) Matthew Rocklin
为 Dask 数组添加 outer(dask#3658) John A Kirkham
数据帧¶
添加 Index.to_series 方法(dask#3613) Henrique Ribeiro
修复 pyarrow-parquet 中缺失的分区列(dask#3636) Martin Durant
核心¶
对 CI 进行微调(dask#3629) Mike Neish
重新添加 dask.utils.effective_get(dask#3642) Matthew Rocklin
在 unpack_collections 中用唯一键替换 'collections' 键(dask#3632) Yu Feng
避免在 dask.config.set 中进行深拷贝(dask#3649) Matthew Rocklin
0.18.0 / 2018-06-14¶
数组¶
添加 Zarr 格式数据集和数组的 to/from_zarr(dask#3460) Martin Durant
实验性地添加了通用 ufunc 支持,包括
apply_gufunc、gufunc和as_gufunc(dask#3109)(dask#3526)(dask#3539) Markus Gonser避免不必要的 rechunking 任务(dask#3529) Matthew Rocklin
在运行时计算 fft 的 dtypes(dask#3511) Matthew Rocklin
为所有 da.store 操作生成 UUID(dask#3540) Martin Durant
修正 Dask 的 SVD 的内部维度(dask#3517) John A Kirkham
BUG: 不应因 array.vindex 中的 identity slice 引发 IndexError(dask#3559) Scott Sievert
添加了 isneginf 和 isposinf(dask#3581) John A Kirkham
删除 Dask 数组的 learn 模块(dask#3580) John A Kirkham
添加了 sfqr (short-and-fat) 作为 tsqr 的对应物…(dask#3575) Jeremy Chen
允许在 dask.array.rechunk 中使用宽度为 0 的块(dask#3591) Marc Pfister
在公共 API 中记录 Dask 数组的 nan_to_num(dask#3599) John A Kirkham
显示块示例(dask#3601) John A Kirkham
在 map_blocks 中用 name= 替换 token= 关键字(dask#3597) Matthew Rocklin
禁用 to_zarr 中的锁定(分布式环境中需要使用 to_zarr)(dask#3607) John A Kirkham
支持在 to_zarr/from_zarr 中使用 Zarr 数组(dask#3561) John A Kirkham
为 array/linalg/tsqr 添加递归以更好地管理单核瓶颈(dask#3586) Jeremy Chan(dask#3396) crusaderky
数据帧¶
添加 to/read_json(dask#3494) Martin Durant
为
DataFrame.rename方法不受支持的参数添加index(dask#3522) James Bourbeau添加了使用
numpy.ndarray、pandas.Series和pandas.Index对象子集 Dask 数据帧列的支持(dask#3536) James Bourbeau如果 meta 列与数据帧不匹配则引发错误(dask#3485) Christopher Ren
将 index 添加到 DataFrame.rename 不支持的参数中(dask#3522) James Bourbeau
添加了使用 pandas Index/Series 和 numpy ndarrays 对 DataFrames 进行子集的支持(dask#3536) James Bourbeau
数据帧 sample 方法 docstring 修复(dask#3566) James Bourbeau
为 sample 方法添加 n(dask#3606) James Bourbeau
添加 fastparquet ParquetFile 对象支持(dask#3573) @andrethrill
Bag¶
在 bag.groupby 中将 method= 关键字重命名为 shuffle=(dask#3470) Matthew Rocklin
核心¶
将 get= 关键字替换为 scheduler= 关键字(dask#3448) Matthew Rocklin
添加集中的 dask.config 模块来处理所有 Dask 子项目的配置(dask#3432)(dask#3513)(dask#3520) Matthew Rocklin
修复 HTTP 读取整个文件,无论是否有头部(dask#3496) Martin Durant
在调试文档中添加同步调度器语法(dask#3509) James Bourbeau
用 dask.config.set 替换 dask.set_options(dask#3502) Matthew Rocklin
更新 sphinx readthedocs 主题(dask#3516) Matthew Rocklin
为 normalize_chunks 引入“auto”值(dask#3507) Matthew Rocklin
修复 env=None 时配置中的检查(dask#3562) Simon Perkins
更新 sizeof 定义(dask#3582) Matthew Rocklin
从 travis-ci 中移除 –verbose 标志(dask#3477) Matthew Rocklin
从随机数组键中移除“da.random”(dask#3604) Matthew Rocklin
0.17.5 / 2018-05-16¶
数组¶
修复字典中 chunksize 为 -1 时的
rechunk(dask#3469) Stephan Hoyereinsum现在接受参数split_every(dask#3471) crusaderky
数据帧¶
与 pandas 0.23.0 的兼容性(dask#3499) Tom Augspurger
0.17.4 / 2018-05-03¶
数据帧¶
添加了使用字符串子类索引 Dask DataFrames 的支持(dask#3461) James Bourbeau
允许在 read_hdf 中同时使用 sorted_index 和 chunksize(dask#3463) Pierre Bartet
将文件系统传递给 arrow piece 读取器(dask#3466) Martin Durant
切换到使用 dask.compat string_types(dask#3462) James Bourbeau
0.17.3 / 2018-05-02¶
数组¶
为 Dask 数组添加
einsum(dask#3412) Simon Perkins为 Dask 数组添加
piecewise(dask#3350) John A Kirkham修复
broadcast_shapes中对nan的处理(dask#3356) John A Kirkham为 dask 数组添加
isin(dask#3363)。Stephan Hoyer大幅改进了 Dask 数组的
topk:更快的算法,特别适用于大型 k;添加了对多个轴、递归聚合的支持,以及选择底部 k 个元素的选项。(dask#3395) crusaderkytopkAPI 已从 topk(k, array) 更改为更传统的 topk(array, k)。传统 API 仍然可用,但现已弃用。(dask#2965) crusaderky为 Dask 数组添加新函数
argtopk(dask#3396) crusaderky修复
map_overlap中 partial depth 和 boundary 的处理(dask#3445) John A Kirkham为 Dask 数组添加
gradient(dask#3434) John A Kirkham
数据帧¶
允许在 to_hdf 中使用 t 作为 table 的简写,以兼容 pandas(dask#3330) Jörg Dietrich
为 Dask 数据帧添加了顶层方法 isna(dask#3294) Christopher Ren
修复
read_parquet中对engine="pyarrow"的分区列的选择(dask#3207) Uwe Korn添加了 DataFrame.squeeze 方法(dask#3366) Christopher Ren
为
read_parquet添加了 infer_divisions 选项,用于指定读取引擎是否应计算 divisions(dask#3387) Jon Mease为 meta= 错误提供更具信息性的错误消息(dask#3343) Matthew Rocklin
添加 orc 读取器(dask#3284) Martin Durant
parquet 的默认压缩现在始终是 Snappy,与 pandas 一致(dask#3373) Martin Durant
修复了 Dask DataFrame 和 Series 与 NumPy 标量比较时的错误(dask#3436) James Bourbeau
从 repartition docstring 中移除过时的要求(dask#3440) Jörg Dietrich
修复了仅选择 Series 时聚合中的错误(dask#3446) Jörg Dietrich
为 make_timeseries 添加默认值(dask#3421) Matthew Rocklin
核心¶
支持在 persist, visualize 和 optimize 中遍历集合(dask#3410) Jim Crist
为 compute 和 persist 添加 schedule= 关键字。这取代了 get= 关键字的常见用法(dask#3448) Matthew Rocklin
0.17.2 / 2018-03-21¶
数组¶
为 Dask 数组添加
broadcast_arrays(dask#3217) John A Kirkham添加
bitwise_*ufuncs(dask#3219) John A Kirkham为
squeeze添加可选参数axis(dask#3261) John A Kirkham验证 atop 的输入(dask#3307) Matthew Rocklin
如果所有部分具有相同的 dtype,则避免在 concatenate 中调用 astype(dask#3301) Martin Durant
数据帧¶
修复由于过度截断导致的 shuffle 中的错误(dask#3201) Matthew Rocklin
支持在
read_parquet中使用categories=[…]为engine="pyarrow"指定分类列(dask#3177) Uwe Korn添加
dd.tseries.Resampler.agg(dask#3202) Richard Postelnik支持数据帧和数组混合操作(dask#3230) Matthew Rocklin
在
dd.groupby._Groupby.apply中支持额外的 Scalar 和 Delayed 参数(dask#3256) Gabriele Lanaro
Bag¶
支持连接单分区 bag 和延迟对象(dask#3254) Matthew Rocklin
核心¶
修复使用意外但可哈希类型作为键时的错误(dask#3238) Daniel Collins
修复任务排序错误,以便我们根据键名一致地打破平局(dask#3271) Matthew Rocklin
当任务数量非常大时,避免按顺序排序任务(dask#3298) Matthew Rocklin
0.17.1 / 2018-02-22¶
数组¶
修正了 indices 中的维度分块(dask#3166, dask#3167) Simon Perkins
为
store的return_stored选项内联store_chunk调用(dask#3153) John A Kirkham与 NumPy 1.14.1 版本中 struct dtypes 的兼容性(dask#3187) Matthew Rocklin
数据帧¶
错误修复以允许分配 pandas 日期时间列(dask#3164) Max Epstein
核心¶
新的 HTTP(S) 文件系统,允许直接从特定 URL 加载(dask#3160) Martin Durant
修复在标记没有关键字的偏函数时出现的错误(dask#3191) Matthew Rocklin
使用更新的 LZ4 API(dask#3157) Thrasibule
为进度条引入输出流参数(dask#3185) Dieter Weber
0.17.0 / 2018-02-09¶
数组¶
添加了对 nansum, nanmin 和 nanmax 的对象类型数组的支持(dask#3133) Keisuke Fujii
更新 len 调用空块时的错误处理(dask#3058) Xander Johnson
修复
store的return_stored选项导致的元数据错误(dask#3064) John A Kirkham修复
optimization.fuse_slice中的错误,以正确处理第一个输入为None的情况(dask#3076) James Bourbeau支持在 percentile 中使用块大小未知的数组(dask#3107) Matthew Rocklin
标记 scipy.sparse 数组和 np.matrix(dask#3060) Roman Yurchak
数据帧¶
在 repartition(freq=…) 中支持月 timedeltas(dask#3110) Matthew Rocklin
避免在数据帧 groupby 测试中发生变动(dask#3118) Matthew Rocklin
read_csv、read_table和read_parquet接受路径的可迭代对象(dask#3124) Jim Crist当 UDF 返回 numpy 数组时,从 df.map_partitions 调用返回 dask.arrays(dask#3147) Matthew Rocklin
更改
columns和index在dd.read_parquet中的处理方式,使其更一致,尤其是在处理多索引时(dask#3149) Jim Cristfastparquet append=True 允许创建新数据集(dask#3097) Martin Durant
sql 查询的 dtype 合理化(dask#3100) Martin Durant
核心¶
更改默认任务排序,优先选择依赖项较少的节点,然后是许多下游依赖项(dask#3056) Matthew Rocklin
为 visualize 添加 color= 选项,以按任务顺序着色(dask#3057)(dask#3122) Matthew Rocklin
添加
dask.base.optimize,用于在不计算的情况下优化多个集合。(dask#3071) Jim Crist将
dask.optimize模块重命名为dask.optimization(dask#3071) Jim Crist更改任务排序以进行完整遍历(dask#3066) Matthew Rocklin
为所有
to_delayed方法添加optimize_graph关键字,以控制转换时是否进行优化。(dask#3126) Jim Crist
0.16.1 / 2018-01-09¶
数组¶
修复
percentile中标量百分位值的处理(dask#3021) James Bourbeau防止
bool()强制转换调用 compute(dask#2958) Albert DeFusco添加
matmul(dask#2904) John A Kirkham支持具有
matmul的 N-D 数组(dask#2909) John A Kirkham添加
vdot(dask#2910) John A Kirkham为
broadcast_to添加显式参数chunks(dask#2943) Stephan Hoyer添加
meshgrid(dask#2938) John A Kirkham 和(dask#3001) Markus Gonser在
fftshift/ifftshift中保留单例块(dask#2733) John A Kirkham修复
vindex中负索引的处理,并为越界索引引发错误(dask#2967) Stephan Hoyer添加
flip、flipud、fliplr(dask#2954) John A Kirkham添加
float_powerufunc(dask#2962)(dask#2969) John A Kirkham与即将发布的 NumPy 1.14 版本中对结构化数组的更改的兼容性(dask#2964) Tom Augspurger
添加
block(dask#2650) John A Kirkham为
store添加return_stored选项,用于链式存储结果(dask#2980) John A Kirkham
数据帧¶
修复累积聚合中的命名错误(dask#3037) Martijn Arts
修复当给出
names但未将header设置为None时的dd.read_csv(dask#2976) Martijn Arts修复
dd.read_csv,以便在dtype中传递CategoricalDtype的实例将导致已知分类(dask#2997) Tom Augspurger防止
bool()强制转换调用 compute(dask#2958) Albert DeFuscoDataFrame.read_sql()(dask#2928)到一个空数据库表返回一个空的 dask 数据帧 Apostolos Vlachopoulos与读取由 PyArrow 0.8.0 写入的 Parquet 文件的兼容性(dask#2973) Tom Augspurger
在
dd.read_parquet中读取时,正确处理列名(df.columns.name)(dask#2973) Tom Augspurger修复当数据包含分类时
dd.concat丢失索引 dtype 的问题(dask#2932) Tom Augspurger移除了已弃用的
dd.rolling*方法,为在下一个 pandas 版本中移除它们做准备(dask#2995) Tom Augspurger
核心¶
改进 32 位兼容性 (dask#2937) Matthew Rocklin
更改任务优先级以避免向上分支 (dask#3017) Matthew Rocklin
0.16.0 / 2017-11-17¶
这是一个主要版本。它包含了破坏性变更、新协议和大量错误修复。
数组¶
添加
atleast_1d、atleast_2d和atleast_3d(dask#2760) (dask#2765) John A Kirkham添加
allclose(dask#2771) by John A Kirkham从 Dask Array API 文档中移除
random.different_seeds(dask#2772) John A Kirkham弃用
vnorm,推荐使用dask.array.linalg.norm(dask#2773) John A Kirkham重新实现
unique以支持惰性计算 (dask#2775) John A Kirkham支持具有 0 长度维度的 Dask Arrays 的广播 (dask#2784) John A Kirkham
将
asarray和asanyarray添加到 Dask Array API 文档中 (dask#2787) James Bourbeau支持
unique的return_*参数 (dask#2779) John A Kirkham简化
_unique_internal(dask#2850) (dask#2855) John A Kirkham
DataFrame¶
修复了当存在缺失值时,
DataFrame.quantile和Series.quantile返回nan的问题 (dask#2791) Tom Augspurger修复了当
q是标量时,DataFrame.quantile丢失结果.name的问题 (dask#2791) Tom Augspurger修复了当沿列连接单个 Series 时,
dd.concat返回dask.Dataframe的问题,与 pandas 的行为一致 (dask#2800) James Munroe修复了
DataFrame.eval的默认 inplace 参数,使其与 pandas >= 0.21.0 的 pandas 默认行为一致 (dask#2838) Tom Augspurger修复了在文本列上调用
DataFrame.set_index时,如果其中一个分区为空,会引发异常的问题 (dask#2831) Jesse Vogt在空 dataframe 上调用
DataFrame.set_index时不再引发异常 (dask#2827) Jesse Vogt修复了使用
Series值填充时,Dataframe.fillna中的错误 (dask#2810) Tom Augspurger弃用
dd.to_parquet中旧的参数顺序,以更好地匹配将 dataframe 放在前面的约定 (dask#2867) Jim Crist根据 Pandas 发布候选版本进行测试 (dask#2814) Tom Augspurger
为 read_parquet(engine=’pyarrow’) 添加更多测试 (dask#2822) Uwe Korn
移除 aggregate 中不必要的 map_partitions (dask#2712) Christopher Prohm
在
dd.to_parquet中支持使用pyarrow读取/写入 hdfs (dask#2894, dask#2881) Jim Crist
核心¶
允许使用元组作为 sharedict 键 (dask#2763) Matthew Rocklin
在 dask.distributed 任务中调用 compute 默认使用分布式调度器 (dask#2762) Matthew Rocklin
使用 gcs:// 协议时自动导入 gcsfs (dask#2776) Matthew Rocklin
完全移除 dask.async 模块,改为使用 dask.local (dask#2828) Thomas Caswell
与 bokeh 0.12.10 的兼容性 (dask#2844) Tom Augspurger
在 XArray 集成期间更新 Dask collection 接口 (dask#2847) Matthew Rocklin
修复文档中 bokeh dashboard 的端口 (dask#2889) Ian Hopkinson
0.15.3 / 2017-09-24¶
数组¶
添加掩码数组 (dask#2301)
添加
*_like array creation functions数组创建函数 (dask#2640)使用无符号整数数组进行索引 (dask#2647)
改进了使用不同维度的布尔数组进行切片 (dask#2658)
在
top和atop中支持字面值 (dask#2661)累积函数中的可选 axis 参数 (dask#2664)
使用
assert_eq改进对标量的测试 (dask#2681)修复 norm keepdims (dask#2683)
添加
ptp(dask#2691)添加 apply_along_axis (dask#2690) 和 apply_over_axes (dask#2702)
DataFrame¶
0.15.2 / 2017-08-25¶
数组¶
DataFrame¶
0.15.1 / 2017-07-08¶
0.14.2 / 2017-05-03¶
数组¶
添加 da.indices (dask#2268), da.tile (dask#2153), da.roll (dask#2135)
在 da.map_blocks 中同时支持 drop_axis 和 new_axis (dask#2264)
支持非 numpy 容器数组,特别是稀疏数组 (dask#2234)
Tensordot 在多个轴上进行收缩 (dask#2186)
在 da.store 中允许使用 delayed 目标 (dask#2181)
支持与列表和元组的交互 (dask#2148)
用于调试的构造函数插件 (dask#2142)
多维 FFT(单块) (dask#2116)
DataFrame¶
0.13.0 / 2017-01-02¶
数组¶
DataFrame¶
添加
map_overlap用于自定义滚动操作 (dask#1769)添加
shift(dask#1773)添加 Parquet 支持 (dask#1782) (dask#1792) (dask#1810), (dask#1843), (dask#1859), (dask#1863)
添加缺失的方法:combine, abs, autocorr, sem, nsmallest, first, last, prod, (dask#1787)
具有多个输出分区的归约(用于像 drop_duplicates 这样的操作)(dask#1808), (dask#1823) (dask#1828)
为 DataFrames 添加 delitem 和 copy,增强变动支持 (dask#1858)
Delayed¶
更改了
delayed(nout=0)和delayed(nout=1)的行为:delayed(nout=1)不再默认out=None,并且启用了delayed(nout=0)。也就是说,返回长度为 1 或 0 的元组的函数可以正确处理。这对于通过delayed包装具有可变数量输出的函数特别方便。例如,一个简单的例子:delayed(lambda *args: args, nout=len(vals))(*vals)
0.12.0 / 2016-11-03¶
DataFrame¶
当提供给
dataframe.map_partitions的函数返回标量时,返回一个 series (dask#1515)修复 series 的类型大小推断问题 (dask#1513)
dataframe.DataFrame.categorize不再在categories中包含缺失值。这是为了兼容 pandas 的一个变更 pandas change (dask#1565)修复
dataframe.read_csv中当某些行包含引号时出现的头部解析器错误 (dask#1495)添加
dataframe.reduction和series.reduction方法,用于对 dataframes 和 series 应用通用的行级归约 (dask#1483)添加
dataframe.select_dtypes,它镜像了 pandas 的方法 pandas method (dask#1556)dataframe.read_hdf现在支持读取Series(dask#1564)支持 Pandas 0.19.0 (dask#1540)
实现
select_dtypes(dask#1556)String accessor 支持索引 (dask#1561)
为 dask.dataframe 添加 pipe 方法 (dask#1567)
为 merge 添加
indicator关键字 (dask#1575)在
read_hdf中支持 Series (dask#1575)支持包含缺失值的 Categories (dask#1578)
支持像
df.x += 1这样的 inplace 运算符 (dask#1585)Str accessor 透传 args 和 kwargs (dask#1621)
改进了单机多进程调度器的 groupby 支持 (dask#1625)
树状归约 (dask#1663)
数据透视表 (dask#1665)
添加 clip (dask#1667), align (dask#1668), combine_first (dask#1725), 以及 any/all (dask#1724)
改进了 dask-pandas 合并中分区信息的处理 (dask#1666)
添加
groupby.aggregate方法 (dask#1678)添加
dd.read_table函数 (dask#1682)在
loc中支持 2d 索引 (dask#1726)扩展
resample以包含 DataFrames (dask#1741)在 dask.dataframe 对象上支持 dask.array ufuncs (dask#1669)
数组¶
添加关于
dask.array的chunks参数如何工作的说明 (dask#1504)修复
dask.array中非标量字段的字段访问问题 (dask#1484)在 atop 中添加 concatenate= 关键字以连接收缩维度的块
扩展
atop,添加concatenate=(dask#1609)、new_axes=(dask#1612) 和adjust_chunks=(dask#1716) 关键字添加 clip (dask#1610) swapaxes (dask#1611) round (dask#1708) repeat
在
atop支持的操作中自动对齐块 (dask#1644)在切片时剔除 dask.arrays (dask#1709)
管理¶
添加了更新日志 (dask#1526)
从线程操作时创建新的线程池 (dask#1487)
将示例文档页面合并为一个 (dask#1520)
添加 versioneer 以支持基于 git commit 的版本 (dask#1569)
在 dot 可视化中透传 node_attr 和 edge_attr 关键字 (dask#1614)
添加使用 Appveyor 在 Windows 上进行持续测试 (dask#1648)
移除 multiprocessing.Manager 的使用 (dask#1653)
为 compute 添加全局优化关键字 (dask#1675)
微优化 get_dependencies (dask#1722)
0.11.0 / 2016-08-24¶
主要亮点¶
DataFrames 现在在任何地方都强制要求知道完整的元数据(列、dtypes)。以前,当函数丢失 dtype 信息(如 apply)时,我们会在模糊状态下操作。现在,所有 dataframe 总是知道它们的 dtypes,并且如果无法推断(通常可以推断),则会引发错误要求提供信息。一些内部属性,如 _pd 和 _pd_nonempty,已被移动。
分布式调度器的内部已重构,以在显式状态之间转换任务。这提高了弹性、调度推理、插件操作和日志记录。这也使得调度器代码对于新手更容易理解。
破坏性变更¶
distributed.s3和distributed.hdfs命名空间已移除。请改在常规方法中使用协议,例如read_text('s3://...'。Dask.array.reshape现在在某些情况下会报错,而以前它会创建大量任务
0.10.2 / 2016-07-27¶
更多 Dataframe shuffle 现在可以在分布式设置中工作,从设置索引到哈希连接,再到排序连接和 groupbys。
Dask 在 Python 优化-OO 模式下运行时通过了完整的测试套件。
发现在某些高并发场景(特别是在 Windows 上)中,磁盘 shuffle 会产生错误结果。这已通过修复 partd 库得到解决。
修复了在大数据通信下发生的打开文件描述符增长问题
在 dask-scheduler 的
--bokeh-whitelist选项中支持指定端口,以便在复杂的网络设置后更好地路由 web 界面消息对 worker 故障的弹性进行了一些改进(尽管其他已知故障仍然存在)
您现在可以在任何 worker 上启动 IPython 内核,以便改进调试和分析
对
dask.dataframe.read_hdf的改进,特别是在从多个文件和文档读取时
0.10.0 / 2016-06-13¶
主要变更¶
此版本放弃了对 Python 2.6 的支持
Conda 包从 conda-forge 构建和提供
dask.distributed可执行文件已从 dfoo 重命名为 dask-foo。例如,dscheduler 已重命名为 dask-schedulerBag 和 DataFrame 都包含初步的分布式 shuffle。
Bag¶
为分布式 groupbys 添加基于任务的 shuffle
添加 accumulate 用于累积归约
DataFrame¶
添加适用于分布式连接、groupby-apply 和 set_index 操作的基于任务的 shuffle。单机 shuffle 保持不变(且效率更高)。
添加对新的 Pandas rolling API 的支持,提高了在分布式系统上的通信性能。
添加
groupby.std/var在
read_csv中透传 S3/HDFS 存储选项改进分类分区
为 dataframes 添加 eval, info, isnull, notnull
分布式¶
将 dscheduler 等可执行文件重命名为 dask-scheduler
改进调度器在许多快速任务情况下的性能(对 shuffling 很重要)
改进工作窃取,使其能够感知预期的函数运行时间和数据大小。这极大地增加了无需大量用户专业知识即可在分布式调度器上高效运行的算法范围。
支持流队列中的最大缓冲区大小
改进使用 Bokeh 诊断 web 界面时的 Windows 支持
支持协议中对超大字节字符串的压缩
支持在 Joblib 界面中干净地取消提交的 futures
其他¶
所有与 dask 相关的项目(dask, distributed, s3fs, hdfs, partd)现在都在 conda-forge 上构建 conda 包。
更改 s3fs 中的凭据处理方式,仅在明确给出密钥/键时传递委托凭据。现在的默认行为是依赖托管环境。可以通过明确提供关键字参数来改回。如果需要匿名模式,必须明确声明。
0.9.0 / 2016-05-11¶
API 变更¶
dask.do和dask.value已重命名为dask.delayeddask.bag.from_filenames已重命名为dask.bag.read_text所有 S3/HDFS 数据摄取函数,如
db.from_s3或distributed.s3.read_csv,已移至普通的read_text、read_csv functions函数中,这些函数现在支持协议,例如dd.read_csv('s3://bucket/keys*.csv')
数组¶
添加对
scipy.LinearOperator的支持改进对磁盘数据结构的Optional locking
更改 rechunk 以暴露中间块
Bag¶
将
from_filenames 重命名为read_text移除
from_s3,推荐使用read_text('s3://...')
DataFrame¶
修复了相关性和协方差的数值稳定性问题
允许使用无哈希的
from_pandas,以实现与 pandas 对象的快速往返总体上重新设计了
read_csv,使其更符合 Pandas 的行为支持对已排序列进行快速
set_index操作
Delayed¶
将
do/value重命名为delayed将
to/from_imperative重命名为to/from_delayed
分布式¶
将 s3 和 hdfs 功能移入 dask 仓库
自适应地超额分配 worker 以处理非常快速的任务
改进 PyPy 支持
改进非均衡 worker 的工作窃取
使用树状 scatter 高效地分散数据
其他¶
添加 lzma/xz 压缩支持
尝试分割不可分割的压缩类型(如 gzip 或 bz2)时发出警告
改进单机 shuffle 操作的哈希计算
为 start 状态添加新的回调方法
通用性能调优
0.8.1 / 2016-03-11¶
数组¶
修复了范围切片中可能定期导致错误结果的错误。
改进了
arg归约(argmin、argmax等)的支持和弹性
Bag¶
添加
zip函数
DataFrame¶
添加
corr和cov函数添加
melt函数bcolz 和 hdf5 的 I/O 错误修复
0.8.0 / 2016-02-20¶
数组¶
将默认数组归约分割从 32 更改为 4
线性代数,
tril、triu、LU、inv、cholesky、solve、solve_triangular、eye、lstsq、diag、corrcoef。
Bag¶
添加树状归约
添加 range 函数
移除
from_hdfs函数(hdfs3 和 distributed 项目中现在提供了更好的功能)
DataFrame¶
重构
dask.dataframe,使其包含一个完整的空 pandas dataframe 作为元数据。移除 Series 上的.columns属性添加 Series 分类访问器,series.nunique,移除 series 的
.columns属性。read_csv修复(多列 parse_dates、整数列名等)改进图序列化的内部变更
其他¶
文档更新
为所有 collection 添加 from_imperative 和 to_imperative 函数
profiler 图表的美学更改
将 dask 项目移至新的 dask 组织下
0.7.6 / 2016-01-05¶
数组¶
改进线程安全
树状归约
添加
view、compress、hstack、dstack、vstack方法map_blocks现在可以移除和添加维度
DataFrame¶
改进线程安全
扩展采样以包含替换选项
命令式¶
移除融合结果的优化过程。
核心¶
移除
dask.distributed提高了分块文件读取的性能
序列化改进
测试 Python 3.5
0.7.4 / 2015-10-23¶
这主要是一个错误修复版本。一些值得注意的更改
修复与 numpy 1.10 和 pandas 0.17 发布相关的细微错误
修复了随机数生成中的一个错误,该错误会导致由于生日悖论而产生重复块
在
dask.dataframe.read_hdf中默认使用锁,以避免并发问题将
dask.get默认指向dask.async.get_sync允许可视化函数接受通用的 graphviz 图选项,如 rankdir=’LR’
将 reshape 和 ravel 添加到
dask.array支持从
dask.imperative对象创建dask.arrays
弃用¶
此版本还包含对 dask.distributed 的弃用警告,该模块将在下一版本中移除。
dask 分布式计算的未来开发正在这里进行:https://distributed.dask.org.cn 。非常欢迎社区对此项目提出反馈。
0.7.3 / 2015-09-25¶
诊断¶
一个用于分析内存和 CPU 使用的实用工具已添加到
dask.diagnostics模块中。
DataFrame¶
此版本改进了对 pandas API 的覆盖。其中包括 nunique、nlargest、quantile 等功能。修复了读取非 ascii csv 文件时的编码问题。改进了 resample 的性能并修复了错误。read_hdf 支持更灵活的 globbing。还有更多改进。修复了 dask.imperative 和 dask.bag 中的各种错误。
0.7.0 / 2015-08-15¶
DataFrame¶
此版本包含了重要的错误修复,并与 Pandas API 对齐。这得益于实际使用以及 Pandas 核心开发者的近期参与。
新操作:query, rolling operations, drop
改进的操作:quantiles, 对整个 dataframes 进行算术运算, dropna, 构造函数逻辑, merge/join, 逐元素操作, groupby 聚合
Bag¶
修复了 fold 中使用 null 默认参数时的错误
数组¶
新操作:da.fft 模块, da.image.imread
基础设施¶
array 和 dataframe collection 创建的图具有确定性键。这些键通常较长(哈希字符串),但在不同计算之间应该是一致的。这在将来对于缓存很有用。
所有 collection(Array, Bag, DataFrame)都继承自共同的子类
0.6.1 / 2015-07-23¶
分布式¶
改进了(尽管尚未足够)当 worker 死亡时
dask.distributed的弹性
DataFrame¶
改进了写入各种格式的功能,包括 to_hdf, to_castra, 和 to_csv
改进了从 dask Arrays 和 Bags 创建 dask DataFrames 的功能
改进了对 categoricals 和各种其他方法的支持
数组¶
各种错误修复
Histogram 函数
调度¶
在并行工作负载中添加了任务的打破平局排序,以便更好地处理和清除中间结果
其他¶
添加了 dask.do 函数,用于使用普通 python 代码显式构造图
将 pydot 替换为 graphviz 库用于图打印,以支持 Python3
还有一个 gitter 聊天室和一个 stackoverflow 标签