块
目录
块¶
Dask 数组由许多 NumPy(或类似 NumPy)数组组成。这些数组的排列方式会显著影响性能。例如,对于一个方阵,你可以按行、按列或以更接近方形的方式排列你的块。不同的 NumPy 数组排列方式对于不同的算法会有不同的速度表现。
考虑和控制分块对于优化高级算法非常重要。
指定块形状¶
我们总是通过指定 chunks 参数来告诉 dask.array 如何将底层数组分解成块。我们可以通过多种方式指定 chunks
一个统一的维度大小,例如
1000,表示每个维度中的块大小为1000一个统一的块形状,例如
(1000, 2000, 3000),表示第一个轴的块大小为1000,第二个轴为2000,第三个轴为3000完全显式指定所有维度上所有块的大小,例如
((1000, 1000, 500), (400, 400), (5, 5, 5, 5, 5))一个字典,指定每个维度的块大小,例如
{0: 1000, 1: 2000, 2: 3000}。这只是上面形式 2 和 3 的另一种写法
你的 chunks 输入将被规范化并存储为第三种最显式的形式。请注意,chunks 代表“块形状”而不是“块的数量”,因此指定 chunks=1 意味着你将拥有许多块,每个块恰好包含一个元素。
为了获得性能,chunks 的一个好的选择遵循以下规则
一个块应该足够小,以便能轻松地放入内存。我们将同时在内存中存放许多块
一个块必须足够大,以便在该块上的计算时间显著长于 Dask 调度产生的每个任务 1 毫秒的开销。一个任务的执行时间应超过 100 毫秒
块大小通常在 10MB 到 1GB 之间,具体取决于可用 RAM 和计算持续时间
块应该与你要进行的计算对齐。
例如,如果你计划经常沿特定维度进行切片,那么如果你的块对齐,以便触及更少的块,效率会更高。如果你想添加两个数组,那么如果这些数组具有匹配的块模式,会很方便
如果适用,块应该与你的存储对齐。
数组数据格式也通常是分块的。加载或保存数据时,如果 Dask 数组块与你的存储分块对齐,通常每个方向上的大小是其偶数倍,这将非常有用
在 Genevieve Buckley 的文章 在 Dask 中选择合适的块大小 中了解更多。
未知块¶
有些数组具有未知的块大小。当数组的大小取决于尚未执行的惰性计算时,就会出现这种情况,如下所示
>>> rng = np.random.default_rng()
>>> x = da.from_array(rng.standard_normal(100), chunks=20)
>>> x += 0.1
>>> y = x[x > 0] # don't know how many values are greater than 0 ahead of time
上述操作会导致形状和块大小未知的数组。形状或块内的未知值使用 np.nan 表示,而不是整数。这些数组支持许多(但不是所有)操作。特别是,切片等操作是不可能的,会导致错误。
>>> y.shape
(np.nan,)
>>> y[4]
...
ValueError: Array chunk sizes unknown
A possible solution: https://docs.dask.org.cn/en/latest/array-chunks.html#unknown-chunks.
Summary: to compute chunks sizes, use
x.compute_chunk_sizes() # for Dask Array
ddf.to_dask_array(lengths=True) # for Dask DataFrame ddf
使用 compute_chunk_sizes() 可以运行此示例
>>> y.compute_chunk_sizes()
dask.array<..., chunksize=(19,), ...>
>>> y.shape
(44,)
>>> y[4].compute()
0.78621774046566
请注意,compute_chunk_sizes() 会立即执行计算并就地修改数组。
使用 Dask DataFrame 创建 Dask 数组时,也会出现未知的块大小
>>> ddf = dask.dataframe.from_pandas(...)
>>> ddf.to_dask_array()
dask.array<..., shape=(nan, 2), ..., chunksize=(nan, 2)>
使用 to_dask_array() 可以解决此问题
>>> ddf.to_dask_array(lengths=True)
dask.array<..., shape=(100, 2), ..., chunksize=(20, 2)>
关于 to_dask_array() 的更多详细信息,请参阅Dask 数组创建文档中关于如何从 Dask DataFrame 创建 Dask 数组的部分。
块示例¶
在此示例中,我们展示了 chunks= 的不同输入如何切割以下数组
1 2 3 4 5 6
7 8 9 0 1 2
3 4 5 6 7 8
9 0 1 2 3 4
5 6 7 8 9 0
1 2 3 4 5 6
在这里,我们展示了不同的 chunks= 参数如何将数组分割成不同的块
chunks=3: 大小为 3 的对称块
1 2 3 4 5 6
7 8 9 0 1 2
3 4 5 6 7 8
9 0 1 2 3 4
5 6 7 8 9 0
1 2 3 4 5 6
chunks=2: 大小为 2 的对称块
1 2 3 4 5 6
7 8 9 0 1 2
3 4 5 6 7 8
9 0 1 2 3 4
5 6 7 8 9 0
1 2 3 4 5 6
chunks=(3, 2): 大小为 (3, 2) 的不对称但重复的块
1 2 3 4 5 6
7 8 9 0 1 2
3 4 5 6 7 8
9 0 1 2 3 4
5 6 7 8 9 0
1 2 3 4 5 6
chunks=(1, 6): 大小为 (1, 6) 的不对称但重复的块
1 2 3 4 5 6
7 8 9 0 1 2
3 4 5 6 7 8
9 0 1 2 3 4
5 6 7 8 9 0
1 2 3 4 5 6
chunks=((2, 4), (3, 3)): 不对称且不重复的块
1 2 3 4 5 6
7 8 9 0 1 2
3 4 5 6 7 8
9 0 1 2 3 4
5 6 7 8 9 0
1 2 3 4 5 6
chunks=((2, 2, 1, 1), (3, 2, 1)): 不对称且不重复的块
1 2 3 4 5 6
7 8 9 0 1 2
3 4 5 6 7 8
9 0 1 2 3 4
5 6 7 8 9 0
1 2 3 4 5 6
讨论
后者的示例很少由用户直接在原始数据上提供,而是由复杂的切片和广播操作产生。通常人们会使用最简单的形式,直到需要更复杂的形式。块的选择应与您想要进行的计算对齐。
例如,如果您计划沿着第一个维度取出细薄的切片,那么您可能希望使该维度比其他维度更窄。如果您计划进行线性代数运算,那么您可能希望使用更对称的块。
加载分块数据¶
现代 NDArray 存储格式如 HDF5、NetCDF、TIFF 和 Zarr,允许数组以块或瓦片的形式存储,以便可以高效地取出数据块,而无需遍历线性数据流。最好将你的 Dask 数组块与底层数据存储的块对齐。
然而,数据存储通常比 Dask 数组的理想分块更细,因此通常选择一个块大小是你存储块大小的倍数的分块方式,否则可能会产生较高的开销。
例如,如果你正在加载一个以 (100, 100) 大小分块的数据存储,那么你可能会选择像 (1000, 2000) 这样更大的块,但它仍然可以被 (100, 100) 整除。数据存储技术能够告诉你他们的数据是如何分块的。
重新分块¶
|
为新的块转换 Dask 数组 x 中的块。 |
有时您需要更改数据分块的布局。例如,您的数据可能是按行分块的,但您需要执行一项按列操作会快得多的运算。您可以使用 rechunk 方法更改分块。
x = x.rechunk((50, 1000))
跨轴重新分块可能代价高昂并产生大量通信,但 Dask 数组拥有相当高效的算法来完成此操作。
注意:rechunk 方法要求输出数组与输入数组具有相同的形状,并且不支持重塑。在使用 rechunk 之前,务必确保所需的输出形状与输入形状匹配。
您可以向 rechunk 传递任何有效的块形式
x = x.rechunk(1000)
x = x.rechunk((50, 1000))
x = x.rechunk({0: 50, 1: 1000})
重塑¶
dask.array.reshape() 的效率在很大程度上取决于输入数组的分块方式。在重塑操作中,存在“快速移动”或“高”轴的概念。对于一个二维数组,第二个轴(axis=1)是移动最快的,其次是第一个。这意味着如果我们画一条线来表示值的填充方式,我们会先横向移动穿过“列”(沿着 axis=1),然后向下移动到下一行。考虑 np.ones((3, 4)).reshape(12)
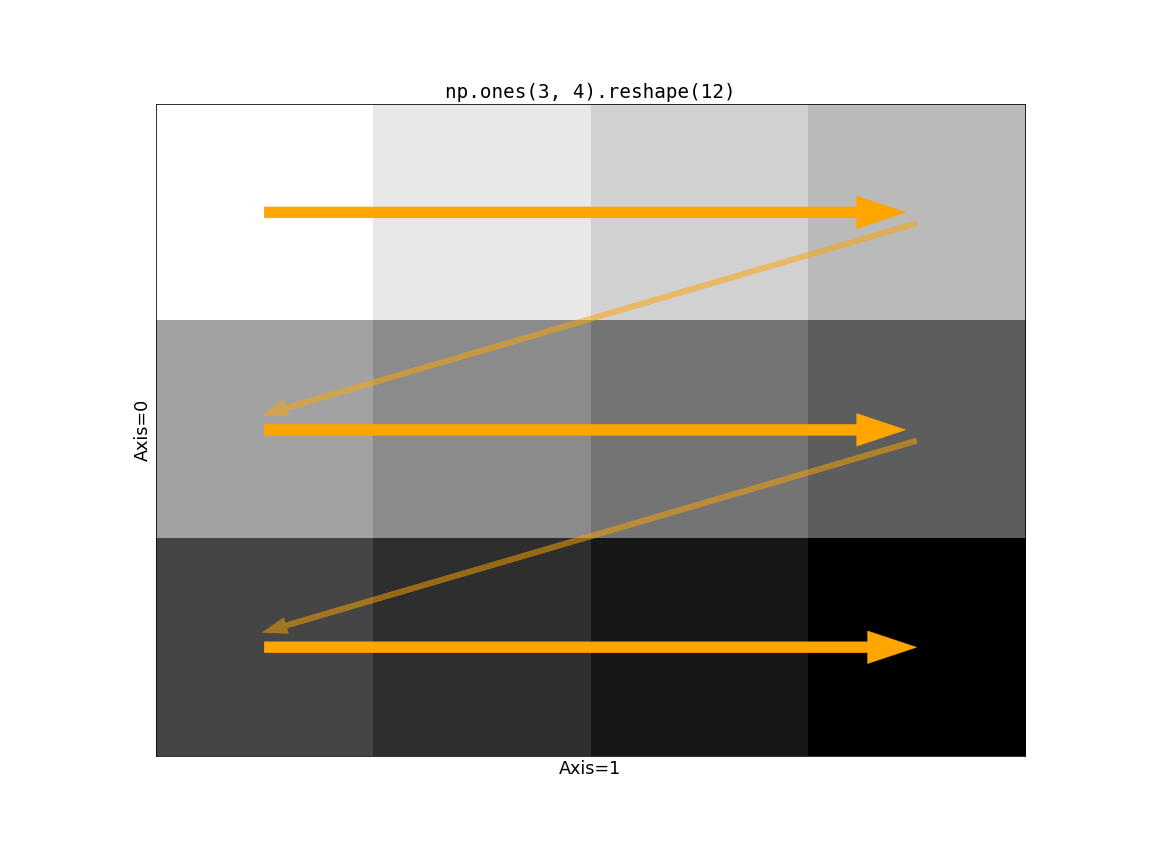
现在考虑 Dask 的分块对这个操作的影响。如果慢速移动轴(在这种情况下只是 axis=0)的块大小大于 1,我们就会遇到问题。

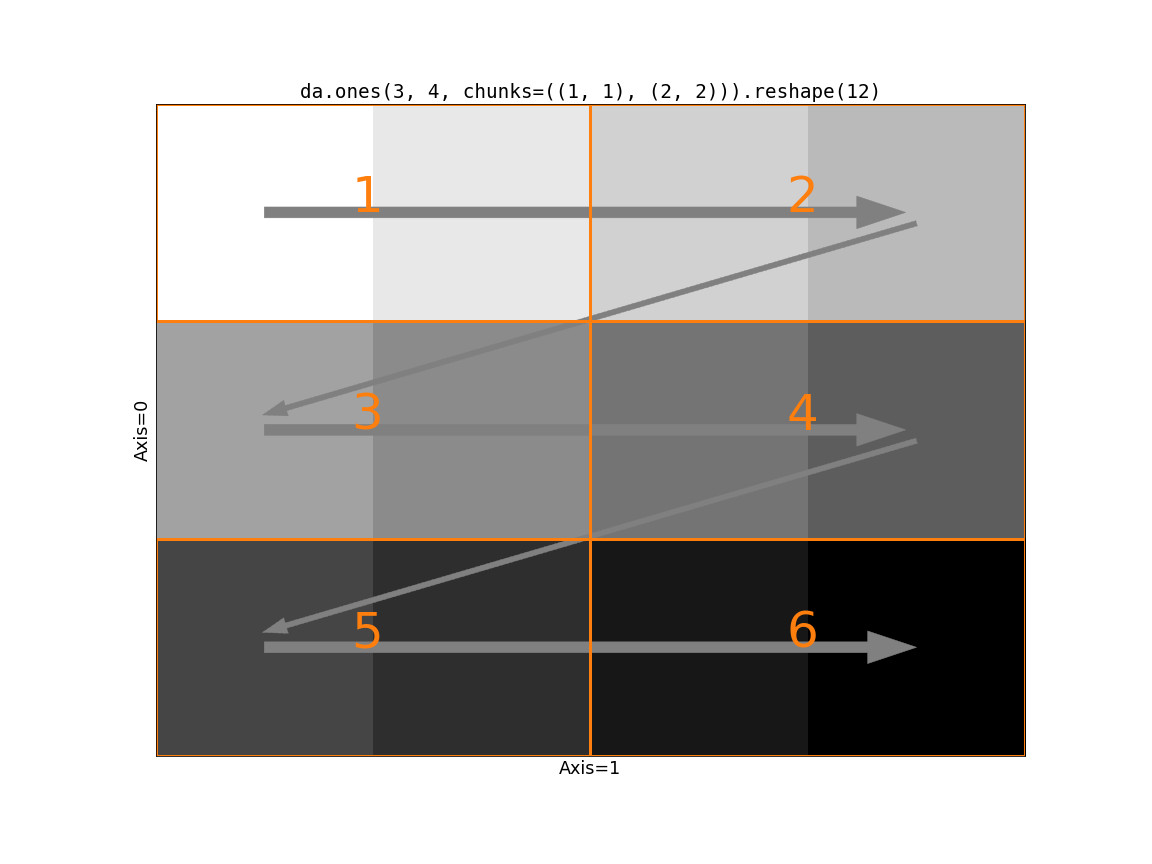
第一个块的形状是 (2, 2)。按照 reshape 的规则,我们取出块 1 的第一行中的两个值。但随后我们跨越了一个块边界(从 1 到 2),而此时第一个块中仍有两个“未使用”的值。没有办法将输入块与输出形状对齐。我们需要以某种方式重新分块输入使其与输出形状兼容。我们有两种选择
使用
dask.array.rechunk()中的逻辑合并块。这可以避免产生过多的任务/块,但会增加一些通信和较大的中间结果。这是默认行为。使用
da.reshape(x, shape, merge_chunks=False)通过分割输入来避免合并块。特别是,我们可以将所有慢速移动轴重新分块,使其块大小为 1。这可以避免通信和大量数据的移动,但代价是任务图变大(可能大很多,因为慢速移动轴上的块数将等于这些轴的长度)。
从视觉上看,这是第二种选择
这两种方法哪种更好取决于你的问题。如果通信非常昂贵且数据沿慢速移动轴相对较小,那么 merge_chunks=False 可能更好。让我们比较一下将一个 3 维数组重塑为 2 维,且输入数组在慢速移动轴上没有 chunksize=1 的问题上这两种方法的任务图。
>>> a = da.from_array(np.arange(24).reshape(2, 3, 4), chunks=((2,), (2, 1), (2, 2)))
>>> a
dask.array<array, shape=(2, 3, 4), dtype=int64, chunksize=(2, 2, 2), chunktype=numpy.ndarray>
>>> a.reshape(6, 4).visualize()
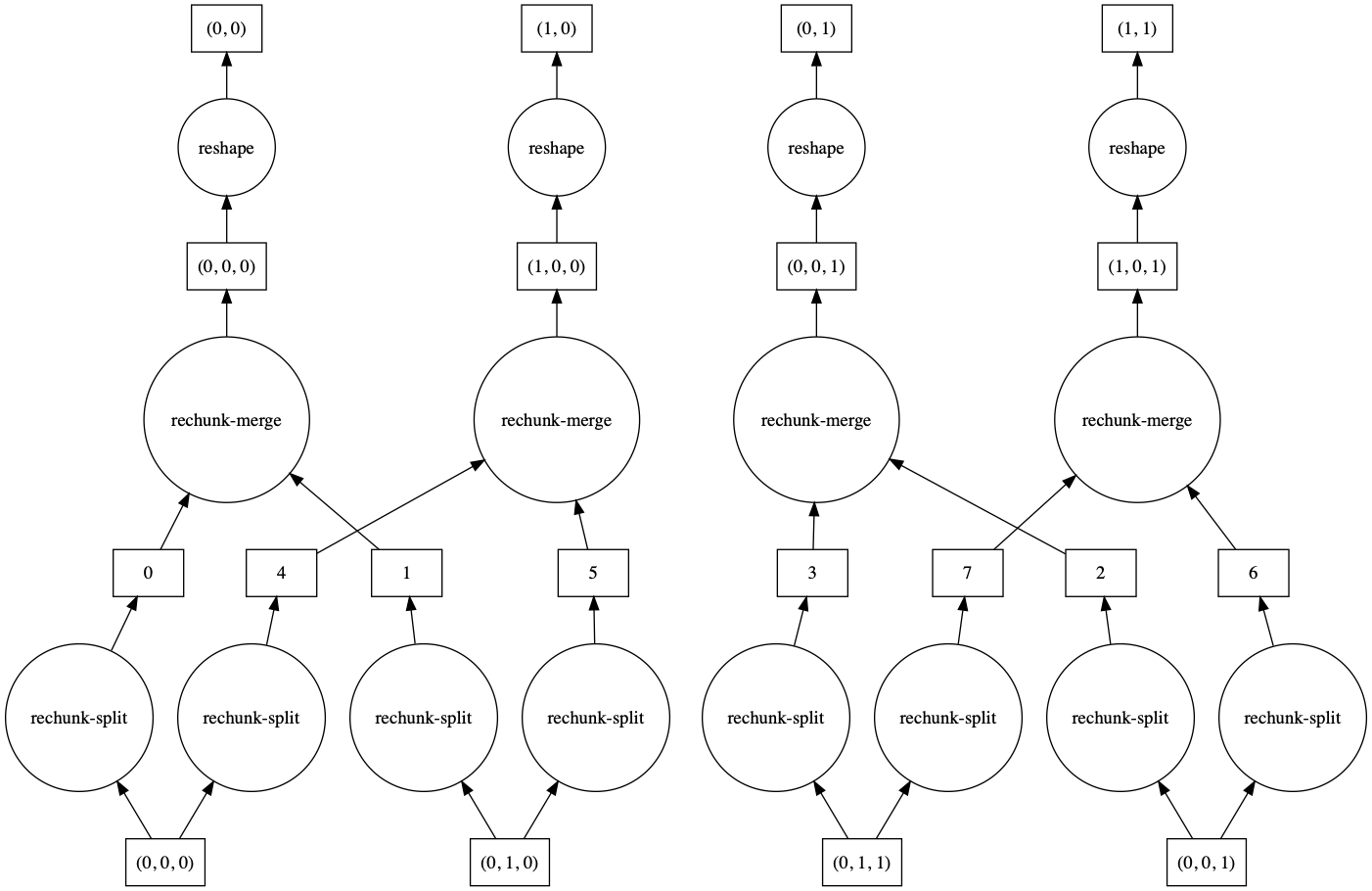
>>> a.reshape(6, 4, merge_chunks=False).visualize()
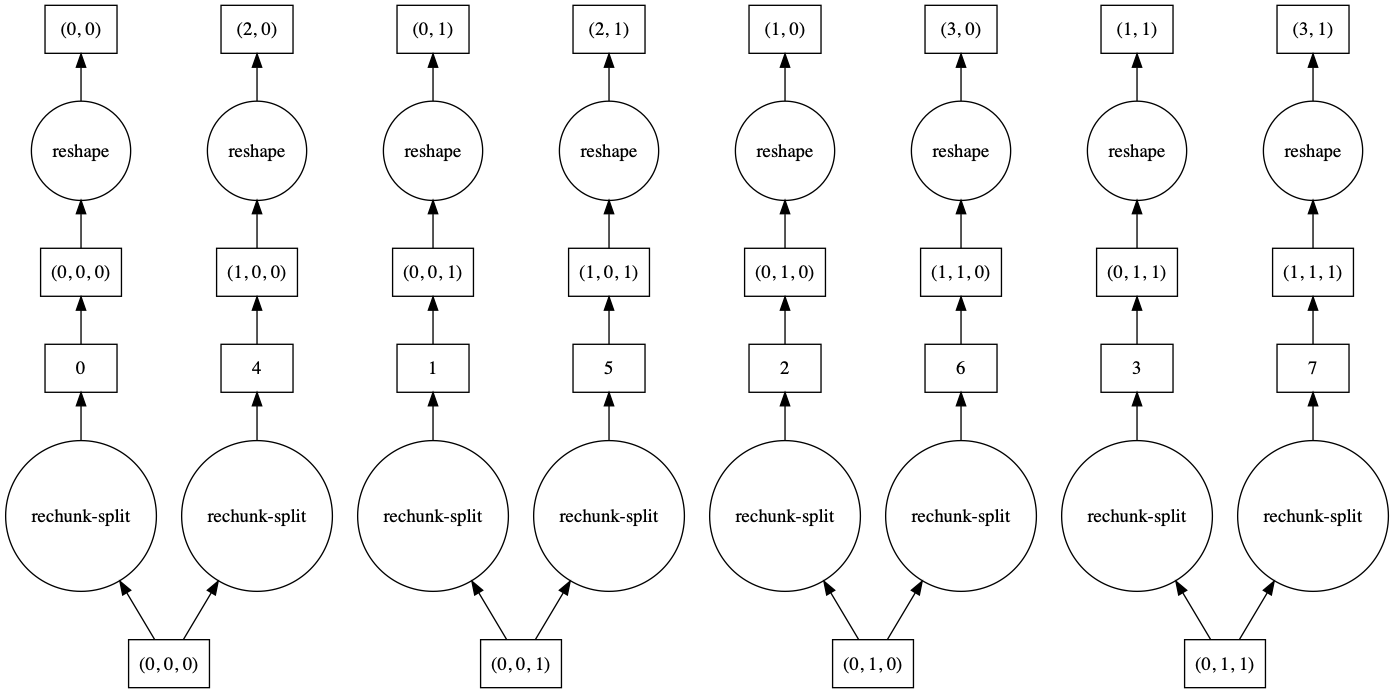
默认情况下,一些中间块会被合并,导致任务图更复杂。使用 merge_chunks=False 时,我们会分割输入块(导致总体任务增多,具体取决于数组大小)但避免后续通信。
自动分块¶
块还包括三个特殊值
-1: 沿此维度不分块None: 沿此维度不改变分块(对重新分块有用)"auto": 允许沿此维度自动调整分块以适应理想的块大小
因此,例如,可以将一个 3D 数组重新分块,使其沿第零维度不分块,但仍然具有合理的块大小,如下所示
x = x.rechunk({0: -1, 1: 'auto', 2: 'auto'})
或者可以允许所有维度自动调整大小以获得好的块大小
x = x.rechunk('auto')
自动分块会扩展或收缩所有标记为 "auto" 的维度,试图达到字节数等于配置值 array.chunk-size 的块大小,该值默认为 128MiB,您可以在配置中更改此值。
>>> dask.config.get('array.chunk-size')
'128MiB'
自动重新分块会尽量尊重自动调整大小维度的中位块形状,但会修改此形状以适应完整数组的形状(块大小不能大于数组本身)并找到能完美划分数组形状的块形状。
这些值也可用于创建数组的操作,例如 dask.array.ones 或 dask.array.from_array
>>> dask.array.ones((10000, 10000), chunks=(-1, 'auto'))
dask.array<wrapped, shape=(10000, 10000), dtype=float64, chunksize=(10000, 1250), chunktype=numpy.ndarray>