排序
目录
排序¶
注意
这是一个高级主题,大多数用户无需担心。
当 Dask 获得一个任务图进行计算时,它需要选择一个执行任务的顺序。我们有一些约束:依赖项必须在其依赖者之前执行。但除此之外,还有很大的选择空间。我们希望 Dask 选择一个既能最大限度地提高并行度,又能最大限度地减少运行计算所需占用的资源的排序。
从宏观上看,Dask 的策略是朝着 小目标 迈出 大步。
小目标:优先处理总依赖者少、且最终依赖者总依赖项少的任务。
我们倾向于优先处理有助于快速完成计算分支的任务。
更详细地说,我们计算每个任务依赖的总依赖项数量(包括其自身的依赖项、其依赖项的依赖项等等),然后选择那些总依赖项数量少、有助于得出结果的任务。我们选择优先处理那些有助于先完成较短计算的任务。
大步:优先处理有许多依赖者的任务
然而,许多任务都指向相同的最终依赖者。在这些任务中,我们选择那些剩余工作量最大的任务。我们希望在开始较小的部分之前完成一个子计算中较大的部分。
这是通过 dask.order.order() 完成的。更技术性的讨论可在 深度调度 中找到。 https://distributed.dask.org.cn/en/latest/scheduling-policies.html 也讨论了调度,侧重于分布式调度器,其中包含此处记录的静态排序之外的额外选择。
调试¶
大多数时候,Dask 的排序效果很好。但这确实是一个难题,有时您可能会观察到意外高的内存使用量或通信量,这可能是由于排序不当造成的。本节描述了如何识别排序问题,以及可以采取的一些缓解步骤。
考虑一个计算,它独立地从磁盘加载多条数据链,将它们的片段堆叠在一起,然后进行一些归约操作
>>> # create data on disk
>>> import dask.array as da
>>> x = da.zeros((12500, 10000), chunks=('10MB', -1))
>>> da.to_zarr(x, 'saved_x1.zarr', overwrite=True)
>>> da.to_zarr(x, 'saved_y1.zarr', overwrite=True)
>>> da.to_zarr(x, 'saved_x2.zarr', overwrite=True)
>>> da.to_zarr(x, 'saved_y2.zarr', overwrite=True)
我们可以加载数据
>>> # load the data.
>>> x1 = da.from_zarr('saved_x1.zarr')
>>> y1 = da.from_zarr('saved_x2.zarr')
>>> x2 = da.from_zarr('saved_y1.zarr')
>>> y2 = da.from_zarr('saved_y2.zarr')
并对其进行一些计算
>>> def evaluate(x1, y1, x2, y2):
... u = da.stack([x1, y1])
... v = da.stack([x2, y2])
... components = [u, v, u ** 2 + v ** 2]
... return [
... abs(c[0] - c[1]).mean(axis=-1)
... for c in components
... ]
>>> results = evaluate(x1, y1, x2, y2)
您可以使用 dask.visualize() 并结合 color="order" 来可视化包含静态排序作为节点标签的任务图。像使用 dask.visualize 的常规做法一样,您可能需要将问题缩小到较小的规模,所以我们将切出一部分数据。请确保包含 optimize_graph=True 以获得任务实际执行顺序的真实表示。
>>> import dask
>>> n = 125 * 4
>>> dask.visualize(evaluate(x1[:n], y1[:n], x2[:n], y2[:n]),
... optimize_graph=True, color="order",
... cmap="autumn", node_attr={"penwidth": "4"})
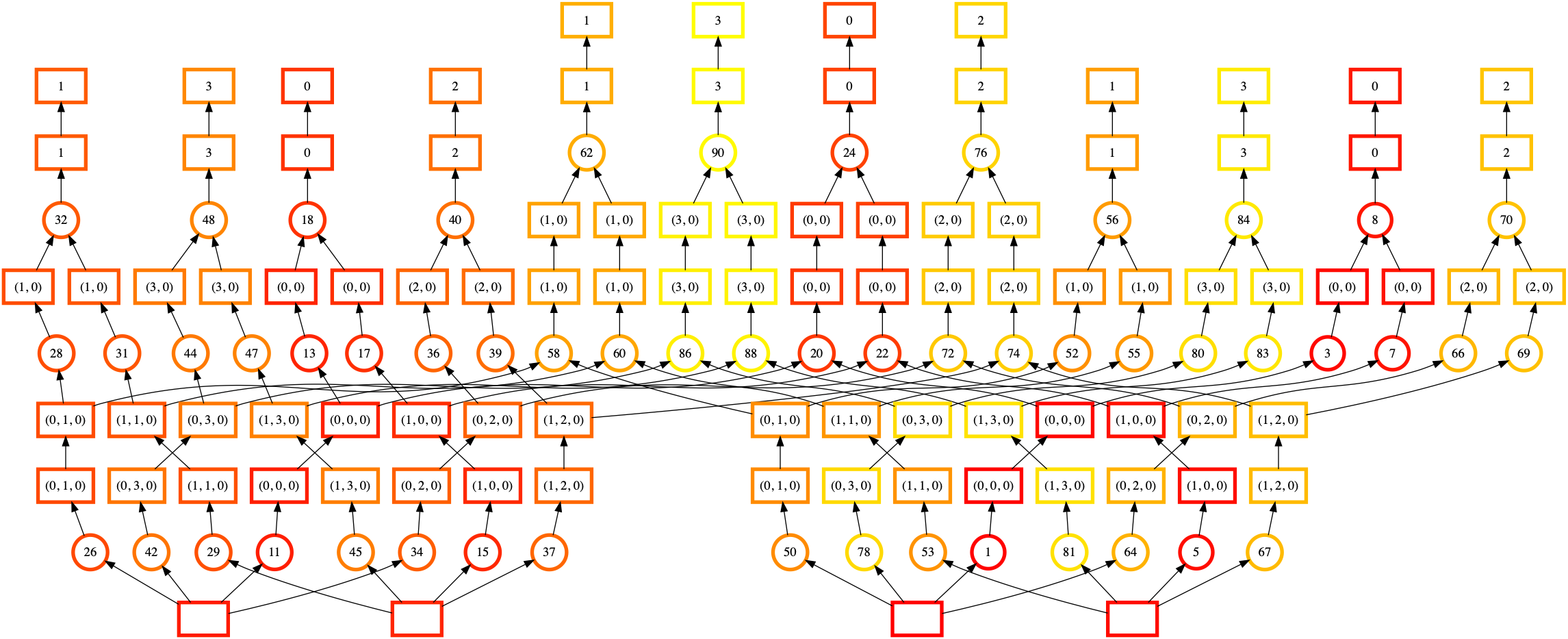
在这个可视化中,节点按执行顺序(从深红色到浅黄色)着色,节点标签是 Dask 分配给每个任务的顺序。
虽然有点难看清,但这里实际上有四个基本独立的执行“塔”。我们从右中部的数组(标签 1,底部)开始,向上移到右边(标签 8,右上部),然后跳到完全不同的数组(标签 11,左下部)。然而,计算第一个塔(标签 8 的下游,右上部)需要从我们的第二个输入数组(标签 5,右下部)加载一些数据。我们更倾向于完成其下游的任务。
当 Dask 执行该任务图时,您可能会观察到较高的内存使用量。糟糕的静态排序意味着我们未能完成那些允许我们释放数据片段的任务。我们一次将更多片段加载到内存中,从而导致更高的内存使用量。
这种特定的排序失败(可能已修复)源于每个计算链底部的共享依赖项(每个任务底部的框,代表输入的 Zarr 数组)。我们可以将这些内联,看看排序的效果
>>> # load and profile data
>>> x1 = da.from_zarr('saved_x1.zarr', inline_array=True)
>>> y1 = da.from_zarr('saved_x2.zarr', inline_array=True)
>>> x2 = da.from_zarr('saved_y1.zarr', inline_array=True)
>>> y2 = da.from_zarr('saved_y2.zarr', inline_array=True)
>>> import dask
>>> n = 125 * 4
>>> dask.visualize(evaluate(x1[:n], y1[:n], x2[:n], y2[:n]),
... optimize_graph=True, color="order",
... cmap="autumn", node_attr={"penwidth": "4"})
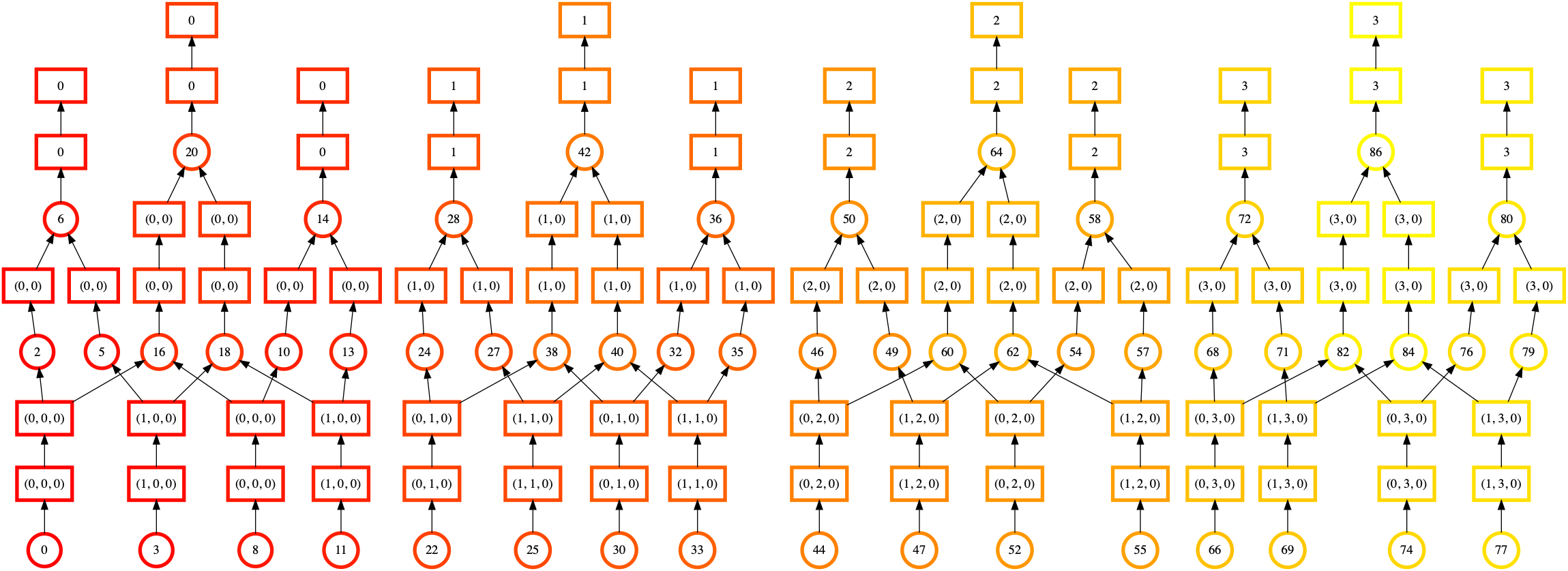
一眼望去,我们可以看到这种排序看起来更加规律和均匀。交叉的线条更少,并且排序的颜色从下到上、从左到右平滑过渡。这表明 Dask 在开始下一个计算链之前正在完成一个计算链。
这里的教训不是“总是使用 inline_array=True”。虽然静态排序看起来更好,但还有其他 计算阶段 需要考虑。实际性能是否更好将取决于比我们在此考虑的更多因素。更多信息请参阅 dask.array.from_array()。
相反,这里的要点是
哪些症状可能导致您诊断 Dask 的排序存在问题(例如高内存使用量)
如何生成和读取包含 Dask 排序信息的任务图。