优化器
目录
优化器¶
注意
Dask DataFrame 从版本 2024.03.0 开始支持查询规划
优化步骤¶
Dask DataFrame 在执行计算之前会运行多个优化。这些优化旨在提高查询的效率。
这些优化包括以下步骤(此列表不完整)
投影下推
在每个步骤中只选择必需的列。这减少了需要从存储中读取的数据量,同时也减少了处理过程中的数据量。在查询的最早阶段就丢弃不需要的列。
过滤下推
尽可能地将过滤器下推,甚至推到 IO 步骤。过滤器在查询的最早阶段执行。
分区剪枝
分区选择尽可能地下推,甚至推到 IO 步骤。
避免数据混洗 (Shuffle)
Dask DataFrame 会尽量避免在工作进程之间进行数据混洗 (shuffling)。如果列的布局已知(例如 DataFrame 之前已在同一列上进行过混洗),则可以实现这一点。例如,如果在合并操作后执行
df.groupby(...).apply(...),并且 groupby 操作发生在合并列上,则不会再次混洗数据。
类似地,在相同的 join 列上执行两次连续的 Join/Merge 操作将避免再次混洗数据。优化器会识别出 DataFrame 的分区已经符合预期,因此将操作简化为一次 Shuffle 和一次简单的合并操作。¶
自动调整分区大小
IO 层会根据从数据集中选择的列子集自动调整分区数量。非常小的分区会对调度器和昂贵的混洗操作产生负面影响。这通过自动调整分区数量来解决。

选择总大小为 40 MB(对应每个 200 MB 文件)的两列。优化器将分区数量减少了 5 倍。¶
探索优化后的查询¶
Dask 在执行计算之前会调用 df.optimize()。此方法应用上述步骤,并返回一个表示优化后查询的新 Dask DataFrame。
通过调用 df.pprint() 可以获得优化后查询的基本表示。这会将查询计划以人类可读的格式打印到命令行/控制台。此方法的优点是它不需要任何额外的依赖项。
pdf = pd.DataFrame({"a": [1, 2, 3] * 5, "b": [1, 2, 3] * 5})
df = dd.from_pandas(pdf, npartitions=2)
df = df.replace(1, 5)[["a"]]
df.optimize().pprint()
Replace: to_replace=1 value=5
FromPandas: frame='<pandas>' npartitions=2 columns=['a'] pyarrow_strings_enabled=True
通过调用 df.explain() 可以获得更高级、更容易阅读的表示。此方法需要安装 graphviz 包。该方法将返回表示查询计划的图,并从中创建一个图像。
df.explain()
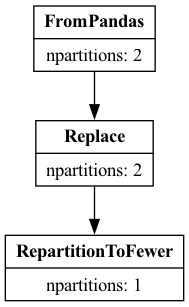
在两种表示中,我们都可以看到 FromPandas 应用了列投影,只选择了列 a。
对于更复杂的查询,explain() 方法更容易理解。